秒杀系统高并发优化
通过该篇文章可以学习到:
————————————————————————————————
1 高并发系统优化思路分析
2 高并发优化技巧
动静态资源分离:CDN(内容发布网络):缓存静态资源
Redis:缓存动态资源
并发优化:
SQL优化降低行级锁持有时间
存储过程优化降低行级锁持有时间
3 集群化部署————————————————————————————————
源码参照:并发系统源码
1 优化分析
结合该高并发系统考虑,哪些是可能出现的高并发点呢?
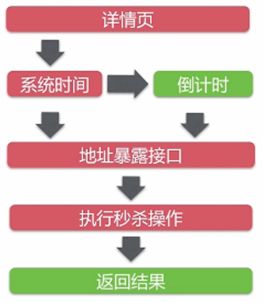
上图中,所有的红色的部分都可能是出现高并发的点。
1.1为什么单独获取系统时间
在详情页,可能出现用户大量的刷新情况,此时系统应该部署在CDN节点上,此时要做一个静态化处理,当再次刷新时它获取的CDN静态资源(css/js/picture),但是,时间要保持实时的,所以要单独的做一个处理,单独从服务器系统上获取时间,这也就是为什么要在详情页单独获取系统时间了。
1.2 CDN是什么
简介:CDN(内容发布网络),是一个加速用户获取数据的系统;既可以是静态资源,又可以是动态资源,这取决于我们的决策策略。经常大部分视频加速都依赖于CDN,比如优酷,爱奇艺等,据此加速;
原理:CDN部署在距离用户最近的网络节点上,用户上网的时候通过网络运营商(电信,长城等)访问距离用户最近的要给城域网网络地址节点上,然后通过城域网跳到主干网上,主干网则根据访问IP找到访问资源所在服务器,但是,很大一部分内容在上一层节点已经找到,此时不用往下继续查找,直接返回所访问的资源即可,减小了服务器的负担。一般互联网公司都会建立自己的CDN机群或者租用CDN。
1.3 获取系统时间不用优化
获取系统访问时间的操作不用优化,因为访问一次内存Cacheline大约10ns,1秒内可以做很大数据量级的时间获取操作,所以,不用做什么优化!
1.4 秒杀地址(Redis缓存技术)
对于秒杀地址暴露的接口是否可以缓存呢?
秒杀接口是无法缓存在CDN当中的,因为CDN适合缓存不易变化的资源,通常是静态资源,比如css/jquery资源,每一个url对应了一个不变的内容,秒杀的接口地址是在每次都发生变化的,不适合放在CDN缓存。
但是适合放在服务器端做缓存(后端缓存),比如redis等,下一次访问的时候直接去服务器端缓存里面查找,如果服务器端缓存有了就直接拿走,没有的话再做正常数据访问处理;另外一个原因就是,一致性维护成本很低。
秒杀地址接口的优化策略:
请求地址,先访问redis,如果redis缓存中没有所需资源或者访问访问超时,则直接进入mysql获取系统资源,将获取的内容更新在redis当中(策略:超时穿透,主动更新)。
1.5 秒杀操作
1.5.1 秒杀操作分析
(a)秒杀操作优化分析
对于这种写操作,是无法使用CDN优化的,另外,也不适合在后端缓存,因为缓存了其他数据,可能会出现数据不一致的情况。
秒杀数据数据操作的一个困难的点就是一行数据大量用户出现竞争的情况,同时出现大量的(b)update操作,这样该如何优化呢?
(架构+维护点)
设计一个原子计数器(redis/NoSQL来实现)用来记录行为信息(用分布式MQ实现这个消息队列,即把消息放在MQ当中),然后后端服务消费此消息并落地(用Mysql实现,落地:记录购买者,能够扛着很大的访问量)
但是这个而技术的有自己的弱点,也就是成本方面:
运维成本和稳定型:NoSQL,MQ等;开发成本在数据一致性和回滚方案等;幂等性难以保证:重复秒杀的问题;不适合新手的架构。
(c)为什么不用MySql来解决秒杀操作?
因为Mysql执行update的减库存比较低效,一条update操作的压力测试结果是可以抗住4wQPS,也就是说,一个商品在1秒内,可以被买4w次;
看一下Java控制事务的行为分析:
(执行库存减1操作)
Update table set num=num-1 where id=10 andnum>0,紧接着会进行一个inser购买明细的操作,然后commit/rollback;
然后第二个用户Updatetable set num=num-1 where id=10 and num>0,紧接着等待行锁,获得锁lock,来继续执行,然后后面的用户……
这样下来的话,整个秒杀操作可以说是一种串行化的执行序列。
1.5.2 分析瓶颈所在
Update减库存—>insert购买明细—>commit/rollback:这两个过程都存在网路延迟和GC;但并非java和sql本身慢,而是java和通信之间比较慢;
所以,java执行时间+网络延迟时间+GC=这行操作的执行时间(大概在2ms,1秒钟有500次减操作,对于秒杀系统来说这个性能呈指数级下降,并不好)。
1.5.3 优化思路分析
我们知道行级锁是在commit之后释放的,那么我们的优化方向就是减少行级锁的持有时间。
同城机房需要花0.5-2msmax(1000qps),update之后JVM-GC(50ms) max(20qps);
异地机房一次(北京上海之间额一次update Sql需要20ms。
如何判断update更新库存成功?
两个条件:——Update自身不报错,客户端确认影响记录数
优化思路:
把客户端逻辑放在Mysql服务端,避免网络延迟和GC影响。
那么,如何把逻辑放在Mysql服务端呢?
1.5.4 两种优化解决方案
(1)定制SQL方案:update/*+[auto_commit]*/,需要修改Mysql源码;这样可以在SQL执行完之后,直接在服务端完成commit,不用客户端逻辑判断之后来执行是否commit/rollback。 但是这个增加了修改Mysql源码的成本(不推荐)。
(2)使用存储过程:整个事务在MySQL端完成(把整个热点执行放在一个过程当中一次性完成,只需要返回执行的整个结果就行了,这样可以避免网络延迟和GC干扰)。
1.6 优化分析总结
前端控制:暴露接口(动静态数据分离)
按钮防重复(避免重复请求)
动静态数据分离:CDN缓存,后端缓存(redis技术实现的查询)。
事务竞争优化:减少事务锁时间(用Mysql来解决)。
2 Redis后端缓存优化
2.1 Redis 安装
Redis在通常情况下都是使用机群来维护缓存,此处用一个Redis缓存为例。
此处应用的目的:使用redis优化地址接口,暴露接口。
若想使用Redis作为服务端的缓存机制,则应该首先在服务端安装Redis:具体安装教程
在Linux环境下安装Redis步骤可参照:http://blog.csdn.net/fengzheku/article/details/50053961
在Window下安装Redis可参照:http://blog.csdn.net/csdn_terence/article/details/77082988
2.2 优化编码
第一,在Pom.xml文件引入Redis在Java环境下的客户端Jedis.
redis.clients
jedis
2.7.3
com.dyuproject.protostuff
protostuff-core
1.0.8
com.dyuproject.protostuff
protostuff-runtime
1.0.8
第二,添加一个对象序列化的缓存类RedisDao.java:
为什么要使用对象序列化?
序列化的目的是将一个实现了Serializable接口的对象转换成一个字节序列,可以。 把该字节序列保存起来(例如:保存在一个文件里),以后可以随时将该字节序列恢复为原来的对象。
序列化的对象占原有空间的十分之一,压缩速度可以达到两个数量级,同时节省了CPU
Redis 缓存对象时需要将其序列化,而何为序列化,实际上就是将对象以字节形式存储。这样,不管对象的属性是字符串、整型还是图片、视频等二进制类型,
都可以将其保存在字节数组中。对象序列化后便可以持久化保存或网络传输。需要还原对象时,只需将字节数组再反序列化即可。
public class RedisDao {
private final Logger logger=LoggerFactory.getLogger(this.getClass());
private final JedisPool jedisPool;
public RedisDao(String ip,int port)
{
//一个简单的配置;
jedisPool=new JedisPool(ip,port);
}
// protostuff序列化工具用到的架构
// 可以用RuntimeSchema来生成schema(架构:序列化模式)通过反射在运行时缓存和使用
private RuntimeSchema schema=RuntimeSchema.createFrom(Seckill.class);
public Seckill getSeckill(long seckillId)
{
//缓存Redis操作逻辑,而不应该放在Service下,因为这是数据访问层的逻辑
try{
Jedis jedis=jedisPool.getResource();
try{
String key="seckill:"+seckillId;
//并没有实现内部序列化操作
//get->byte[]->反序列化-》Object(Seckill)
//采用自定义序列化方式
//采用自定义的序列化,在pom.xml文件中引入两个依赖protostuff:pojo
byte[] bytes=jedis.get(key.getBytes());
//重新获取缓存
if(bytes!=null)
{
Seckill seckill=schema.newMessage();
//将bytes按照从Seckill类创建的模式架构schema反序列化赋值给对象seckill;
ProtostuffIOUtil.mergeFrom(bytes, seckill, schema);
//Seckill被反序列化
return seckill;
}
}
finally{
jedis.close();
}
}
catch(Exception e){
logger.error(e.getMessage(),e);
}
return null;
}
public String putSeckill(Seckill seckill)
{
//set Object(Seckill)->序列化-》bytes[]
try {
Jedis jedis = jedisPool.getResource();
try {
String key = "seckill:" + seckill.getSeckillId();
// protostuff工具
// 将seckill对象序列化成字节数组
byte[] bytes = ProtostuffIOUtil.toByteArray(seckill, schema,
LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));
// 缓存时间+key标记+对象序列化结果=》放进缓存jedis缓存池,返回结果result(OK/NO)
int timeout = 60 * 60; // 1小时
// 设置key对应的字符串value,并给一个超期时间
String result = jedis.setex(key.getBytes(), timeout, bytes);
return result;
} finally {
jedis.close();
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
return null;
}
} 第三、配置文件对象注入:
在spring-dao.xml文件中为序列化缓存类添加注入参数,用于自动实例化对象;
第四,编写测试类:
RedisDaoTest.java
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration({"classpath:spring/spring-dao.xml"})
public class RedisDaoTest {
private long id=1001;
@Autowired
private RedisDao redisDao;
@Autowired
private SeckillDao seckillDao;
@Test
public void testSeckill() throws Exception{
//get and put
Seckill seckill=redisDao.getSeckill(id);//从缓存中获取
if(seckill==null) //缓冲中没有则查询
{
seckill=seckillDao.queryById(id);//
if(seckill!=null)
{
String result=redisDao.putSeckill(seckill); //缓存序列化对象
System.out.println(result);
seckill=redisDao.getSeckill(id);
System.out.println(seckill);
}
}
else
{
System.out.println("从缓存中获取成功:"+seckill);
}
}
}测试时,要打开服务端Redis中间件的服务;才能用服务端的缓存,具体的参考上一节的安装步骤。
测试结果都正常;
第五,进一步修改缓存代码,在SeckillServiceImpl.java当中使用缓存优化,例如如下暴露接口的方法代码是通过redis缓存来实现的。
public Exposer exportSeckillUrl(long seckillId) {
//优化点:缓存优化(用Redis缓存起来,降低数据库访问压力)
//通过超时来维护一致性。
/**
*get from cache
*if null
* get db
*else
* put cache
*locgoin
*/
//1:访问redis
Seckill seckill=redisDao.getSeckill(seckillId);
if(seckill==null)
{
//2:访问数据库
seckill=seckillDao.queryById(seckillId);
if(seckill==null)
{
return new Exposer(false,seckillId);
}
else
{
redisDao.putSeckill(seckill);
}
}
Date startTime=seckill.getStartTime();
Date endTime=seckill.getEndTime();
//系统当前时间
Date nowTime=new Date();
if(nowTime.getTime()endTime.getTime())
return new Exposer(false,seckillId,nowTime.getTime(),startTime.getTime(),endTime.getTime());
//md5加密:转换特定字符串的过程,不可逆,不希望用户猜到结果;
String md5=getMD5(seckillId);
return new Exposer(true,md5,seckillId);
} 3 并发优化
3.1 优化分析
这一部分主要是针对秒杀操作进行并发优化的;秒杀操作是作为一个事务来执行的。
前面已经分析过:Update减库存—>insert购买明细—>commit/rollback:这个事务作为一个原子,里面两个过程都存在网路延迟和GC。
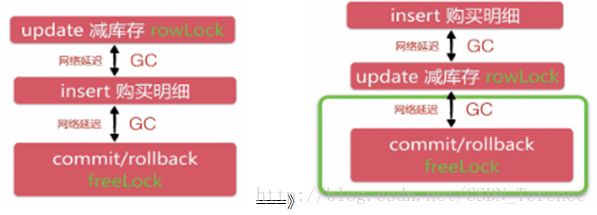
改为:
原来的流程:
第一阶段:秒杀开始先Update更新库存,根据结果记录数量决定是否插入明细。这个过程中存在网络延迟,数据库事务持有行级锁。
第二阶段:根据插入insert的结果,最后执行commit/rollback,这个阶段也存在网络延迟,数据库事务持有行级锁。
最终:行级锁经历了两次的java代码执行+网络延迟+GC
方案一:Sql执行顺序调整
第一阶段:先插入Insert明细(同时根据主键判断了是否重复秒杀),根据返回结果判断如果不是重复秒杀则表明插入成功,然后进入第二阶段;该阶段虽然存在网络延迟但是没有持有行级锁;
第二阶段:直接拿到行级锁,然后更新Update库存,最后根据返回结果决定commit/rollback;
该阶段持有网络延迟并且持有行级锁。
最终:行级锁经历了一次的java代码执行+网络延迟+GC;这种策略将只在最后的更新操作中持有行级锁,降低了commit/rollback的持有时间,访问速度提高到了原来的2倍。
方案二:服务端使用存储过程
这种策略直接在服务端使用存储过程将两个阶段insert和update操作直接绑定在一起,这样行级锁commit/rollback的持有在Mysql端就执行完成结束了,然后通过网络返回结果。
最终:该策略相比于方案一,屏蔽掉了所有的网络延迟,大大的提高了访问速度,可以让Mysql获得更高的QPS,所以可以把它叫做深度优化。
3.2 SQL顺序调整优化编码实现
方案一是利用SQL顺序的调整减掉一半的行级锁持有时间,在Service实现类SeckillServiceImpl中调整:
@Transactional
//秒杀是否成功,成功:减库存,增加明细;失败:抛出异常,事务回滚
public SeckillExecution executeSeckill(long seckillId, long userPhone, String md5)
throws SeckillException, RepeatKillException, SeckillCloseException {
if (md5==null||!md5.equals(getMD5(seckillId)))
{
throw new SeckillException("seckill data rewrite");//秒杀数据被重写了
}
//执行秒杀逻辑:减库存+增加购买明细
Date nowTime=new Date();
//第二个优化点:秒杀操作
//调整insert
try{
//否则更新了库存,秒杀成功,增加明细
int insertCount=successKilledDao.insertSuccessKilled(seckillId,userPhone);
//看是否该明细被重复插入,即用户是否重复秒杀(唯一主键:seckillId,userPhone)
if (insertCount<=0)
{
throw new RepeatKillException("seckill repeated");
}
else {
//减库存,热点商品竞争
int updateCount=seckillDao.reduceNumber(seckillId,nowTime);
if (updateCount<=0)
{
//没有更新库存记录,说明秒杀结束 ----rollback
throw new SeckillCloseException("seckill is closed");
}
else {
//秒杀成功,得到成功插入的明细记录,并返回成功秒杀的信息---commit
SuccessKilled successKilled=successKilledDao.queryByIdWithSeckill(seckillId,userPhone);
return new SeckillExecution(seckillId,SeckillStateEnum.SUCCESS,successKilled);
}
}
}catch (SeckillCloseException e1)
{
throw e1;
}catch (RepeatKillException e2)
{
throw e2;
}catch (Exception e)
{
logger.error(e.getMessage(),e);
//所以编译期异常转化为运行期异常
throw new SeckillException("seckill inner error :"+e.getMessage());
}
}
3.3 深度优化
深度优化是使用方案二:使事务SQL在MySQL端利用存储过程执行,Mysql端只用返回执行的最终结果就行了,这样既可以完全屏蔽掉了网络延迟和GC影响。
3.3.1 创建存储过程
编写SQL语句,建立存储过程:
--使用存储过程执行秒杀
DELIMITER$$ -- console;转换为$$;定义换行符:表示
-- 定义存储过程
-- 参数:in 输入参数;out 输出参数
--row_count():返回上一条修改类型sql(delete,insert,update)的影响行数。
--row_count():0:未修改数据;>0:表示修改数据的行数;<0:sql错误/未执行修改sql。
CREATE PROCEDURE execute_seckill(in v_seckill_id bigint,in v_phone bigint,
in v_kill_time timestamp,out r_result int)
BEGIN
DECLARE insert_count INT DEFAULT 0;
START TRANSACTION ;
INSERT ignoresuccess_killed(seckill_id,user_phone,create_time)
VALUES(v_seckill_id,v_phone,v_kill_time); -- 先插入购买明细
SELECT ROW_COUNT() INTO insert_count;
IF(insert_count = 0) THEN
ROLLBACK ;
SET r_result = -1; -- 重复秒杀
ELSEIF(insert_count < 0) THEN
ROLLBACK ;
SET r_result = -2; -- 内部错误
ELSE -- 已经插入购买明细,接下来要减少库存
update seckill
set number = number -1
WHERE seckill_id = v_seckill_id
AND start_time < v_kill_time
AND end_time > v_kill_time
AND number > 0;
select ROW_COUNT() INTO insert_count;
IF (insert_count = 0) THEN
ROLLBACK ;
SET r_result = 0; -- 库存没有了,代表秒杀已经关闭
ELSEIF (insert_count < 0) THEN
ROLLBACK ;
SET r_result = -2; -- 内部错误
ELSE
COMMIT ; -- 秒杀成功,事务提交
SET r_result = 1; -- 秒杀成功返回值为1
END IF;
END IF;
END
$$
-- 测试
DELIMITER;-- 把DELIMITER重新定义还原成分号;
SET @r_result =-3;
-- 执行存储过程
CALLexecute_seckill(1003,18864598658,now(),@r_result);
-- 获取结果
select @r_result;
drop procedure execute_seckill; -- 删除存储过程
按照上述的SQL语句在mysql数据库查询中执行,创建数据库的存储过程execute_seckill,然后用下面的语句执行存储过程测试。
使用存储过程:
1、使用存储过程优化:降低了事务行级锁持有的时间;
2、但是不要过度依赖存储过程,要根据实际需求而定;
3、简单的逻辑可以应用存储过程
4、QPS得到提升,一个秒杀单可以接近6000/qps
3.3.2 Service调用Procedure实现
第一步,(Mybatis)在SeckillDao.java接口中,添加调用存储过程的方法声明:
/**
* 秒杀操作优化:
* 使用存储过程执行秒杀
* @param paramMap
*/
void killByProcedure(Map paramMap);
第二步,(Mybatis)在SeckillDao.xml配置文件当中,编写SQL语句,带入参数,调用存储过程:
第三步,在SeckillService.java接口中声明方法executeSeckillProcedure:
/**
* 执行秒杀操作 By存储过程
* @param seckillId
* @param userPhone
* @param md5
* @return
*/
SeckillExecution executeSeckillProcedure(long seckillId,long userPhone,String md5)
throws SeckillException,RepeatKillException,SeckillCloseException;
第四步,在SeckillServiceImpl.java这个实现类中实现上述定义的方法,在Java客户端调用存户过程:
/**
* 通过java客户端调用存储过程
* 开发使用存储过程的秒杀逻辑
*/
public SeckillExecution executeSeckillProcedure(long seckillId,
long userPhone, String md5) throws SeckillException,
RepeatKillException, SeckillCloseException {
if (md5==null||!md5.equals(getMD5(seckillId)))
{
return new SeckillExecution(seckillId,SeckillStateEnum.DATA_REWRITE);
}
//执行秒杀逻辑:减库存+增加购买明细
Date killTime=new Date();
Map map=new HashMap();
map.put("seckillId", seckillId);
map.put("phone", userPhone);
map.put("killTime", killTime);
map.put("result", null);
//执行存储过程,result被复制
try{
seckillDao.killByProcedure(map);
//获取result
//此处要在pom.xm,中引入MapUtil用于获取集合内的值
int result=MapUtils.getInteger(map,"result",-2);
if(result==1)
{
SuccessKilledsk=successKilledDao.queryByIdWithSeckill(seckillId,userPhone);
return new SeckillExecution(seckillId,SeckillStateEnum.SUCCESS,sk);
}
else
{
returnnew SeckillExecution(seckillId,SeckillStateEnum.stateOf(result));
}
}
catch(Exception e)
{
logger.error(e.getMessage(),e);
returnnew SeckillExecution(seckillId,SeckillStateEnum.INNER_ERROR);
}
} 第五步:开启Mysql服务和Redis服务
第六步,在SeckillServiceTest.java类中编写测试方法:
@Test
public void executeSeckillProcedureTest()
{
long seckillId=1001;
long phone=13476191899l;
Exposerexposer=seckillService.exportSeckillUrl(seckillId);
if(exposer.isExposed())
{
Stringmd5=exposer.getMd5();
SeckillExecutionexecution=seckillService.executeSeckillProcedure(seckillId, phone, md5);
logger.info(execution.getStateInfo());
System.out.println(execution.getStateInfo());
}
}输出秒杀重复或者秒杀成功,表示测试成功。
4 系统部署架构
系统可能用到哪些服务?
CDN:动静态资源分离
WebServer:Nginx+Jetty服务器容器框架
Redis:服务端缓存
Mysql:数据库,事务,保证数据的一致性和完整性。
系统部署架构:
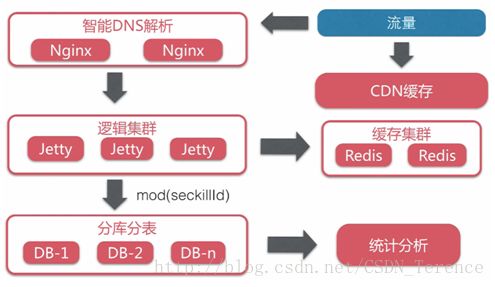
Jetty逻辑机群:用于存放开发的逻辑代码
可能参与的人员角色分配:

4 总结
数据层
数据库技术:数据库设计和实现
Mybatis理解和使用技巧:和数据表对应的entity—--Dao接口--—Dao接口配置sql语句的文件。
Mybatis和Spring的整合技巧:包扫描/对象的注入
业务层技术回顾
站在使用者的角度上进行业务接口设计和封装
SpringIOC配置技巧:注入
Spring声明式事务的使用和理解
Web技术回顾
Restful接口的运用:post/get
Spring MVC的使用技巧
前端交互分析过程
Bootstrap和JS的使用:使用现有的格式,使用模块/对象类似的划分。
并发优化
系统优化点的分析和抽取
事务、锁、网络延迟理解
前端,CDN,缓存等理解和使用
集群化部署