OpenCv-Python-Tesseract验证码识别
Tesseract-ocr是一个文本识别的引擎,它能识别英文文本和数字文本,准确率极高,关于中文文本需要下载中文文本的文件进行加载,它也支持用户自定义训练文本。相比于机器学习或深度学习识别文本文字,tesseract方便小巧,对计算机性能要求不高,对样本量的要求也不高。
本文不对任何文本做任何训练,只是单纯的想记录Tesseract-ocr在opencv中的使用。
1、安装Tesseract-ocr。
下载地址:
https://digi.bib.uni-mannheim.de/tesseract/
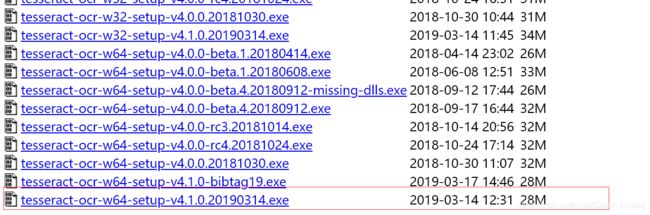
从这里面随便选择一个下载包安装,我选择的是最新的一个版本下载好之后双击安装,我的安装路径如下:
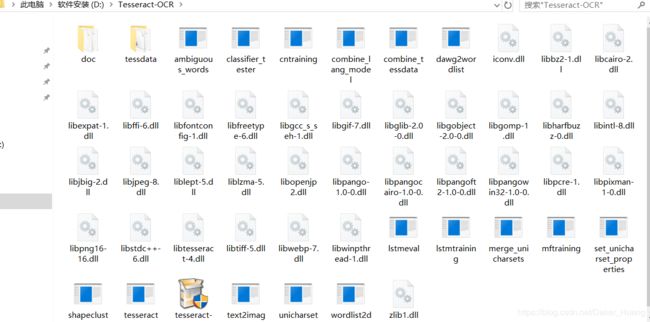
2、配置环境变量。
把系统变量和用户变量的Path选项都加上安装路径:

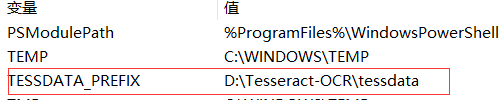
3、在系统变量中新建一个变量
变量名和配置路径如下图所示:
4、安装pytesseract库
这个直接pip install pytesseract 就可以了。
5、更改tesseract_cmd
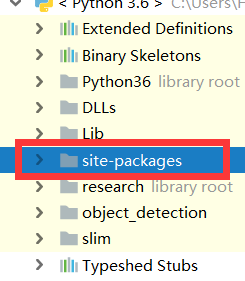
在pycharm中新建一个项目(基于pip安装的),然后展开下图所示的文件夹:
再展开下图所示的文件夹:
打开下图所示的py文件:
找到如下的字符变量并做更改:
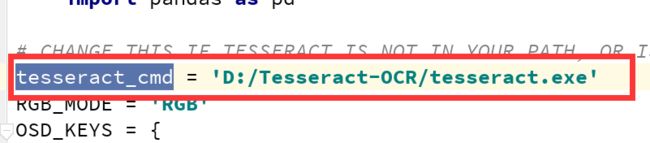
改成上图的样子就大功告成。
接下来我们做一个验证码的识别:
测试图片:

这是我自己用画图工具画的一张图片,下面用opencv+python识别上图字母。
代码:
1、二值化图像转化
src=cv.imread("hello.png",1) #读取图片
gray=cv.cvtColor(src,cv.COLOR_BGR2GRAY) #转为灰度图
ret,binrary=cv.threshold(gray,0,255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU) # 转为二值图像
cv.imshow("binrary image",binrary)
显示结果:

2、形态学操作
1)开运算
kernel1=cv.getStructuringElement(cv.MORPH_RECT,(4,3)) # 建立结构元素
result_open1=cv.morphologyEx(binrary,cv.MORPH_OPEN,kernel1) #开操作
cv.imshow("result_open1 image",result_open1)
运行结果:

可以看到,上图中还有一个白色小点没有去掉,我们再进行一次开操作去掉小点。但是这一次采用的结构元素大小尽量小点。
2)开操作
kernel2=cv.getStructuringElement(cv.MORPH_RECT,(3,4))
result_open2=cv.morphologyEx(result_open1,cv.MORPH_OPEN,kernel2) #开操作
cv.imshow("result_open2 image",result_open2) # 显示图片
运行结果:

这时我们可以看到白色小点已经被去掉了,但糟糕的是识别的文字出现了断裂,这时我们想要它连起来,就使用闭操作。
3)闭操作
kernel3=cv.getStructuringElement(cv.MORPH_RECT,(5,5))
result_close1=cv.morphologyEx(result_open2,cv.MORPH_CLOSE,kernel3) # 闭操作
cv.imshow("result_close1 image",result_close1) # 显示图片
运行结果:

这样子的话,再送给tesseract-ocr进行识别的话,效果肯定是最好的。
3、调用tesseract识别文本
textimage=Image.fromarray(result_close1)
text=tess.image_to_string(textimage) # 转文本显示
运行结果:

所有源码:
import cv2 as cv
from PIL import Image
import pytesseract as tess
src=cv.imread("hello.png",1) #读取图片
gray=cv.cvtColor(src,cv.COLOR_BGR2GRAY) #转为灰度图
ret,binrary=cv.threshold(gray,0,255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU) # 转为二值图像
cv.imshow("binrary image",binrary)
# 形态学操作
kernel1=cv.getStructuringElement(cv.MORPH_RECT,(4,3)) # 建立结构元素
kernel2=cv.getStructuringElement(cv.MORPH_RECT,(3,4))
kernel3=cv.getStructuringElement(cv.MORPH_RECT,(5,5))
result_open1=cv.morphologyEx(binrary,cv.MORPH_OPEN,kernel1) #开操作
cv.imshow("result_open1 image",result_open1)
result_open2=cv.morphologyEx(result_open1,cv.MORPH_OPEN,kernel2) #开操作
cv.imshow("result_open2 image",result_open2) # 显示图片
result_close1=cv.morphologyEx(result_open2,cv.MORPH_CLOSE,kernel3) # 闭操作
cv.imshow("result_close1 image",result_close1) # 显示图片
textimage=Image.fromarray(result_close1)
text=tess.image_to_string(textimage) # 转文本显示
print(text)
cv.waitKey(0)
cv.destroyAllWindows()