Spark 2.0技术预览
Spark 2.0预览版已出,本文将带你浏览下这个2.0到底有啥流逼的地方。
在正式发布之前,你可以
1. github下载自己编译 https://github.com/apache/spark
2. 官网最下方有个很小的连接
3. https://databricks.com/try-databricks 可以创建预览版集群
本次大版本更新包含三个主题,Easier,Faster,Smarter。
Easier
首先我们看看Easier。Easier的方面主要集中在SQL和流处理方面。
犹如C++编译器会标榜自己对C++标准的支持程度,标准SQL是每个SQL On Hadoop系统都会拿来宣传的看点(如果的确做得不错)。在Spark 2.0中,SQL标准支持得到很大强化。
进一步解释这部分之前,需要先说一下Spark SQL的Parser。Spark SQL有一个原生的Parser通过SQLContext暴露。这个Parser在1.x时代是个很原始的作品,例如在Spark 1.6时,Spark SQL原生Parser可以通过55/99的TPC-DS测试(一个数据分析场景的SQL引擎Benchmark测试),将近一半的测试由于SQL标准兼容问题无法通过。
而Spark SQL内嵌了一个Hive Parser,基本重用了Hive相关的大量代码,这个接口使用HiveContext暴露。大多数用户由于种种兼容问题和功能原因会选择Hive Parser。这样的内嵌模式,对SparkSQL来说带来了不必要的Hive耦合,这部分代码很难维护也不容易增加新的特有功能。
在2.x时代,由于Parser的重写,标准兼容问题得到解决,Spark将逐渐切换到SQLContext。更具体的,在2.0里,99个TPCDS全都能跑通了。
主要增加的支持是:
1. rollup和cube
2. intersect和except
3. select/where/having中使用子查询,例如 select * from t where a = (select max(b) from t2)
4. 窗口函数支持
5. IN、EXIST谓词支持子查询 where col in (select …)这样
6. natural join (根据字段名自动匹配join)
这些对于习惯HiveContext的用户来说可能不是一个值得大书特书的东西,但是这个标志着Spark和Hive会逐渐解耦,甚至完全独立,而SparkSQL的功能演进将会更自由。
Easier主题的第二个更重要的部分是API大一统。Spark API演进文档
由于Spark的快速迭代和演进,Spark暴露的API体系越来越多,很多是实现类似功能的,有些是由于原有API不方便又要向下兼容而另开了新坑,这些都将在2.0进行整合。
这部分整合包含了:
1. HiveContext,SQLContext以及SparkContext将整合到SparkSession中。SparkSession将成为大入口,包含Dataset生成,Catalog支持(包含Spark本身的Catalog和Hive Catalog支持),配置相关接口和集群环境相关接口。
Dataset和Dataframe整合:Dataframe将被整合进Dataset API。
Streaming API和Batch整合:同一套API用于Streaming和Batch。在此之前只能用流API加原生的RDD API进行流计算。RDD API是Spark最早的原生API,抽象程度较低,也没有Schema。这部分也是Smarter的主要内容,之后会做更多论述。
Java API和Scala API整合:在此之前Java有自己的JavaRDD接口。现在都将使用Dataset API。
这里需要大概介绍一下RDD,Dataset和Dataframe。
RDD原生API是Spark最早的API体系,它类型安全,操作有序,但是是非常底层的API。它的代码类似如下:

Dataframe API是在Row集合上的操作,而Row可以理解成类似数据库的记录行,将数据切分成多个列,每个列有自己的名字。所以DataFrame的操作更类似数据库API,是将原生RDD API的抽象和打包。更主要的是,DataFrame由于接近SQL的API模型,将完全享受Catalyst优化器(Catalyst是SparkSQL的优化器,类似数据库引擎的执行计划优化模块),而原生的RDD由于过于自由的API,则无法享受这一优化。考虑C++和汇编,由于C++是高级语言,比汇编有更多限定,因此编译器可以更多进行优化,这里是类似的道理。
DataFrame的坏处是,动态类型。因为解析的时候Schema还没有注入,无法完整静态类型检查,因此无法做到类型安全。
DataFrame的代码是这样的:

而DataSet API则是类型安全的类数据库API。DataSet支持lambda API(比如x => x + 1这样),有类型支持并享受Catalyst优化。又由于它也有Schema支持,因此存储的时候能根据类型序列化到Native内存上(而非Java堆空间),无须使用Java Object,因此速度更快更省内存。
这里附一份官网的图

它的代码看起来这样:

对比RDD原生操作:

在2.0中,DataSet和DataFrame进行了整合,DataFrame将成为DataSet[Row]的同义词,底层使用同一套API。这套API将作为Structured Streaming统一API。
由于编译器类型检查在R和Python中无效,因此Dataset只用于Scala和Java。
API分为Typed和Untyped

Untyped
![]()
Faster
第二个大主题是Faster(更快)。其中最主要的一个变更是WholeStage CodeGen。
SparkSQL会将一个Plan拆分成不同Operator的组合。例如从官网上摘抄的例子:
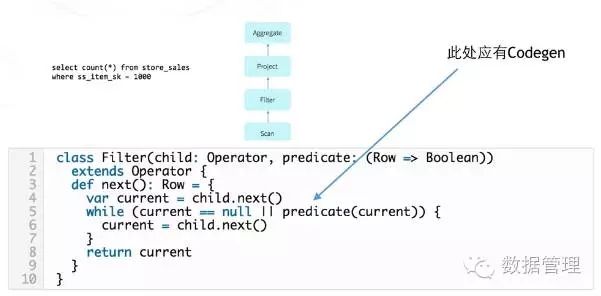
也许你知道Spark 1.x时代,对于某些SQL Operator,Spark会进行独立的代码生成,每个Operator的代码段互相之间并不直接关联,这样做实现看起来比较优雅和简洁,生成的代码也有一定的封装性,看起来妥妥滴软件工程设计,但是,慢。
2.0新增的一个很重要优化是就是在这块做文章。新的代码生成器在可能的情况下将把不同的Operator放在一起生成一个大块的处理函数。这样的好处是,去掉了冗余的operator之间的数据传递(这个可能是性能开销的大头),并且一个大的代码段不跨越函数边界,将更优可能被JVM JIT优化。终极目标是,生成的代码和手写代码有近似的速度。
看一下下面这个例子:
select id + 1 from students where id <> 0;
上面的Plan的计算部分将会有两个Operator:id+1对应Projection Operator,id <> 0对应Filter Operator。新的Spark代码生成可以将这两个部分生成一个大的代码块进行计算。
这里一些看起来奇怪的标志位是用来做NULL判断的。这点是CodeGen比较麻烦的地方,因为为了速度,CodeGen会将Row中的数据读取到Primitive的Java变量中,而Primitive类型是无法接受空值的。但是SQL语义中空值是可以参与计算的,要保持这一语义,必须做一些奇奇怪怪的标志位对空值做处理。另外由于代码是跟着AST进行生成的,因此id<>0将产生两步骤计算:先计算id=0然后取反。

再看聚合操作。新的聚合代码生成看起来更像一个手写聚合的代码框架,一个大循环迭代一大批数据。
select sum(id + 888) from students where id <> 999;

除了WholeStage CodeGen之外,向量化是另一个大的优化点。所谓向量化是说,一次返回一组列的值在一次函数调用中一起处理,这样能减小虚函数调用次数并可以做SIMD加速(一个指令多个数据同时处理,CPU级优化)。这个优化和Wholestage codegen并不共存。用在例如Parquet Reader的解码部分。
Smarter
最后是Smarter主题(更智能)。这里主要是说之前提到的Batch和Streaming API统一。
2.0新的Streaming API超越了之前独立Streaming框架的范畴,与Batch处理合二为一,让同一套API框架得以作用于流计算和批处理。其中的哲学是:简单的方式对流数据进行计算,而不用考虑这其实是一个流。
这包含了:
1. Dataset API能描述Streaming,而不再用Dstream
2. 直接对Streaming进行Ad-hoc SQL查询(SQL运行时可变)
3. 直接对Streaming进行机器学习(2.1)
4. 用Catalyst优化器对流计算进行优化
5. 统一的模型将统一享受未来的Tungsten优化(包括刚才提到的Codegen等)
Structured Streaming JIRA
https://issues.apache.org/jira/secure/attachment/12793410/StructuredStreamingProgrammingAbstractionSemanticsandAPIs-ApacheJIRA.pdf
设计文档
https://issues.apache.org/jira/browse/SPARK-8360
上面两个是JIRA和设计文档,到2016-5-27为止Ticket本身还没关闭。
这个文章提出了一个模型:Repeated Queries (RQ)
这个模型尝试让Streaming上的Query犹如在静态表上查询一样,并尝试将静态查询的概念一一映射到流查询上。
逻辑上来说,streaming是一个append-only表,数据根据系统处理时间到达(这个时间是表的一个字段)。而查询就是在这个表上进行的。
用户创建基于处理时间的触发条件(支持ASAP,到达就处理)
用户定义输出模式,可以是delta(只输出增删),append模式(只增不减),或者Update模式(在线修正,比如更新数据库),或者快照(每次全量)。
相对于很流行的Storm和老版本的DStream来说,RQ模式更灵活也更方便。
Storm API过于底层,难于开发。本身又难以支持基于事件本身时间(相对于事件到达时间)的处理模型。底层处理模型是来一条处理一条(除非外加Trident)。
Dstream也使用系统处理时间,也难于支持事件时间。而底层使用micro-batch模型。并且现有API相对DataSet API也偏底层,开发不灵活。
新的RQ模型支持处理时间和事件时间,并且和底层处理模型无关,还可以支持micro-batch之外的其他处理。另外比较重要的是RQ享受Catalyst查询优化(任何DataSet API入口的程序都可以享受Catalyst优化甚至其他大多数为SQL进行的优化)。
这里贴几个文档附带的范例:
ETL-输入小写规整

数据库和流同步

好了,上面就是Spark 2.0的一些新东西,更多东西只能亲手尝试才能体会了。
数据管理公众号
