演讲实录:MySQL 8.0 中的复制技术

在近期的第七届数据技术嘉年华上,甲骨文MySQL研发工程师宋利兵做了“MySQL-8.0中的复制技术”为主题的演讲,介绍了MySQL-8.0中异步复制和Group Replication复制的发展方向,和已经实现了的新技术新特点。我们再次分享出来,希望对各位有所指导借鉴。
01
定义
02
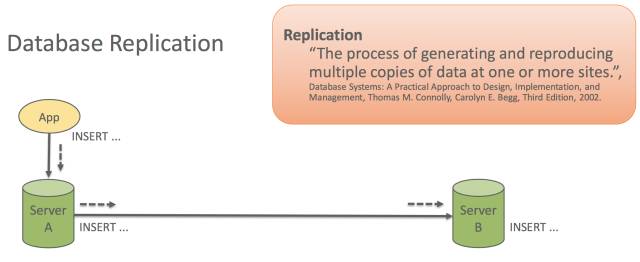
MySQL复制技术的简单框架

首先在复制环境中,有两个server,在第一个server中产生binary log,通常将这一个server成为master,另外一台server会将master上的binary log复制过去,然后通过日志的应用,产生和master一样的数据库,这就是复制的基本理论。其基本流程如下:

当应用在master数据库上执行SQL语句,这些操作会被数据库捕捉并以event的形式写到binary log里面,并以文件的形式存储。通过通讯模块,这些event会被发送到swill上,swill上的接收线程,接收到这些event,然后存储到Redo log,接着由读取线程,读取这些event,并行地在复制数据库中执行,这样就产生和master一样的数据库。
binary log是MySQL复制的基础,MySQL的这些日志称为逻辑日志,里面记录的是SQL语句级别的,操作的是表中的行数据,它不关心数据在引擎里面是怎么存储的,存储格式是什么样的。

binary log有两种模式
一种是ROW format
一种是statement的格式
statement的格式很好理解,就是当SQL语句执行的时候,将语句以文本的形式存储在event里面,然后在slave上也是以SQL语句执行。 ROW格式是针对操作表的DML语句,ROW格式不记录原始的语句,而是把涉及到的行的内容记录到event里面去。两者相比,ROW格式的安全性更高,而statement的话有时候是依赖于环境的,比如会使用到随机数函数,这些函数在master和slave上执行的结果可能是不一致的,用ROW格式表示的是最后的结果,直接将最终的数据复制过去,所以不会产生这个问题。
另外ROW格式到slave上不需要做SQL解析,性能会更好一些。在8.0版本中,缺省的格式就是ROW的格式。
对于event,是由SQL语句组成的,是语句级别的。一般一个事务由很多个event构成。 一般在事务的开头,会有一个CTID event,这是一个全局唯一的ID号,接下来是一个begin的event,接下来是一系列的语句产生的event,最后以一个commit 的event构成。
上图对于ddl语句来说的话,就没有begin和commit。
我们看到,在binary log中存储的时候,一个事务是一个最小的存储单位,事务里面所有的语句都是顺序的,连续第存储在日志中的,不会出现两个事务的event穿插在一起。 除了事务产生的event之外,还有一些event是用来做控制的。
03
复制的三种模式
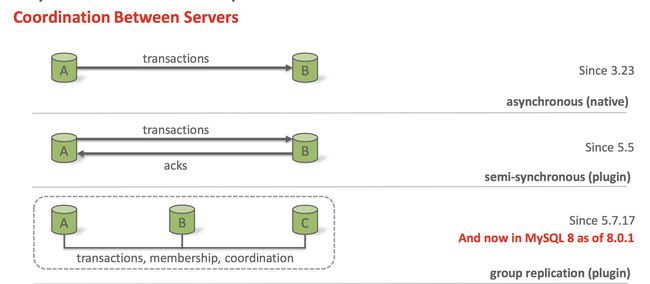
在很早以前,MySQL就引入了异步复制,从3.23的版本就开始了。异步复制是为MySQL的使用,以及保障MySQL中数据的高可用起到了很直观的作用。一直到现在,也一直在使用异步复制的模式,随着用户越来越多,使用场景越来越多,对复制技术也提出了更高的要求。在之前的异步复制模式中,事务的执行过程与语句的传输过程是完全隔离开的。master只管做它的操作,而不用去在乎数据是否传输到slave了。 这样的模式在一些对数据的可靠性要求很高的场景就会有问题,有可能会出现,用户发现我的数据都已经提交了,但是如果当master节点宕机切换到slave节点后,用户的数据不存在。
因此在5.5版本中引入了半同步复制,在半同步的极致中,事务执行的过程与event传输的过程是相关的,在master上,事务在写完bin log之后,是不会立即提交的,要等待它所产生的event已经被复制到其他节点之后并且其他节点已经给了应答,才会进行提交,这样就能保证所有用户提交的数据都能够在其他节点看到,这样可靠性就更高。
在5.7.17版本中,引入了新的复制模式叫做 group replication,在8.0中也有保留,GR和异步复制,和半同步复制比起来的话,有三个很明显的优势:
一是可靠性更高,主要体现在 GR中不会出现脑裂的情况。或者当网路中出现脑裂的情况的时候,不会产生不一致的数据,可以保障数据的一致性;
二是GR可以多写,支持多个节点或者所有的节点同时写。但并不会产生不一致的数据。
三是GR有组的概念,因此有许多组的自我管理的功能,在前两种复制方法中,都需要第三方的工具挥着程序来维护节点间的操作,比如做failover的时候,而在GR中,这些管理自己都可以完成。因此特别适合当前的大规模数据使用MySQL集群。
随着互联网的发展,云计算的发展,现在MySQL大部分都是采用集群的方式提供服务,因此集群使用MySQL的时候会有很多新的要求和特点。我接下来将会分几个类别介绍MySQL使用集群的场景。
01
replicate
这是最基本的一种,也就是高可用的架构。
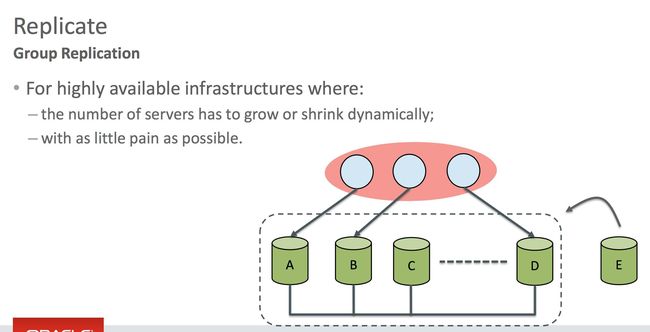
高可用在以前都是使用异步复制和半同步复制,随着8.0的发布,GR方案越来越成熟,我们可以预计到更多的用户是使用group replication来作为最基本的高可用单元,由于上述提到的三个比较明显的优势,我们也推荐使用GR。
02
Automate

第二点,在大规模的使用集群的时候,我们也期望通过自动化来减少人力成本并提高效率。在GR中,本身就包含了许多自动化的功能。这主要是得益于组的概念,在整个集群中,每个节点都知道自己是在一个组里面,也能够知道所有其他节点的状态信息,因为他们之间是相互通讯的。在这种情况下,如果是出现了主节点的宕机,其他节点都会尽快感知到,并重新选出新的节点作为主节点。
GR的多写有两种模式,单组的模式主要用于异步方式的替代。在异步的复制里面,如果宕机的话,还需要通过工具或者程序去检测宕机,但GR能够自己感知到。并且不会出现两个节点同时在线或者数据不一致的情况。
03
数据的集成——Integrate
在数据库中存储了大量的数据,现在越来越多的企业在做数据的分析,在MySQL 的GR中,一种方案是是binary Log中的数据导出来,并重新导入到其他的平台进行分析,在这个过程中,我们加入了很多的元数据信息进来,让用户更好地了解数据所代表的含义。方便用户做相应的数据转换。
04
做远程的灾备
对于物理距离跨度较大的,可以通过异步的复制方式进行传输,对于大批量的数据读取,在性能上也有较大的提升。

GR是一个基础的高可用的架构,也可以在此基础上,做一些读数据的性能扩展。但这方面会受到一定的限制。
由于存在组的管理,如果要将组里面的数据复制出去,或者从其他节点把数据复制到组里面,都是支持的,因此可以很方便地结合异步复制和Group Replication的使用。
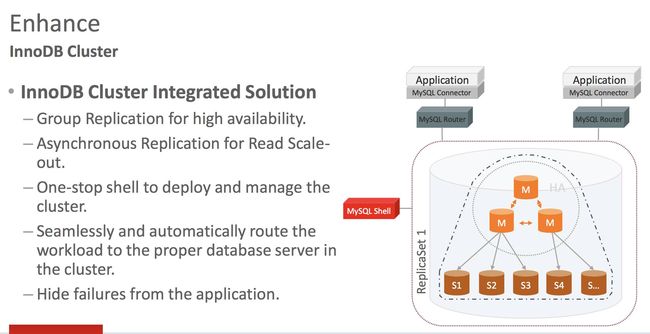
当然,MySQL一直在致力于做一个完整的解决方案,因此推出了 InnoDB Cluster,InnoDB包括的组件有:shell, rooter,还有以 group replication为核心的高可用的集群,因为GR知道组的概念,因此在shell里面集成了Cluster的概念在里面,包含 Cluster管理的功能和命令,因此在部署InnoDB d cluster会很简单容易,而通过rooter则实现负载均衡,读写分离等功能。这样就构成了一个完整的数据库的集群系统,而不需要任何的第三方工具。
接下来我们介绍8.0中在复制技术上的新特性。
主要包含以下几个方面:

01
binary log中的元数据

元数据的作用一方面是让用户更方便地抽取数据,另外对于MySQL自身的复制也有帮助,比如说可以做字符集的转换,可以很准确地判断master和slave的数据类型是否一致,当然这些功能目前还没有完全实现,目前只是在binary log里面放置了更丰富的元数据信息。
这些元数据主要分为两类。
一类是在GTID event里面增加了元数据。另一个是事务的长度,也就是事务中所包含的所有event加起来的长度。还增加了commit event中的时间戳。这里的时间错是毫秒级别的,方便我们监控数据复制的延迟。
第二类是table map event主要是增加了各个字段的具体类型,有没有符号,所属的字符集,还包括列的名字,主键,枚举型和集合型的字符串的值。都会记录到元数据信息里面。这样在抽取数据的时候就可以准确地知道数据的类型,会非常方便。
02
操作上的新特性

这里有一个很重要的就是多元复制,利用多元复制的很多场景就是主要用来做数据的聚合,有一种场景是我只要某个表的一部分数据,或者是一些做了分片的表,如果需要做聚合的话,就首先需要做过滤,而在8.0中,主要是在过滤功能上做了很多增强。每个通道可以设置自己的过滤策略。
例如在图中,在A节点有三张表,B节点有其他的表,可以单独制定规则为:从A到B的数据复制,三张表全部复制,而从B到C的通道,则指定规则为不复制user的表。
而Group Replication则会保护数据系统,保证每个节点都不会被意外地更新。

一个节点要加入到组里面再到生效,是需要一个过程的。首先要将节点加入到网络里面,使节点能够互相感知,之后才能加入到组里面。有可能在加入网络之后,还没有加入到组里面,此时应用已经发现了这个节点,或者直接将信息发给这个新的节点了,这时候很可能会产生数据不一致。
因此为了保证组内节点间数据的一致性,需要在将节点加入网络前先将其属性设置为 read-only,而等他加入之后,会根据自己的角色,自动地进行角色的切换,也就是说不需要将它read-only的属性再手动修改。比如如果它在组中是slave角色,就保持read-only,如果它被选为master,则会切换为read-write。
当一个节点离开组的时候也是一样的原理,会自动切换自己的属性。也就是说当它不再组中的时候,如果管理人员忘记将它删除,也没有关系,因为它的属性会自动被切换为read-only,即使把数据发给它,它也不会接收的。
集群里面有很多的机器,这些机器之间,可能他们的机器配置,地理位置等信息都是不一样的,这时候用户可能有不同的数据操作需求,比如需要特定地理位置的,或者特定配置的。希望将这些具有某些相同属性的节点选为组,因此在8.0中增加了一个功能就是用户可以设置每个节点的权重,这个参数就是 Group Replication Election Weights,可以对每个节点做独立的权重配置,在选举的时候,权重最大的节点会被选取为master节点。

03
句群管理的流控机制

在集群中,我们希望各个节点间的数据都是同步的,没有延迟。但可能因为一些意外的情况导致数据延迟,因此我们加入了更多的参数在里面,用户只需要对参数进行调整和配置。当集群发现存在数据不同步的现象时,会自动地做流控。
04
监控方面的新特性

刚才我们提到了在GTID的event里面加了commit的时间戳,这个时间戳是毫秒级的,因此可以在毫秒级别监控复制的延迟。有两个时间戳,第一个是最初产生事务的event对应的时间戳,所有的节点在完成事务,在记录binary log的时候,会把这个时间戳保留。另外在节点上,还会记录一个自己的时间戳。因此,通过对比就可以知道两个节点之间的延迟。这样就可以方便地监控每两个节点之间数据传输的延迟.

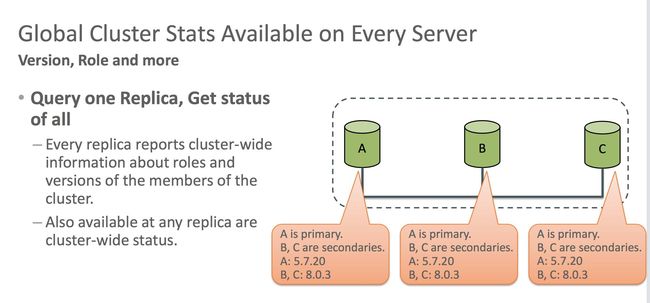
在组之间的节点数据同步方面,一般来说,对于一些业务逻辑复杂的, 比如节点在加入组的时候,对于新节点的数据复制,本身就是通过异步复制来完成的。8.0中对于Group replication的监控也做了一些增强,在replication Group Member的表,增加了一些字段,可以在任何节点上查到所有节点的状态信息。能够更好地监控组成员的信息,包括哪个节点是master,哪个节点是slave,所有节点的版本信息。
05
性能方面的新特性
在性能上最重要的一个特性是基于 writeset的并发策略。

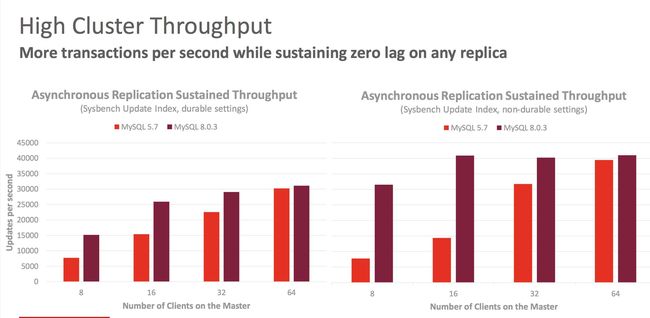
writeset本质上就是基于主键的,或者说是基于行的并发策略。如果两个事务修改了不同行的数据,由于主键不同,就可以并发执行。在此时执行就会有一个明显的特点。当master上只有一个线程的时候,在slave上的并发执行性能会比较高,比master上会高很多,master上只有少数的线程,并发量不是很大的时候,slave上的性能页还保持较好,这是因为在一个线程上的事务,只要是修改不同的行,互相不会影响的。因此基于writeset的并发机制,在slave上都会以最大并发的方式执行。
在有些用户场景下,我们可能会希望同一个session里面,不能做并发执行。因为可能与某些业务逻辑冲突。因此还有基于writeset的另一种机制。会判断是否是同一个session的事务。如果是同一个session的,则会进行顺序执行。
writeset最大的好处是:当slave要追master的数据,或者创建了一个新的slave需要同步之前的数据的时候,可以极大地提高性能。
以下是不使用和使用writeset的性能对比测试。
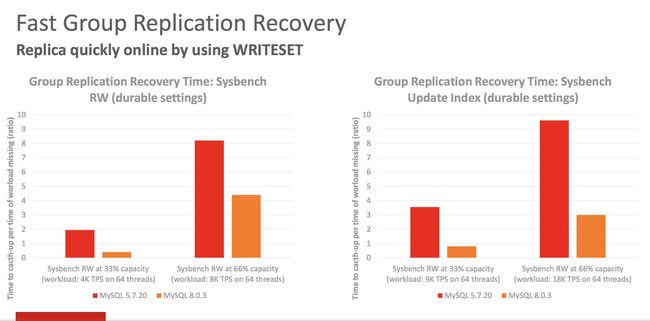
总的来说,当master上的线程数量不是很多的时候,writeset会起到比较好的性能改善作用。
06
针对JSON文档支持的一个新特性
JSON在MySQL中本质上是以block或者text的字段形式来存储的,一般会比较大,但我们在更新的时候常常只更新其中很小的一部分。以前在更新的时候,会把整个字段都存储到binary log中再进行修改,这样占用的空间就比较大。如果应用完全使用JSON的方式的话,就会造成很大的空间浪费。在8.0 中,在将内容加入到binary log之前会检测,这个字段到底更新了多少,在binary log中只记录一部分。

从上图可以看出,对于空间的节省还是很明显的。以下是对partial JSON的性能测试结果:根据JSON对象修改的比例,性能也有一些差异。

07
其他方面的新特性



MySQL后续的版本计划

最终期望达到的目标

更多内容请关注公众号后回复关键字“2017DTC”获取嘉宾演讲视频。
随着技术的发展,数据在企业中的价值日益凸显,由ACOUG和云和恩墨主办的数据技术嘉年华,围绕数据及数据库领域的核心技术,分享前沿资讯、干货技术,企业变革之路与战略方向,邀你一起探索数据价值,共创未来! 第八届数据技术嘉年华将于2018年11月16日盛大开幕,精彩等你来!

![]()
相关阅读:
从商用到开源:DB2迁移至MySQL的最佳实践
MySQL 传统复制中常见故障处理和结构优化案例分析
从主从复制到Group Replication
MySQL Group Replication 学习笔记
深入剖析 Group Replication内核的引擎特性
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
‘2017DTC’,2017DTC大会PPT
‘DBALIFE’,“DBA的一天”海报
‘DBA04’,DBA手记4经典篇章电子书
‘INTERNALS’,Oracle RAC PPT
‘122ARCH’,Oracle 12.2体系结构图
‘2017OOW’,Oracle OpenWorld资料
‘PRELECTION’,大讲堂讲师课程资料
