JavaWeb面试内容整理(包含大公司的面试题)
校招的过程其实挺残酷的,不只是笔试的难题还有面试的考验,甚至还有结果等待的煎熬,其实,对于任何事情没有简单可言,只有是否努力可言。小时候第一个数学,1+1=2,回想很简单,然而曾经的那时并不是如此,所以,自己根据自己面试的内容进行了整理,其中包含着阿里巴巴,美团,京东,百度,腾讯,滴滴,CVTE的面试内容。内容比较多。需要点耐心进行浏览哦~
面试知识点:
1:简单讲一下Java的跨平台原理
答:由于非跨平台的情况下,对于不同的操作系统,那么就需要开发几套不同程序代码。为了解决这个问题,java通过不同系统,不同版本,不同位数的JVM来屏蔽不同的系统指令集差异而对外提供统一的接口(JavaAPI),所以这样对于我们普通的开发者来说,只需要开发符合Java规范的程序即可。如果程序需要部署到不同的操作系统,那么我们只需要按照对应版本的虚拟机即可。
2:java开发环境的步骤
答:需要的内容:对应操作系统的JDK , 对应版本位数的IDE(开发工具,比如Eclipse或者IDEA),如果是开发Web项目,那么还需要服务器,比如Tomcat,jetty。
步骤:
(1)下载JDK,并且配置好Java_Home这个环境变量,因为对于开发工具和Tomcat都需要依赖这个配置变量。
(2)下载IDE,正常解压即可。
(3)下载Tomcat ,正常解压即可,并且将这个集成到开发工具中,便于项目进行发布。 三者的版本要符合规范
3:Java中Int数据占几个字节
答:四个字节,32位
4:面向对象的特征有哪些?
答:继承,封装,多态,抽象(然后对每个概念进行描述和讲解一个实例)
5:拆箱和装箱
答:装箱:就是基本数据类型转换成对应的包装类型。
比如:int x = 5 ; -----Integer y = x ; (这是自动装箱)
实际上进行的是:Integer y = Integer.valueOf(x); (这是手动装箱)
拆箱:就是包装类型转换成对应的基本数据类型。
比如:Integer a = 5; -------- int b = a ; (这发生了自动拆箱)
实际进行的是:int b = a.intValue() ; (手动拆箱)
6:有了基本数据类型,为什么还需要包装类型
答:Java是面向对象的语言,而基本数据类型没有面向对象的特性,而且包装类型存在缓存,这样能够更加好的利用资源。(比如,Integer的缓存内容就是-128--------127)
7:equals和==的区别
答:“==”判断两个对象是否值相等。这里要注意:当为基本类型的时候,就是比较值,如果是引用类型,那么就是比较首地址。
Equals:判断两个对象的内容是否一样,这个一般是用于引用对象的比较的使用。
8:实现一个拷贝文件的工具类,使用字符流还是字节流
答:使用字节流,因为我们拷贝的文件中,可能有图片,图像,如果使用字符流就无法进行拷贝,所以为了工具类的实用性,采用字节流更好。
9:简单说一下forward和redirect的区别
答:相同点:都是对请求进行处理
不同点:(1)forward是发生在服务器端,效率更好,而redirect是发生在了客户端
(2)forward是请求转发,只是一次请求,而redirect是相当于了两次请求
(3)Forward不会改变客户端的URL显示,而redirect会改变客户端的URL的显示
10:servlet的生命周期
答:加载servlet的class---》实例化Servlet-----》初始化servlet(调用init方法)------》调用服务service方法(处理doget和dopost方法)-----》servlet容器关闭时调用销毁方法(destory方法)
11:session和cookie的区别
答:共同点:session和cookie都是会话跟踪技术,cookie通过在客户端记录信息确定用户信息,而session通过在服务器端进行记录确定用户信息,但是session依赖于cookie,其中sessionID(session的唯一标识需要存放在客户端);
不同点:(1)cookie存放在客户端的浏览器上,而session存放在服务器中
(2)cookier不是很安全,别人可以分析本地的cookie并进行cookie欺骗,所以考虑安全应该使用session
(3)Session会在一段时间内保存在服务器上,当访问增多时,会比较占用你服务器的性能,考虑到减轻服务器性能,应该使用cookie
(4)单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多存放20个cookie
(5)重要信息一般放在session,而类似购物车就应该使用cookie,但是cookier是可以被禁用的,所以应该利用cookie与数据库两种方式。
12:struts2的执行流程
答:(1)浏览器发送请求,到达服务器
(2)经过一系列的过滤器后,到达核心过滤器(StrusPrepareAndExcuteFilter)
(3)StrusPrepareAndExcuteFilter通过ActionManager判断当前的请求是否需要某个Action处理,如果不需要,就继续执行,如果需要,就会把请求转为ActionProxy处理。
(4)ActionProxy通过configurationManager询问框架的配置(Strus.xml)找到需要调用的aciton类
(5)创建一个ActionInvation实例,来调用Action的对应方法,在调用前会执行一些拦截器
(6)通过调用Action的方法的结果找到对应的结果集name
(7)然后再通过相关的拦截器
(8)通过结果集的name找到对应的结果集来对浏览器进行响应
13:struts2的拦截器?一般用于什么场景?
答:拦截器概念:是动态拦截Action调用的对象,它提供了一种机制可以使开发者在进行Action方法执行前后进行所定义的处理。
(1)struts2中的很多功能都是通过拦截器进行完成的,比如文件上传,参数绑定,字符编码。
(2)如果业务需要,我们可以自定义拦截器,便于在action执行前后,进行所需要的业务处理。
使用场景:
(1)用户登陆判断:判断是否已经登陆,如果没有登陆,则跳转到登陆页面,否则进行放行处理。
(2)权限判断:如果用户没有对应的权限,那么则无法进行访问,否则正常执行。
(3)操作日志:。。。。。。。。。。
14:Springmvc的执行流程
答:(1)用户向服务器发送请求,被前端控制器DispacherServlet捕获。
(2)DispacherServlet对请求URL进行解析,得到请求资源标示符(URI),然后根据URI调用HanderMapping获得该Handlder配置的所有相关的对象(包括handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式进行返回(查找handler)
(3)DispacherServlet根据获得的Handler,选择一个合适的HandlerAdapter,提取Request中的模型数据,填充Handler入参,开始执行Handler(controller),Handler执行完成后,向DispacherServlet返回一个ModelAndView对象(执行handler)。
(4)DispacherServlet根据返回的ModelAndView,选择对应的ViewResovler(必须是已经注册到Spring容器中的ViewResovler)。(简称为选择ViewResovler)
(5)通过ViewResovler结合Model和View,来渲染视图,DispacherServlet再将渲染的结果返回给客户端。
15:struts2和springmvc的区别
答:(1)核心控制器不同。Struts2是filter过滤器,而springmvc是servlet。
(2)控制器实例不同。Springmvc相比strus2要快一些。(理论上)Struts2是基于对象,所以它是多实例的,而springmvc是基于方法的,所以它是单例的,但是应该避免全局变量的修改,这样会导致线程安全问题。
(3)管理方式不同。大部分企业都使用Spring,而Springmvc是spring的一个模块,所以集成更加简单容易,而且提高了全注解的开发形式。而strus2需要采用XML的形式进行配置来进行管理(虽然也可以采用注解,但是公司一般都不会使用)。
(4)参数传递不同。Struts2是通过值栈(ValueStack)进行传递和接受,而Springmvc是通过方法的参数来接受,这样Springmvc更加高效。
(5)学习程度不同。Struts2存在很多技术点,比如拦截器,值栈,以及OGML表达式,学习成本高,而Springmvc比较简单,上手快。
(6)Interrcpter的实现机制不同。Strus2有自己的拦截器的机制,而Springmvc是通过AOP的形式,这样导致strus2的配置文件比springmvc更加庞大。
(7)对于Ajax请求不同。Springmvc可以根据注解@responseBody 来对ajax请求执行返回json格式数据,而strus2需要根据插件进行封装返回数据。
16:说一下spring的两大核心技术
答:Spring的概念:Spring是一个J2EE应用程序框架,是轻量级Ioc和AOP的容器框架(相对于重量级的EJB来说),主要是针对JavaBean的生命周期进行管理的轻量级容器,可以单独使用,也可以和MVC框架和数据库mybatis和hibernate框架进行使用。
(1)IOC或者DI
原来的处理模式:如果某个service需要使用某个Dao,那么就需要手动创建dao对象。
使用spring后:直接通过spring进行依赖注入即可
核心原理:就是配置文件+反射(工厂模式)+容器(map)
(2)AOP
核心原理:使用动态代理的方式在执行前后或出现异常后进行相关逻辑处理。
使用场景:事务处理,日志,权限。。。。。。。
17:spring的事务隔离级别
(2)、 ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。
(3)、 ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
(4)、 ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
(5)、 ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻像读。
18:Spring的事务传播特性
答:多个事务存在是怎么处理的策略。
(1)PROPAGATION_REQUIRED:如果存在一个事务,就支持当前事务,如果不存在事务,则开启事务。
(2)PROPAGATION_SUPPORT:如果存在一个事务,支持当前事务,如果不存在事务,则使用非事务进行执行。
(3)PROPAGATION_MANDTORY:如果已经存在一个事务,支持当前事务,如果没有一个活动的事务,则抛出异常。
(4)PROPAGATION_REQUIRED_NEW:总是开启一个新的事务,如果一个事务已经存在,则将这个事务进行挂起。
(5)PROPAGATION_NO_SUPPORT:总是非事务地执行,并挂起任何存在的事务。
(6)PROPAGATION_NEVER:总是非事务执行,如果存在一个活动事务,则抛出异常。
(7)PROPAGATION_NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中,如果没有活动事务,则按TransactionDefiniton.PROPAGATION_REQUIRED属性执行。
18:什么是ORM框架?
答:ORM(对象关系映射)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术,可以简单的方案是采取硬编码方式(JDBC操作和SQL方式),为每一种可能的数据库访问操作提供单独的方法,这种方法存在很多的缺陷,所以使用ORM框架来进行解决。代表的有:Hibernate和Mybatis
核心原则:(1)简单:以最基本的形式连接数据(2)传达性:数据库结构性任何人都能理解的语言文档化(3)精确性:基于数据模型创建正确标准化的结构
19:Mybatis和Hibernate的相同点和不同点?
参考本篇文章 参考文章二
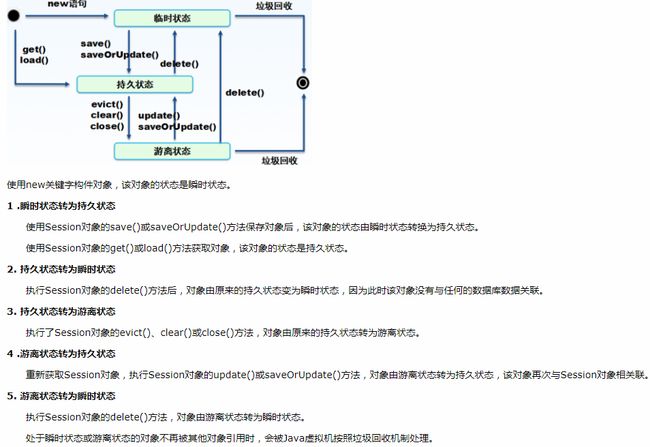
20:Hibernate的对象状态
答:三种,
(1)瞬时状态:通过new创建对象后,对象并没有立刻持久化,它并未与数据库中的数据有任何关联,此时Java对象的状态为瞬时状态。
Session对于瞬时状态的Java对象是一无所知的,当对象不再被其他对象引用时,它的所有数据也就丢失了,对象将会被Java虚拟机按照垃圾回收机制处理。
(2)持久化状态:当对象与Session关联,被Session管理时,它就处于持久状态。处于持久状态的对象拥有数据库标识(数据库中的主键值)。
那么,对象是什么时候与Session发生关联的呢?有两种方法:
第一种,通过Sesison的查询接口,或者get()方法,或者load()方法从数据库中加载对象的时候,加载的对象是与数据库表中的一条记录关联的,此时对象与加载它的Session发生关联;
第二种,瞬时状态的对象,通过Session的save()方法或SaveOrUpdate()方法时,Java对象也与Session发生关联。
对于处于持久状态的对象,Session会持续跟踪和管理它们,如果对象的内部状态发生了任何变更,Hibernate会选择合适的时机(如事务提交时)将变更固化到数据库中。
(3)游离状态:处于持久状态的对象,脱离与其关联的nSession的管理后,对象就处于游离状态。
处于游离状态的对象,Session无法保证对象所包含的数据与数据库中的记录一直,因为Hibernate已经无法感知对该对象的任何操作。
Session提供了两个方法(update()、merge()),将处于游离状态的对象,与一个新的Session发生关联。
此时,对象的状态就从游离状态重新转换为持久状态。
之间的转换关系:
21:Hibernate的缓存
答:(1)为什么需要缓存
目的:提高数据的访问速度,把磁盘或者数据库的数据放入到内存,提高系统性能。
(2)Hibernate缓存的类型
类型:一级缓存和二级缓存。
一级缓存:是session级别缓存,是内置的无法卸载的,是事务级别的缓存(session对象的生命周期通常对应一个数据库事务或者一个应用程序),持久化类型的那个实例都具有唯一的OID。
二级缓存:是sessionFactory的缓存。由于sessionFactory的生命周期和整个应用程序的整个过程对应,所以二级缓存是进程范围或者集群范围的缓存,会出现并发问题,因此需要采取适当的访问策略,该策略为被缓存数据提供了事务隔离级别。二级缓存是可选的,默认情况是不开启的。
(3)什么数据适合放入到缓存
1:很少被修改的数据 2:经常被查询的数据 3:不会被并发访问的数据 4:常量数据 5:不是很重要的数据,偶尔会被并发的数据。
(4)Hibernate缓存的缺陷
缺陷:Hibernate的二级缓存无法解决分布式缓存问题,所以需要通过memcache丶redis等中央缓存来代替二级缓存。
22:简单讲解一下WebService使用的场景?
答:概念:WebService是SOA(面向服务编程)的架构,它是不依赖于语言,不依赖于平台,可以实现不同的语言间的相互调用,通过Internet进行基于Http协议的网络应用间的交互。
webservice就是远程调用技术,也叫XML Web Service WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的独立的通讯技术。是:通过SOAP在Web上提供的软件服务,使用WSDL文件进行说明,并通过UDDI进行注册
主要的技术点:(1)SOAP:是web service的结拜呢通信协议,定义SOAP消息的XML格式;-----就是所使用的协议
(2)WSDL:是一种XML文档,它定义SOAP消息以及这些消息是怎样交换的,主要就是定义使用服务的规范(因为不同的web service所自定义的参数和格式都不一定相同,而客户端如果要使用的话,那么就必须要明白对应的规范格式是如何的格式);----就是相当于提供一份详细的使用说明书;
(3)UDDI:可以被比喻成电话本,电话本里记录的是电话信息,而UUDI记录的是Web Service信息。可以不把Web Service注册到UDDI,但如果要让全球的人知道自己的Web Service,最好还是注册到UDDI;----就是相当于为了方便更多的人进行查询和使用;
UDDI目录说明文件也是一个XML文档,其主要是包含三个部分:白页:说明提供Web Service的公司信息,比如名称,地址等;黄页:说明UDDI目录的分类,比如金融,服务等;绿页:说明接口由Web Service提供的详细信息;
场景:(1)异构系统(不同语言)的整合
(2)不同客户端的整合浏览器,安卓,微信,PC端访问
(3)比如手机上的天气预报,就是通过webservice调用接口
(4)比如单点登录:一个服务是所有系统的登录。
23:简单介绍一下Activiti?
答:Activiti是一个开源的工作流引擎,它实现了BPMN 2.0规范,可以发布设计好的流程定义,并通过api进行流程调度。
Activiti 作为一个遵从 Apache 许可的工作流和业务流程管理开源平台,其核心是基于 Java 的超快速、超稳定的 BPMN2.0 流程引擎,强调流程服务的可嵌入性和可扩展性,同时更加强调面向业务人员。
Activiti 流程引擎重点关注在系统开发的易用性和轻量性上。每一项 BPM 业务功能 Activiti 流程引擎都以服务的形式提供给开发人员。通过使用这些服务,开发人员能够构建出功能丰富、轻便且高效的 BPM 应用程序。
它易于与Spring整合,主要使用在OA(办公自动化)上,把线下流程放到线上,把现实生活中一些流程固定在流程中。它可以运用到OA的流程管理中,比如请假流程,报销流程。
24:有没有做过数据库优化方面的事情?
答:(1)查找,定位慢查询,并优化
优化方案:
(2)创建索引:创建合适的索引,我们就可以先在索引中查询,查询到之后直接到对应的记录。
(3)分表:当一张表的数据比较多或者一张表的某些字段的值比较多并且很少使用时,就采用水平分表和垂直分表优化。
(4)读写分离:当一台服务器不能满足需求时,采用读写分离的方式进行集群。
(5)缓存:使用redis来进行缓存
(6)语句优化:比如少使用子查询而用join操作,少使用or多用IN,避免函数操作字段,避免模糊匹配,少用Order by排序,
25:如何定位慢查询和查找慢查询?
答:(1)开启慢查询功能
在mysql的my.ini文件,添加下面的内容:
slow_query_log= 1 //------>开启慢查询,默认是不开启,即设置为0的;
long_query_time= 1 //------>设置查询时间不能超过1秒(默认单位是秒)
slow_query_log_file=c:/slow.log //----->设置慢查询记录的文件的位置,这样就会把执行超过1秒的sql语句进行记录
(2)对于慢查询的语句,那么就通过上面的一个问题的答案即可。
26:设计数据库所要遵循的范式?
答:1NF,2NF,3NF和适度的反3NF(即可以适当的增加冗余字段)
27:数据库如何选择合适的存储引擎?
答:存储引擎的类别:分为三类
(1)Innodb:对事务要求高,一般对于重要的数据的存储,建议使用该引擎。比如订单表,账号表等。。。
(2)Myisam:对事务要求不高,同时是以查询和添加为主的,建议使用该引擎,比如BBS系统中的发帖数和回帖数。
(3)Memory:数据变化频繁,不需要入库,同时又频繁的查询和修改,建议使用该引擎,速度相对较快。
Myisam与Innodb的区别:
(1)事务安全:MyiSAM不支持事务,Innodb支持事务;
(2)锁机制:前者支持表锁,而后者支持行锁;
(3)外键:前者不支持外键,而后者支持;
(4)查询和添加速度:前者快,后者慢;
(5)全文索引:前者支持,后者不支持;
28:数据库如何进行索引的选择?
答:索引的类型:四种
(1)普通索引:允许有重复的值;
(2)唯一索引:不允许有重复的值;
(3)主键索引:特殊的唯一索引,是随着主键的创建而创建,也就是把某个列设为主键的时候,数据库就会给该列创建索引,唯一且不能为null值;
(4)全文索引:用来对表中的文本域(text,varchar)进行索引;只在MyISAM引擎中支持,Innodb不支持;
29:数据库索引使用的技巧?
答:(1)建立索引的缺点:占用磁盘空间,并且会对dml(插入,删除,修改,)操作速度产生影响,变慢;
(2)建立索引列的原则:不是频繁进行修改;该字段不是频繁的几个(比如sex列不适合);肯定在where条件中进行使用;
(3) 不能使用索引的情况:
a:使用查询语句LIKE “%XXXX”,以%开头是不能使用索引的,而如果是LIKE "XXX%"的就会使用索引;
b:使用or查询,如果or两端中,有一个字段是没有索引的,那么就不会使用索引;
c:对于联合索引,没有符合“最左原则”;
d:对于索引列上面进行了数学运算;
e:对于索引列上面进行了函数运算;
f:如果列类型是字符串,那一定要在条件中将数据使用引号进行使用,否则不使用索引;
g:如果mysql估计使用全表扫描要比使用索引快,则不会使用索引;
(4)不推荐建立索引情况:
a:数据的唯一性差;比如性别列,因为数据就只有两种情况,那么建议的二叉树级别少,多是平级,这样无异于进行全表扫描;
b:频繁更新的字段不要建立索引;比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。
c) 字段不在where语句出现时不要添加索引,如果where后含IS NULL /IS NOT NULL/ like ‘%输入符%’等条件,不建议使用索引
只有在where语句出现,mysql才会去使用索引
d) where 子句里对索引列使用不等于(<>),使用索引效果一般
30:数据库优化之分表?
答:(1)水平分表(按行数据进行分表):mysql数据一般达到百万级别,查询效率会很低,容易造成表锁,甚至堆积很多连接,直接挂掉,水平分表能够很大程序减少这些压力。
水平分表的策略:
a:按时间分表:这种分表方式有一定的局限性,当数据有较强的实效性,如微博发送记录,微信消息。。。这种数据很少有用户会查询几个月前的数据,就可以按月进行分表;
b:按区间范围分表:一般在有严格的自增id需求上,通过一个原始目标的ID或者名称通过一定的hash算法计算出数据存储的表明,然后再访问相应的表;
c:hash分表:(用得最多的),
(2)垂直分表(按列分表):如果一张表中某个字段值非常多(长文本,二进制等),而且只有在很少的情况下被查询,这个时候就可以把多个字段单独放到一张表,通过外键关联起来;比如考试详情,一般只关注分数,不关注详情;
31:数据库的优化之读写分离?
答:当一台数据库无法满足过多的并发数据库访问的时候,就可以采取数据库的读写分离;
两个核心问题:
a:主从同步:数据库最终会把数据持久化到磁盘,如果集群必须确保每个数据库服务器的数据是一致的,所以对能改变数据库数据的操作都在主数据库去操作,而其他的数据库从主数据库上同步数据
b:读写分离:使用负载均衡来实现写的操作都在主数据库,而读的操作都在从服务器。
32:数据库优化之缓存?
答:在持久层(DAO)和数据库(DB)直接添加一个缓存层,如果用户访问的数据已经被缓存起来时,在用户访问时直接从缓存中获取,不用访问数据库,而缓存是内存级别的,访问速度快。
作用:减少数据库服务器压力,减少访问时间。
java中常用的缓存有:hibernate二级缓存(不能解决分布式缓存);redis缓存;memcache缓存;
33:数据库语句优化小技巧?
答:(1)DDL优化:
a:通过禁用索引俩提供导入数据性能,这个操作主要针对有数据的表
b:关闭唯一校验
set unique_checks=0 关闭 set unique_checks=1 开启
c:修改事务提交方式
set autocommit = 0 关闭 set autocommit = 1 开启批量导入
(2)DML优化:
a:多次提交变为一次提交
insert into test values(1,2);
insert into test values(3,4);
变为:insert into test values(1,2),(3,4);
(3)DQL优化:
Order by优化----------多用索引排序
可以参考如下的这篇文章:数据库优化策略
34:redis对象保存方式?
答:(1)Json字符串:需要把对象转换为json字符串,当做字符串处理,直接使用set get来设置
优点:设置和获取比较简单
缺点:没有提供专门的方法,需要把对象转换为json
(2)字节:需要做序列号,就是把对象序列化为字节保存
如果但是JSON转对象会消耗资源的情况,这个问题就需要考量几个地方:
a:就是使用JSON转换的lib是否存在性能问题
b:就是数据的数据量级别,如果是存储百万级的大数据对象,建议采用存储序列化对象方式,如果是少量的数据级对象,或者是数据对象字段不多,还是建议采用JSON转String方式。毕竟redis对存储字符类型这部分优化非常好。
35:redis的数据淘汰策略
答:原因:因为redis的内存是有限的,不能无限制的存放缓存内容,所以对于数据要进行相应的策略处理。
策略方式(六种):
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
36:区别B树,B-,B+,B*,平衡二叉树,红黑树?
答:
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
关于B,B-,B+,B*树的总结文章
关于红黑树的总结文章
B树只能够进行随机检索,而B+树支持随机检索和顺序检索。
37:Java锁的类型
答:(1)公平锁/非公平锁
(2)可重入锁
(3)独享锁/共享锁
(4)互斥锁/读写锁
(5)乐观锁/悲观锁------这个hibernate中用到很多
(6)分段锁------这个就是concurrentHashMap底层相对HashMap线程安全的地方的实现原理
(7)自旋锁-------这个就是原子类(比如AstomicInteger类)的底层CAS的实现
(8)偏向锁/轻量级锁/重量级锁
参考本篇文章:Java中各种不同锁的类型
38:Java并发编程中的countDownLatch,CyliBarry(栅栏),semaphor(信号量),Exchanger(线程数据交换)这四个对象,另外还有对Runable和Callabel两个接口了解和区别及其Future和FutureTask了解,和线程池Excutor对象中的excute()和submit()方法的区别。
答:这几个对象都是在java并发包中的,针对不同的并发问题进行的解决办法,所以要对上面的进行了解
其中的两个接口也是需要进行掌握的,还有就是线程池的那两个方法都是有不同的区别。
39:数据库主从配置
答:(1)如何进行配置的话就不多说
(2)在使用主从配置的实践项目中,有几种方法进行主从数据库的使用:
方法一:采用中间件来进行主从数据库的切换选择,比如使用阿里开源的mycat,和360开源的atalas,都是在主数据库中进行配置好,就好了,通过这样的方式进行的话,比较方便。
方法二:就是通过在spring配置中,首先配置好主从数据库的配置xml内容,然后通过AOP机制来进行判断注解的形式,来采取主从数据库的选择。这种方法是通过代码来进行完成的。可以参考下面的这篇文章。Spring如何采取主从数据库的实施
40:Java中的动态代理
答:(1)静态代理(2)JDK动态代理(3)cglib动态代理
41:Maven常见的依赖范围(scope)有哪些?
答:(1)compile:编译依赖,默认的依赖方式,在编译(编译项目和编译测试用例),运行测试用例,运行(项目实际运行)三个阶段都有效,典型地有spring-core等jar。
(2)test:测试依赖,只在编译测试用例和运行测试用例有效,典型地有JUnit。
(3)provided:对于编译和测试有效,不会打包进发布包中,典型的例子为servlet-api,一般的web工程运行时都使用容器的servlet-api。
(4)runtime:只在运行测试用例和实际运行时有效,典型地是jdbc驱动jar包。
(5)system: 不从maven仓库获取该jar,而是通过systemPath指定该jar的路径。
(6)import: 用于一个dependencyManagement对另一个dependencyManagement的继承。
42:Maven中dependencyManagement和dependency的区别。
dependencies:
就算在子项目中不写该依赖项,那么子项目仍然会从父项目中继承该依赖项(全部继承)
dependencyManagement:
只是声明依赖,并不实现引入,因此子项目需要显示声明需要用的依赖。如果不在子项目中声明依赖,是不会从父项目中继承下来的;只有在子项目中写了该依赖项,并且没有指定具体版本,才会从父项目中继承该项,并且version和scope都读取自父pom;另外如果子项目中指定了版本号,那么会使用子项目中指定的jar版本
43:Maven配置多仓库的方法
答:(1)可以配置多个mirror镜像,但是这样不好,如果在某环境不可用时,maven下载jar速度变得很慢;
(2)可以增加repository标签,通过在里面加入url指定仓库地址即可,这样就不会影响原来的仓库结构;
(3)配置本地仓库----》通过localRepostitory标签和中央仓库-----》通过mirror标签,一般国内都是使用阿里的镜像,访问快,结合的方式;
44:Maven项目进行分模块开发的作用
答:非模块化的缺点:
(1)首先build整个项目的时间越来越长,尽管你一直在web层工作,但你不得不build整个项目
(2)模块化体现不出来,如果我们只负责维护某个模块,因为我们所有的模块都在一个war包中,那么我们可以随意修改其他模块(权限的控制),导致版本管理混乱,冲突。同时因为模块太多,太大,不好维护。很多人都在同时修改这个war包,将导致工作无法顺利进行。
(3)pom.xml本来是可以继承、复用的,但是如果我们新建一个项目,只能依赖于这个war包,那么会把这个war包的相关的前台的东西依赖过来,导致项目管理混乱。
(4)项目管理复杂,因为文件包含过多,不利于项目不同成员之间的分块开发;
模块化的优点:
(1)方便重用,比如之前开发了一个学生线,那么当我们再开发一条teacher线的时候,我们只需要引用两条线之间共有的模块,这些包都是复用的,称为我们平台复用的基础类库,供所有的项目使用。这是模块化最重要的一个目的。
(2)灵活性。比如我们这些公共的jar包,当不需要的时候,可以直接deploy到nexus,其他人从这个nexus私服下载就可以了,代码的可维护性、可扩展性好,并且保证了项目独立性与完整性。
(3)开发效率提高。通过不同的模块进行分开开发,各个模块小组可以并发开发,类似“高内聚,低耦合”的模式,而不需要进行基础模块开发,提供了工作效率。
45:wait和notify的内容和实现生产者消费者模型
答:参考这篇文章 生产者消费者
还有就是wait方法为什么要放在while语句中进行循环判断,而不是用if来进行条件判断的原因,很重要,可以参考这篇文章
为什么wait方法需要放在while语句后面的详解
46:JVM的内存结构
答:(1)栈(2)堆)(3)方法区(4)本地栈(5)程序计算器
堆区分为:新生代(复制方法清理)和老年代(标记--整理方法);新生代又分为Eden和Surior区(这里面又分为From space和To space),其两者内存空间的比例是8:1;
47:Minor GC 触发 和Full GC的触发条件
答:Mirror GC 触发条件:
(1)当Eden区满的时候,就会触发Mirror GC
Full GC 触发条件:
(1)当调用System.gc()的方法
(2)当老年代的内容不足
(3)当方法区的内容不足
(4)当从Eden区的对象进入到老年代的内存大于老年代剩余的大小
(5)当从Eden区和From space 区的对象复制到To Space 空间的时候,而To space空间的大小不够存放,则会转存到老年代,而此时老年代的内存大小不足,这时候也会触发Full GC
(6)dump内存的时候:比如,通过jmap工具dump内存的时候,先进行full gc 再开始dump
48:JVM中的GC(垃圾回收)的机制
答:
(1)如何判断一个对象是否能够被清除
方法一:引用计数法(实现简单,但是无法解决循环引用的问题)
在java中是通过引用来和对象进行关联的,也就是说如果要操作对象,必须通过引用来进行。那么很显然一个简单的办法就是通过引用计数来判断一个对象是否可以被回收。不失一般性,如果一个对象没有任何引用与之关联,则说明该对象基本不太可能在其他地方被使用到,那么这个对象就成为可被回收的对象了。
方法二:可达性分析:
在Java中采取了 可达性分析法。该方法的基本思想是通过一系列的“GC Roots”对象作为起点进行搜索,如果在“GC Roots”和一个对象之间没有可达路径,则称该对象是不可达的,不过要注意的是被判定为不可达的对象不一定就会成为可回收对象。被判定为不可达的对象要成为可回收对象必须至少经历两次标记过程,如果在这两次标记过程中仍然没有逃脱成为可回收对象的可能性,则基本上就真的成为可回收对象了。
备注----两次标记的过程详细:
对于用可达性分析法搜索不到的对象,GC并不一定会回收该对象。要完全回收一个对象,至少需要经过两次标记的过程。
第一次标记:对于一个没有其他引用的对象,筛选该对象是否有必要执行finalize()方法,如果没有执行必要,则意味可直接回收。(筛选依据:是否复写或执行过finalize()方法;因为finalize方法只能被执行一次)。第二次标记:如果被筛选判定位有必要执行,则会放入FQueue队列,并自动创建一个低优先级的finalize线程来执行释放操作。如果在一个对象释放前被其他对象引用,则该对象会被移除FQueue队列。
(2)要准确理解Java的垃圾回收机制,就要从:“什么时候”,“对什么东西”,“做了什么”三个方面来具体分析。
第一:“什么时候”即就是GC触发的条件。GC触发的条件有两种。(1)程序调用System.gc时可以触发;(2)系统自身来决定GC触发的时机。
系统判断GC触发的依据:根据Eden区和From Space区的内存大小来决定。当内存大小不足时,则会启动GC线程并停止应用线程。
第二:“对什么东西”笼统的认为是Java对象并没有错。但是准确来讲,GC操作的对象分为:通过可达性分析法无法搜索到的对象和可以搜索到的对象。对于搜索不到的方法进行标记。
第三:“做了什么”最浅显的理解为释放对象。但是从GC的底层机制可以看出,对于可以搜索到的对象进行复制操作,对于搜索不到的对象,调用finalize()方法进行释放。
具体过程:当GC线程启动时,会通过可达性分析法把Eden区和From Space区的存活对象复制到To Space区,然后把Eden Space和From Space区的对象释放掉。当GC轮训扫描To Space区一定次数后,把依然存活的对象复制到老年代,然后释放To Space区的对象。
49:JVM中GC的清理方法
答:(1)标记--清除:优点:简单 缺点:容易生成很多的内存碎片
(2)复制:这是堆中的新生代中使用的方法; 优点:减少了内容碎片,并且非常高效 缺点:使得内存的空间大小被分成多个块,每次使用的内存大小减少
(3)标记--整理:这是堆中的老年代中使用的方法;
(4)分代收集:也就是把堆分为新生代和老年代,然后再使用上面的三种方法中的不同方法,这种方法也是目前用得最多的方法;
50:JVM中的GC收集器
答:(1)对于新生代:
1:Serial收集器
2:ParNew收集器
3:Parallel Scavenge收集器
(2)对于老年代:
1:Serial Old收集器
2:Parallel Old收集器
3:CMS收集器 4:G1收集器
关于JVM中的垃圾收集器的介绍
关于JVM介绍非常好的文章(1)
关于JVM中的GC触发条件的文章
51: