隐马尔可夫模型(HMM) python实现
C S D N 真 的 很 过 分 , 换 了 K a t e x 很 多 公 式 都 显 示 不 出 来 了 … … 看 完 整 公 式 请 移 步 \color{red}{CSDN真的很过分,换了Katex很多公式都显示不出来了……看完整公式请移步} CSDN真的很过分,换了Katex很多公式都显示不出来了……看完整公式请移步
Baileyswu@github
学习目标:
- 介绍HMM的定义与符号
- 讨论HMM的三个基本问题
- 概率计算问题:前后向算法
- 学习问题:Baum-Welch模型,EM算法计算参数
- 预测问题:Viterbi算法
- 每种算法用代码实现
- 参考李航的《统计学习方法》(在这里吐槽一下HMM那章下标 i i i 乱用,有些算法不是很ok)
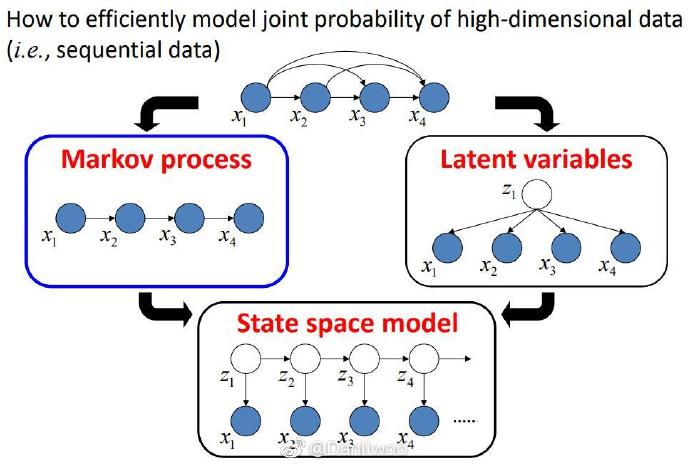
基本概念
HMM是一种时序数据模型。
设序列长度为 T T T ,具有观测序列 X ⃗ = { x ⃗ 1 , … , x ⃗ T } \vec X=\{\vec x_1,\dots,\vec x_T\} X={x1,…,xT} 和隐变量序列 Z ⃗ = { z ⃗ 1 , … , z ⃗ T } \vec Z=\{\vec z_1,\dots,\vec z_T\} Z={z1,…,zT} 。
这里认为每一个观测都由对应的隐变量生成。隐变量序列是Markov链, z ⃗ t \vec z_t zt只依赖于 z ⃗ t − 1 \vec z_{t-1} zt−1
变量都在有限的状态集里变化,观测的状态集为 S ⃗ = { s ⃗ 1 , … , s ⃗ M } \vec S=\{\vec s_1,\dots,\vec s_M\} S={s1,…,sM} ,隐变量的状态集为 H ⃗ = { h ⃗ 1 , … , h ⃗ N } \vec H=\{\vec h_1,\dots,\vec h_N\} H={h1,…,hN} 。
因此 x ⃗ t ∈ S ⃗ , z ⃗ t ∈ H ⃗ , t = 1 , … , T \vec x_t\in \vec S,\vec z_t\in \vec H,t=1,\dots,T xt∈S,zt∈H,t=1,…,T 。
有时需要反向找到某状态是状态集里的第几个,定义 f i n d i n d e x ( z ⃗ t ) = i findindex(\vec z_t)=i findindex(zt)=i ,表示 z ⃗ t = h ⃗ i \vec z_t = \vec h_i zt=hi 。
同理也有 f i n d i n d e x ( x ⃗ t ) = i findindex(\vec x_t)=i findindex(xt)=i ,表示 x ⃗ t = s ⃗ i \vec x_t = \vec s_i xt=si 。
隐状态间的转移矩阵为 A ⃗ = [ a i j ] N × N \vec A=[a_{ij}]_{N\times N} A=[aij]N×N , a i j a_{ij} aij 是从状态 h ⃗ i \vec h_i hi 转移到 h ⃗ j \vec h_j hj 的概率。
从隐状态到观测的发射矩阵 B ⃗ = [ b i j ] N × M \vec B=[b_{ij}]_{N\times M} B=[bij]N×M , b i j b_{ij} bij 是从状态 h ⃗ i \vec h_i hi 转移到观测 s ⃗ j \vec s_j sj 的概率。
初始状态概率向量为 Π ⃗ = [ π 1 , … , π N ] \vec \Pi=[\pi_1,\dots,\pi_N] Π=[π1,…,πN] 。鉴于初始时没有其他时刻转移到 t = 0 t=0 t=0 ,设 z ⃗ 0 \vec z_0 z0 有 π i \pi_i πi 的概率属于 h ⃗ i \vec h_i hi 。
记 λ = ( A ⃗ , B ⃗ , Π ⃗ ) \lambda=(\vec A, \vec B, \vec \Pi) λ=(A,B,Π) ,为HMM中的参数的集合。
生成观测序列
输入: T , S ⃗ , H ⃗ , λ = ( A ⃗ , B ⃗ , Π ⃗ ) T,\vec S, \vec H, \lambda=(\vec A, \vec B, \vec \Pi) T,S,H,λ=(A,B,Π)
输出: X ⃗ \vec X X
例如:有4个盒子,每个盒子里有若干红球和白球。每次从某盒子抽某色的球,求该序列的颜色。
这个例子中加上约束:盒子之间转移的概率(转移矩阵),盒子里球的概率分布(发射矩阵)。
由于需要按照特定概率分布产生随机数,定义下面这个函数,输入分布,输出该分布下的随机数。
import math
import random
# generate according to the distribution
def generate(rate):
r = random.random()
sum = 0
for i in range(len(rate)):
sum += rate[i];
if(r <= sum):
return i
return len(rate)-1
distribution = [0.4, 0.1, 0.5]
count = [0]*len(distribution)
for i in range(100000):
rd = generate(distribution)
count[rd] += 1
print(count)
[39905, 9884, 50211]
def observation(T, S, H, A, B, pi):
z = generate(pi)
x = S[generate(B[z])]
Z = [H[z]]
X = [x]
for t in range(1, T):
z = generate(A[z])
x = S[generate(B[z])]
Z.append(H[z])
X.append(x)
return Z, X
T = 10
S = ['red', 'white']
H = ['box1', 'box2', 'box3', 'box4']
A = [
[0, 1, 0, 0],
[0.3, 0, 0.7, 0],
[0, 0.4, 0, 0.6],
[0, 0, 0.6, 0.4]
]
B = [
[0.5, 0.5],
[0.3, 0.7],
[0.6, 0.4],
[0.4, 0.6]
]
pi = [0.4, 0.1, 0.25, 0.25]
Z, X = observation(T, S, H, A, B, pi)
print(Z)
print(X)
['box4', 'box4', 'box3', 'box2', 'box1', 'box2', 'box1', 'box2', 'box3', 'box4']
['red', 'red', 'white', 'red', 'red', 'red', 'red', 'white', 'white', 'white']
从转移矩阵可以发现一件有趣的事。 a 12 = 1 a_{12}=1 a12=1,这说明每次抽一号盒子之后,下一次一定抽二号盒子。
概率计算问题
输入: X ⃗ , λ = ( A ⃗ , B ⃗ , Π ⃗ ) \vec X,\lambda=(\vec A, \vec B, \vec \Pi) X,λ=(A,B,Π)
输出: P ( X ⃗ ∣ λ ) P(\vec X|\lambda) P(X∣λ)
暴力不可解,借用DP的思想,一层一层算,引入前后向算法。
前向概率
从第 t t t 层算第 t + 1 t+1 t+1 层,经典的DP的想法。
第一层是边界,特判。
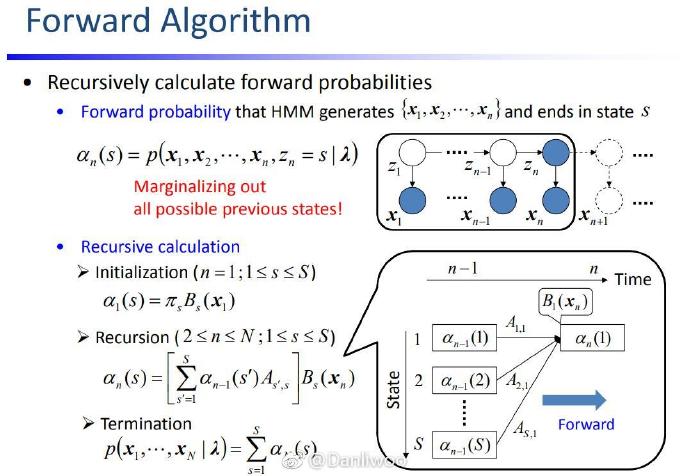
KaTeX parse error: No such environment: align at position 7: \begin{̲a̲l̲i̲g̲n̲}̲ \alpha_t(i)&=P…
α t ( i ) = { π i b i k t=1 ( ∑ j = 1 N α t − 1 ( j ) a j i ) b i k t>1 k = f i n d i n d e x ( x ⃗ t ) \alpha_t(i)=\begin{cases} &\pi_i b_{ik}&\text{t=1}\\ &\left(\sum_{j=1}^N \alpha_{t-1}(j)a_{ji}\right)b_{ik} &\text{t>1} \end{cases}~~~~~~~~k=findindex(\vec x_{t}) αt(i)={πibik(∑j=1Nαt−1(j)aji)bikt=1t>1 k=findindex(xt)
def cal_alpha(T, S, H, A, B, pi):
N = len(H)
ap = []
for i in range(N):
ap.append(pi[i]*B[i][S.index(X[0])])
alpha = [ap]
for t in range(1, T):
ap = []
for i in range(N):
sum = 0
for j in range(N):
sum += alpha[t-1][j]*A[j][i]
ap.append(sum*B[i][S.index(X[t])])
alpha.append(ap)
return alpha
alpha = cal_alpha(T, S, H, A, B, pi)
for t in range(T):
for p in alpha[t]:
print("{:.15f}".format(p), end = " ")
print()
0.200000000000000 0.030000000000000 0.150000000000000 0.100000000000000
0.004500000000000 0.078000000000000 0.048600000000000 0.052000000000000
0.011700000000000 0.016758000000000 0.034320000000000 0.029976000000000
0.002513700000000 0.007628400000000 0.017829720000000 0.013032960000000
0.001144260000000 0.002893676400000 0.007895793600000 0.006364406400000
0.000434051460000 0.001290773232000 0.003506530392000 0.002913295488000
0.000193615984800 0.000550999085040 0.001590911133120 0.001307694572160
0.000082649862756 0.000580986306634 0.000468126441130 0.000886574705242
0.000087147945995 0.000188930307445 0.000375454095115 0.000381303448065
0.000028339546117 0.000166130708829 0.000144413313620 0.000226676301777
后向概率
从第 t t t 层算第 t − 1 t-1 t−1 层,可以认为是 x t x_t xt 按照概率 a i j a_{ij} aij 枚举了所有的可能。
最后一层是边界,特判。
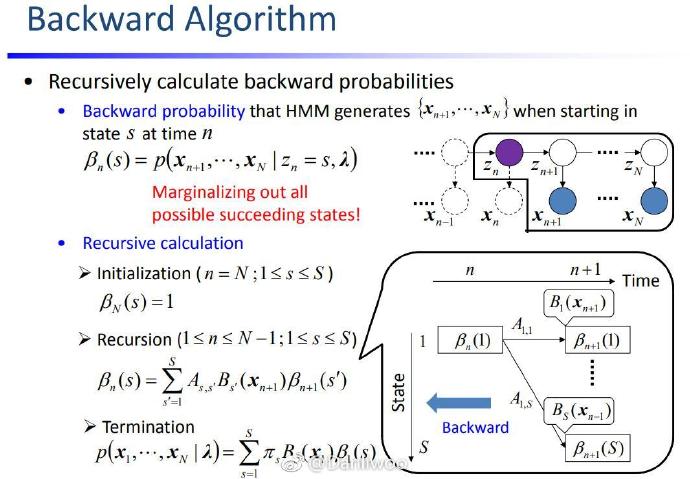
KaTeX parse error: No such environment: align at position 7: \begin{̲a̲l̲i̲g̲n̲}̲ \beta_t(i)=&P(…
β t ( i ) = { 1 t=T ∑ j = 1 N a i j b j k β t + 1 ( j ) t<T k = f i n d i n d e x ( x ⃗ t + 1 ) \beta_t(i)=\begin{cases} &1&\text{t=T}\\ &\sum_{j=1}^N a_{ij}b_{jk}\beta_{t+1}(j) &\text{t<T} \end{cases}~~~~~~~~k=findindex(\vec x_{t+1}) βt(i)={1∑j=1Naijbjkβt+1(j)t=Tt
def cal_beta(T, S, H, A, B, pi):
N = len(H)
bt = [1] * N
beta = [bt]
for t in range(T-2, -1, -1):
bt = []
for i in range(N):
sum = 0
for j in range(N):
sum += A[i][j]*B[j][S.index(X[t+1])]*beta[0][j]
bt.append(sum)
beta.insert(0, bt)
return beta
beta = cal_beta(T, S, H, A, B, pi)
for t in range(T):
for p in beta[t]:
print("{:.15f} ".format(p), end = "")
print()
0.000773808630386 0.002212140292340 0.001040581878103 0.001883466537801
0.003889091085768 0.002579362101288 0.003878039593987 0.003046076774784
0.005546129551200 0.005555844408240 0.006240866673600 0.006451119888000
0.007720551720000 0.018487098504000 0.010470861072000 0.016760061888000
0.031171644000000 0.025735172400000 0.032884171200000 0.030761001600000
0.038173800000000 0.103905480000000 0.047640720000000 0.085064640000000
0.198940000000000 0.127246000000000 0.176344000000000 0.134880000000000
0.301000000000000 0.284200000000000 0.293200000000000 0.268800000000000
0.700000000000000 0.430000000000000 0.640000000000000 0.480000000000000
1.000000000000000 1.000000000000000 1.000000000000000 1.000000000000000
前后向算法
结合前向和后向概率,对于中间的 x ⃗ t \vec x_t xt 前面用前向算法,后面用后向算法。
KaTeX parse error: No such environment: align at position 7: \begin{̲a̲l̲i̲g̲n̲}̲ P(\vec X|\lamb…
def forword_backword(alpha, beta, t, T, S, H, A, B, pi):
if t < 0 or t >= T:
return 0;
sum = 0
N = len(H)
for i in range(N):
sum += alpha[t][i]*beta[t][i]
return sum
for t in range(T):
print("{:2d}".format(t), "{:.15f}".format(forword_backword(alpha, beta, t, T, S, H, A, B, pi)))
0 0.000565559870343
1 0.000565559870343
2 0.000565559870343
3 0.000565559870343
4 0.000565559870343
5 0.000565559870343
6 0.000565559870343
7 0.000565559870343
8 0.000565559870343
9 0.000565559870343
有什么用
不论 t t t 的取值是什么,最后算出来的观测概率都是一样的。为什么要大费周章算第 t t t 个观测的情况,这里埋个伏笔。
预测问题
输入: X ⃗ , λ = ( A ⃗ , B ⃗ , Π ⃗ ) \vec X,\lambda=(\vec A, \vec B, \vec \Pi) X,λ=(A,B,Π)
输出: Z ⃗ \vec Z Z
在上面DP的过程中,记录第 t t t 层的第 i i i 个状态是前一层哪一个转移过来的,可以得到最优路径。
Viterbi算法
一开始我以为 Viterbi 算法和前向算法是一个东西,第 t t t 层的每个节点都计算了从第 t − 1 t-1 t−1 层过来的所有概率之和。
实际上 Viterbi 算的不是和,而是从 t − 1 t-1 t−1 层过来的 N N N 个概率的最大值。
前向算法好比是算最大流, α t ( i ) \alpha_t(i) αt(i) 是第 t t t 个时刻经过节点 h ⃗ i \vec h_i hi 的所有的可能。
Viterbi算法好比是求最短路,第 t t t 个时刻经过节点 h ⃗ i \vec h_i hi 的路径有好多条,只需要选择其中概率最大的一条。
σ t ( i ) = { π i b i k t=1 ( max 1 ≤ j ≤ N σ t − 1 ( j ) a j i ) b i k t>1 k = f i n d i n d e x ( x ⃗ t ) \sigma_t(i)=\begin{cases} &\pi_i b_{ik}&\text{t=1}\\ &\left(\max\limits_{1\leq j\leq N} \sigma_{t-1}(j)a_{ji}\right)b_{ik} &\text{t>1} \end{cases}~~~~~~~~k=findindex(\vec x_{t}) σt(i)=⎩⎨⎧πibik(1≤j≤Nmaxσt−1(j)aji)bikt=1t>1 k=findindex(xt)
在计算最值的过程中,同时记录了转移到第 t t t 个时刻节点 h ⃗ i \vec h_i hi 的上一层节点的标号。
def viterbi(T, S, H, A, B, pi, X):
N = len(H)
sg = []
parent = [0]
for i in range(N):
sg.append(pi[i]*B[i][S.index(X[0])])
for t in range(1, T):
sigma = sg
sg = []
pt = []
for i in range(N):
maxindex, maxvalue = [-1, 0]
for j in range(N):
if sigma[j]*A[j][i] > maxvalue:
maxvalue = sigma[j]*A[j][i]
maxindex = j
sg.append(maxvalue*B[i][S.index(X[t])])
pt.append(maxindex)
parent.append(pt)
for i in range(N):
maxindex, maxvalue = [-1, 0]
if sigma[i] > maxvalue:
maxvalue = sigma[i]
maxindex = i
parent.append(maxindex)
return parent
def get_solution(parent, T):
ind = [parent[T]]
ret = [H[ind[0]]]
for t in range(T-1, 0, -1):
p = parent[t][ind[0]]
ind.insert(0, p)
ret.insert(0, H[p])
return ret
parent = viterbi(T, S, H, A, B, pi, X)
result = get_solution(parent, T)
print('X: ', X)
print('true Z: ', Z)
print('viterbi:', result)
y = 0
for i in range(len(Z)):
if Z[i] == result[i]: y += 1
print('YES: ', y, ' NO: ', len(Z)-y)
X: ['red', 'red', 'white', 'red', 'red', 'red', 'red', 'white', 'white', 'white']
true Z: ['box4', 'box4', 'box3', 'box2', 'box1', 'box2', 'box1', 'box2', 'box3', 'box4']
viterbi: ['box1', 'box2', 'box3', 'box4', 'box3', 'box4', 'box3', 'box4', 'box3', 'box4']
YES: 3 NO: 7
错误率很高,准不准看心情。看来生成同一个观测的隐序列有好多条,概率大的那条和真实的那条,并不能保证更加重合。
预测缺失
输入: x ⃗ 1 , … , x ⃗ t − 1 , x ⃗ t + 1 , … , x ⃗ T , λ = ( A ⃗ , B ⃗ , Π ⃗ ) \vec x_1,\dots,\vec x_{t-1},\vec x_{t+1},\dots,\vec x_{T},\lambda=(\vec A, \vec B, \vec \Pi) x1,…,xt−1,xt+1,…,xT,λ=(A,B,Π)
输出: x ⃗ t \vec x_t xt
KaTeX parse error: No such environment: align at position 7: \begin{̲a̲l̲i̲g̲n̲}̲ \theta=&\arg\m…
先计算出所有的 α , β , \alpha,\beta, α,β,复杂度为 O ( T N 2 ) O(TN^2) O(TN2),再根据 x ⃗ t = s ⃗ k \vec x_t=\vec s_k xt=sk 更新出 α t ( i ) \alpha_t(i) αt(i),复杂度为 O ( N 2 ) O(N^2) O(N2)。 β t ( i ) \beta_t(i) βt(i) 不受 x ⃗ t \vec x_t xt 的影响,故不用更新。
分母是对两个隐变量进行积分。隐变量多一个,复杂度就要乘 N N N,尽量让隐变量越少越好。
def normalization(distribution):
sum = 0
for x in distribution:
sum += x
if sum == 0:
return distribution
ret = []
for x in distribution:
ret.append(x/sum)
return ret
def predict(T, S, H, A, B, pi, X, t):
alpha = cal_alpha(T, S, H, A, B, pi)
beta = cal_beta(T, S, H, A, B, pi)
N = len(H)
pd = []
for sk in S:
X[t] = sk
if t == 0:
for i in range(N):
alpha[0][i] = pi[i]*B[i][S.index(X[0])]
else:
for i in range(N):
alpha[t][i] = 0
for j in range(N):
alpha[t][i] += alpha[t-1][j]*A[j][i]
alpha[t][i] *= B[i][S.index(X[t])]
pd.append(forword_backword(alpha, beta, t, T, S, H, A, B, pi))
print(pd)
print('after normalization: ', normalization(pd))
theta = pd.index(max(pd))
return S[theta]
t = 0
xt = predict(T, S, H, A, B, pi, X, t)
print(X)
print('Truth: ', X[t], ' Result: ', xt)
[0.0005655598703429658, 0.0006961897150214642]
after normalization: [0.4482346393477241, 0.5517653606522758]
['white', 'red', 'white', 'red', 'red', 'red', 'red', 'white', 'white', 'white']
Truth: white Result: white
t = int(T/2)
xt = predict(T, S, H, A, B, pi, X, t)
print(X)
print('Truth: ', X[t], ' Result: ', xt)
[0.0006961897150214642, 0.0009353499840613047]
after normalization: [0.4267071867223662, 0.5732928132776338]
['white', 'red', 'white', 'red', 'red', 'white', 'red', 'white', 'white', 'white']
Truth: white Result: white
对 M M M 个结果归一化,若概率比较接近,则结果比较不准确。概率差的越多越准。
学习问题
输入: X ⃗ \vec X X
输出: λ = ( A ⃗ , B ⃗ , Π ⃗ ) \lambda=(\vec A, \vec B, \vec \Pi) λ=(A,B,Π)
常规用监督学习的样本来估计出参数,但标注费用比较高,因此用非监督的学习方法来做。
借助: P ( X ⃗ ∣ λ ) P(\vec X|\lambda) P(X∣λ)用最大似然估计参数,EM算法计算参数。
Baum-Welch模型
记给定观测和参数下的 z ⃗ t = h ⃗ i \vec z_t=\vec h_i zt=hi 的概率
γ t ( i ) = P ( z ⃗ t = h ⃗ i ∣ X ⃗ , λ ) = P ( z ⃗ t = h ⃗ i , X ⃗ ∣ λ ) P ( X ⃗ ∣ λ ) = α t ( i ) β t ( i ) ∑ i = 1 N α t ( i ) β t ( i ) \gamma_t(i)=P(\vec z_t=\vec h_i|\vec X, \lambda)={P(\vec z_t=\vec h_i,\vec X|\lambda)\over P(\vec X|\lambda)}= {\alpha_t(i)\beta_{t}(i)\over \sum_{i=1}^N \alpha_t(i)\beta_{t}(i) } γt(i)=P(zt=hi∣X,λ)=P(X∣λ)P(zt=hi,X∣λ)=∑i=1Nαt(i)βt(i)αt(i)βt(i)
记给定观测和参数下的 z ⃗ t = h ⃗ i , z ⃗ t + 1 = h ⃗ j \vec z_t=\vec h_i,\vec z_{t+1}=\vec h_j zt=hi,zt+1=hj 的概率
ξ t ( i , j ) = P ( z ⃗ t = h ⃗ i , z ⃗ t + 1 = h ⃗ j ∣ X ⃗ , λ ) = P ( z ⃗ t = h ⃗ i , z ⃗ t + 1 = h ⃗ j , X ⃗ ∣ λ ) P ( X ⃗ ∣ λ ) = α t ( i ) a i j b j k β t + 1 ( j ) ∑ i = 1 N α t ( i ) β t ( i ) k = f i n d i n d e x ( x ⃗ t + 1 ) \xi_t(i,j)=P(\vec z_t=\vec h_i,\vec z_{t+1}=\vec h_j|\vec X, \lambda)={P(\vec z_t=\vec h_i,\vec z_{t+1}=\vec h_j,\vec X|\lambda)\over P(\vec X|\lambda)}= {\alpha_t(i)a_{ij}b_{jk}\beta_{t+1}(j)\over \sum_{i=1}^N \alpha_t(i)\beta_{t}(i) }~~~~~~~~k=findindex(\vec x_{t+1}) ξt(i,j)=P(zt=hi,zt+1=hj∣X,λ)=P(X∣λ)P(zt=hi,zt+1=hj,X∣λ)=∑i=1Nαt(i)βt(i)αt(i)aijbjkβt+1(j) k=findindex(xt+1)
def cal_gamma(T, S, H, A, B, pi, alpha, beta):
N = len(H)
gamma = []
for t in range(T):
d = forword_backword(alpha, beta, t, T, S, H, A, B, pi)
gm = []
for i in range(N):
gm.append(alpha[t][i]*beta[t][i]/d)
gamma.append(gm)
return gamma
def cal_xi(T, S, H, A, B, pi, alpha, beta):
N = len(H)
xi = []
for t in range(T-1):
d = forword_backword(alpha, beta, t, T, S, H, A, B, pi)
tx = []
for i in range(N):
ty = []
for j in range(N):
ty.append(alpha[t][i]*A[i][j]*B[j][S.index(X[t+1])]*beta[t+1][j]/d)
tx.append(ty)
xi.append(tx)
return xi
算法步骤:
- 初始化模型参数 λ = ( A ⃗ ( 0 ) , B ⃗ ( 0 ) , Π ⃗ ( 0 ) ) \lambda=(\vec A^{(0)}, \vec B^{(0)}, \vec \Pi^{(0)}) λ=(A(0),B(0),Π(0))
- 递推
KaTeX parse error: No such environment: align at position 7: \begin{̲a̲l̲i̲g̲n̲}̲ a_{ij}^{(n)}&=… - 反复迭代直到结束。
def BaumWelch(T, S, H, A, B, pi, X):
alpha = cal_alpha(T, S, H, A, B, pi)
beta = cal_beta(T, S, H, A, B, pi)
gamma = cal_gamma(T, S, H, A, B, pi, alpha, beta)
xi = cal_xi(T, S, H, A, B, pi, alpha, beta)
N = len(H)
M = len(S)
for i in range(N):
pi[i] = gamma[0][i]
for j in range(N):
a = 0
b = 0
for t in range(T-1):
a += xi[t][i][j]
b += gamma[t][i]
A[i][j] = a / b
for j in range(N):
for k in range(M):
c = 0
d = 0
for t in range(T):
if X[t] == S[k]: c += gamma[t][j]
d += gamma[t][j]
B[j][k] = c / d
T = 100
S = ['red', 'white']
H = ['box1', 'box2', 'box3', 'box4']
A = [
[0, 1, 0, 0],
[0.3, 0, 0.7, 0],
[0, 0.4, 0, 0.6],
[0, 0, 0.6, 0.4]
]
B = [
[0.5, 0.5],
[0.3, 0.7],
[0.6, 0.4],
[0.4, 0.6]
]
pi = [0.4, 0.1, 0.25, 0.25]
Z, X = observation(T, S, H, A, B, pi)
print(Z)
print(X)
['box3', 'box2', 'box3', 'box2', 'box3', 'box2', 'box3', 'box4', 'box3', 'box2', 'box3', 'box4', 'box3', 'box4', 'box4', 'box4', 'box4', 'box3', 'box2', 'box3', 'box4', 'box3', 'box2', 'box3', 'box4', 'box3', 'box4', 'box4', 'box3', 'box4', 'box3', 'box2', 'box1', 'box2', 'box3', 'box4', 'box4', 'box4', 'box4', 'box3', 'box2', 'box3', 'box4', 'box3', 'box2', 'box1', 'box2', 'box3', 'box4', 'box3', 'box2', 'box3', 'box2', 'box3', 'box4', 'box3', 'box4', 'box4', 'box3', 'box2', 'box3', 'box2', 'box3', 'box4', 'box3', 'box2', 'box3', 'box2', 'box3', 'box4', 'box3', 'box4', 'box3', 'box2', 'box3', 'box2', 'box3', 'box4', 'box3', 'box4', 'box3', 'box4', 'box3', 'box2', 'box1', 'box2', 'box3', 'box4', 'box3', 'box4', 'box3', 'box2', 'box3', 'box2', 'box1', 'box2', 'box1', 'box2', 'box1', 'box2']
['red', 'red', 'white', 'white', 'white', 'red', 'white', 'white', 'red', 'white', 'white', 'red', 'red', 'red', 'white', 'white', 'white', 'white', 'red', 'red', 'white', 'white', 'white', 'white', 'white', 'white', 'white', 'red', 'red', 'white', 'red', 'red', 'red', 'white', 'red', 'white', 'red', 'red', 'white', 'white', 'white', 'red', 'white', 'red', 'white', 'white', 'red', 'white', 'white', 'white', 'red', 'red', 'red', 'white', 'red', 'red', 'red', 'white', 'white', 'white', 'red', 'white', 'white', 'white', 'red', 'red', 'white', 'white', 'red', 'white', 'red', 'red', 'white', 'white', 'white', 'red', 'red', 'white', 'red', 'white', 'white', 'red', 'red', 'white', 'white', 'white', 'red', 'red', 'white', 'white', 'white', 'white', 'white', 'red', 'red', 'white', 'white', 'red', 'white', 'white']
N = len(H)
M = len(S)
for i in range(N):
pi[i] = 1/N
for j in range(N):
A[i][j] = 1.0/N
for i in range(N):
for j in range(M):
B[i][j] = 1.0/M
for n in range(100):
BaumWelch(T, S, H, A, B, pi, X)
print('A = ')
for a in A: print(a)
print('B = ')
for a in B: print(a)
print('pi = ', pi)
A =
[0.0, 1.0, 0.0, 0.0]
[0.21637727805699658, 0.0, 0.7836227219430034, 0.0]
[0.0, 0.6051469829325692, 0.0, 0.39485301706743037]
[0.0, 0.0, 0.6769960992962581, 0.3230039007037422]
B =
[0.48756529151325756, 0.5124347084867421]
[0.306148553047875, 0.6938514469521249]
[0.3764958640717598, 0.6235041359282399]
[0.6142054230463997, 0.38579457695360075]
pi = [5.587468792089893e-15, 2.130883301703395e-14, 6.711160249392918e-10, 0.9999999993288571]
A = [
[0, 1, 0, 0],
[0.3, 0, 0.7, 0],
[0, 0.4, 0, 0.6],
[0, 0, 0.6, 0.4]
]
B = [
[0.5, 0.5],
[0.3, 0.7],
[0.6, 0.4],
[0.4, 0.6]
]
pi = [0.4, 0.1, 0.25, 0.25]
for n in range(100):
BaumWelch(T, S, H, A, B, pi, X)
print('A = ')
for a in A: print(a)
print('B = ')
for a in B: print(a)
print('pi = ', pi)
A =
[0.0, 1.0, 0.0, 0.0]
[0.2372692138083878, 0.0, 0.7627307861916122, 0.0]
[0.0, 0.5602614297254132, 0.0, 0.4397385702745865]
[0.0, 0.0, 0.6536645510734121, 0.3463354489265881]
B =
[0.47272997015685325, 0.5272700298431463]
[0.3117562813075025, 0.6882437186924975]
[0.3790562578502942, 0.6209437421497058]
[0.5767285822570875, 0.42327141774291277]
pi = [8.747202600039793e-13, 1.5092161955244595e-11, 9.621844637309934e-08, 0.9999999037655867]
展望
- viterbi和学习参数效果挺差的,看点相关论文学习优化
- 老板说要结合多视角啊
- BW算法推导的地方有空再补上