Hadoop-Spark之路01_集群的安装和部署
前言
最近公司说要用Hadoop-Spark做个东西,可是公司不给批Linux服务器。。。。(所以IDC这个部门只是专门用来找麻烦的吗?)没办法,需要自己先弄个小Demo出来,认为可行才会给批服务器。。。(╯‵□′)╯︵┻━┻
没办法,从头开始学吧。
一、前期准备
环境:一台Linux系统的虚拟机(有更多的就更好了,没有的话一台也可以演示)
Hadoop安装包:版本3.1.2 下载地址(清华的镜像):http://mirrors.shu.edu.cn/apache/hadoop/common/
JDK:版本1.8 下载地址(选择Linux版本的):https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
二、开始搭建
我选择的Linux发行版是CentOS7,开了两台虚拟机。那么就开始吧。
关于虚拟机网络的配置,我选择的是NAT网络地址转换然后配置静态IP,关于这部分不想赘述。那么从搭建环境开始。
1.防火墙设置
关闭防火墙:service iptables stop
关闭防火墙自启: chkconfig iptables off
(如果你是一个学生没有面试过的话,建议了解一下Linux防火墙设置,面试可能会问到)
2.安装jdk
将jdk安装包上传到Linux中(我使用的软件是Xmanager)
将安装包放到 /usr/lib/ 目录下,解压安装包。
vi /etc/profile 在文件末尾追加以下内容(注意jdk目录换成你的版本的)
export JAVA_HOME=/usr/lib/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
保存后退出,执行 source /etc/profile使环境变量生效。
3.集群内主机的域名映射配置
vi /etc/hosts (注意配置成你自己的机器名和ip地址)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.101.11 kanadem1
192.168.101.12 kanadem2
然后,将hosts文件拷贝到集群中的所有其他机器上
scp /etc/hosts kanadem2:/etc/
4.安装HDFS集群
4.1上传hadoop安装包到一台机器的/apps/hadoop/ 目录并解压
4.2 修改hadoop-env.sh (这个文件在hadoop安装目录的etc/hadoop/下,如果不修改之后会报错)
在文件末尾追加 export JAVA_HOME=/usr/lib/jdk1.8.0_191
4.3 修改core-site.xml (指定Hadoop的默认文件系统,以及NameNode)
4.4 修改hdfs-site.xml (指定数据文件位置)
4.5 拷贝整个hadoop安装目录到其他机器
scp -r /apps/hadoop/hadoop-3.1.2 kanadem2:/apps/hadoop/
4.6 启动HDFS
首先要配置hadoop的环境变量
vi /etc/profile
修改结尾内容为:
export JAVA_HOME=/usr/lib/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_HOME=/apps/hadoop/hadoop-3.1.2
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改完成后source /etc/profile
然后在要运行namenode的机器上执行:hadoop namenode -format
接着执行 hadoop-daemon.sh start namenode 然后可以在浏览器输入对应机器的9870端口号查看状态。
注意启动的脚本有很多个,并且使用这个脚本的时候会有一个提示信息如下:
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
提示说用不赞成用这个脚本。
那还有另一个脚本 start-dfs.sh 可以执行这个脚本,但是执行这个脚本的话无法用root用户执行,你需要先建一个其他用户,当然为了省事,既然前面的命令也没有报错就暂时不用管了。(推荐还是建一个用户来运行hadoop程序,root虽然可以避免很多的权限问题,但是并不是一个推荐的方案。)
接下来在要启动datanode的机器上执行: hadoop-daemon.sh start datanode (namenode的机器也可以启动datanode)
4.7 用自动批量启动脚本来启动HDFS
上面的启动方法有些费事,可以通过脚本来一次启动所有机器,这一步需要配置互信,这一步也不在这里描述,网上有很多教程。
在hadoop安装目录下的etc/hadoop/workers写入要启动的机器即可(以前这个文件叫slaves,确实不是个好听的称呼)

然后执行 start-dfs.sh启动集群,如果要停止的话执行 stop-dfs.sh (如果是root的话执行命令会报如下错误)
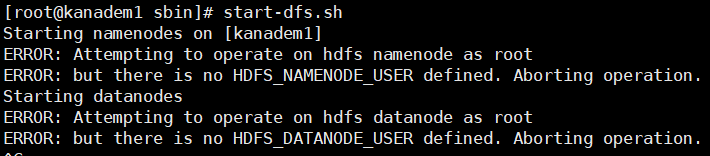
建议创建一个其他用户比如叫hadoop就可以避免这样的错误(这时注意/apps的目录所有者和组应该给hadoop),当然也有其他办法可以以root身份启动hadoop但是不推荐,因为以root用户上传文件的话,用户会标记为root,在namenode的页面上是无法直接下载的。
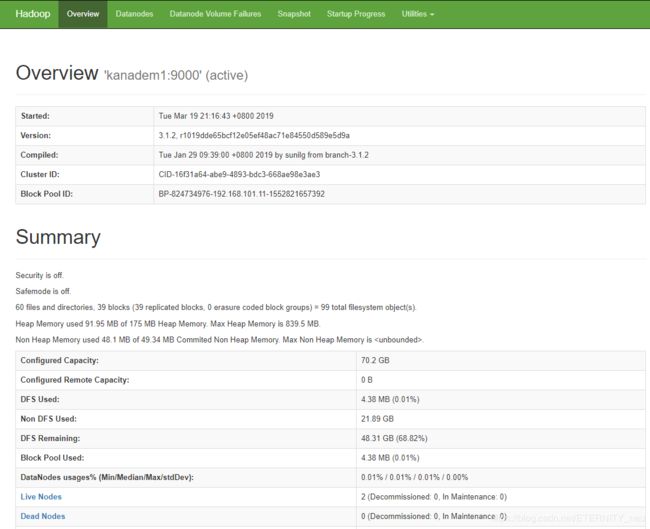
到这里NDFS就搭建好了,附页面图: