深入了解Redis

本文将主要从Redis适用范围,与Memcached, Java容器对比,核心功能(Pipelining,
Pub/Sub,LRU,Transactions, Persistence, Replication),分布式架构设计,Cluster,
内部实现及数据结构来深入了解Redis,适用于已经了解并有Redis操作经验之程序员。
1. Redis介绍
REmote DIctionary Server(Redis)是一个开源(BSD协议)的,使用ANSI C语言编写,
基于内存in-memory数据存储结构,可以当作NoSQL数据库,缓存和消息代理来使用。支持
多种数据结构,包括string, hashes, lists, set, sorted sets, bitmaps, hyperloglogs等。此外,
Redis还支持内置replication, LRU (Least Recently Used )算法管理缓存,Pub/Sub,部分
原子性操作,简单事务支持,基于磁盘的数据持久化以及3.0实现了分布式Redis支持HA,
久违的Redis Cluster。从2013年5月开始,Redis的开发由Pivotal公司主持。
2. Redis之父Antirez

饮水思源,Redis之父Salvatore Sanfilippo, 一名来自意大利西西里岛(Sicily)出生于
1977年的程序员,网名Antirez, 常居住于Catania。Antirez的IT职业生涯开始于系统管理员,
IT安全,并于Web 2.0的年代创立一家web网络公司,主要开发社交应用。之后,在一次实时
统计分析产品开发中,为了节省成本以及高性能扩展性,Antirez意识到需要一种支持多种复杂
数据结构的in-memory数据库,并且支持快速操作。Redis就此诞生并开源。之后,VM慧眼相
中了Redis, 并雇佣Antirez去全职开发,而之后又衍生出Pivotal公司,Antirez则继续主持Redis
开发。
3. Redis适用场景Redis通常被大家称为数据结构服务器,一种轻量级K/V数据存储,如我们上文介绍,支持丰富
的数据类型。Redis以其速度而闻名,这使得其称为某一特定领域适用的最优选择。
那请问大家是在什么场景下选用Redis呢?有小伙伴说大多数情况是大量数据需要缓存吧。
那又请问这种情况为什么不用Memcached呢?又或者干脆选择Java自带容器ArrayList, HashMap,
ConcurrentHashMap, HashSet呢?我们带着这两个问题往下看。
3.1 互联网/社交
Redis的用户多为互联网公司如Twitter, Weibo(微博), Uber, StackOverflow, Airbnb, Alibaba等。
对于社交网站Twitter, Weibo,这些网站主要使用Redis进行高效的社交关系管理,缓存用户好友,
粉丝,关注等,并且可以通过Redis内置数据模型快速计算共同好友等。
我们先看各大社交网站Twitter, Weibo(微博是国内最大的Redis用户)。这些网站的每个用户都有
好友,粉丝,关注等,并且可以相互查看共同好友等。Redis可以用来帮助高效管理这些社交关系,
如求共同好友:

如上,Redis很方便的使用有序集合的交集功能实现。其中user:100000:follow为用户1的粉丝列表,
user:200000:follow为用户2的粉丝列表,out:100000:200000为交集共同好友列表。
又如另一个常用场景,电商各种计数,如商品维度计数(关注度,喜欢数,评论数,浏览数等)。
可以采用Redis的Hash类型,并借助其原子性操作来维护计数。

用户维度计数(动态,关注数,粉丝数,发帖数等)

当然除了这些互联网用途,Redis最常用的功能还是被当作缓存。提到缓存,大家当然会想到memcached。
Redis v.s. Memcached
-
数据类型与操作:Redis拥有更多丰富的数据结构支持与操作,而Memcached则需客户端自己处理并进行网络交互
-
内存使用率:简单K/V存储,Memcached内存利用率更高(使用了slab与大小不同的chunk来管理内存),而如果采用Redis Hash来存储则其组合压缩,内存利用率高于Memcached
-
性能:总体来说,二者性能接近;Redis使用了单核(单线程IO复用,封装了AeEvent事件处理框架,实现了epoll,kqueue,select),Memcached采用了多核,各有利弊;当数据大于100K的时候,Memcached性能高于Redis
-
数据持久化:Redis支持数据文件持久化,RDB与AOF两种策略;Memcached则不支持
-
分布式:Memcached本身并不支持服务器端分布式,客户端只能借助一致性哈希分布式算法来实现Memcached分布式存储;当然Redis也是从3.0版本开始才支持服务器端cluster的,重要的是现在支持了。
-
其他方面:Redis提供其他一些功能,如Pub/Sub, Queue, 简单Transacation, Replication等。
好了,千言不抵一图:

Redis v.s. HashMap
作为单机数据缓存,Java自带容器也是备选方案之一。我们进行压力测试,采用ConcurrentHashMap, Memcached(假设近似于Redis), MySQL进行Benchmark。

具体数据如下:
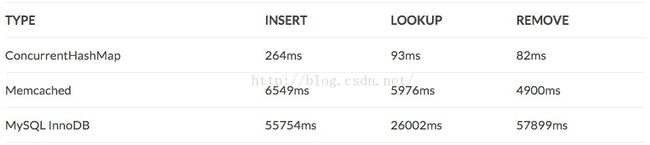
可以看出,HashMap(上图显示为一根线)整体操作插入/查询/移除都 25 - 90倍快于Memcached/Redis; 而Memcached/Redis又 5 -12 倍快于MySQL InnoDB,符合预期。究其原因,Java容器单机内存直接读取,无网络开销,无须序列化等。
而反之之所以要用Redis的原因与好处则包括:
HashMap单机受限于内存容量,而正是Redis分布式之优势
-
HashMap当数据量超过一定限制后,需要妥善管理堆内存,不然会造成内存溢出或者Memory Leak;Redis则具备了文件持久性,以及Failover达到HA.
-
HashMap只能受限于本机,而Redis天生分布式,可以让多个App Server访问,负载均衡。
所以Redis适合全部数据都在内存的场景包括需要临时持久化,尤其作为缓存来使用,并支持对缓存数据进行简单处理计算;如涉及Redis与RDBMS双向同步的话,则需要引入一些复杂度。
4. Redis核心功能
4.1 Pipelining
Reids是一个TCP客户端-服务器模式,使用了应请求/响应协议,客户端与服务器的交互是阻塞的方式。
如下一个请求/响应事例,客户端发起4个INCR命令,服务端依次响应:
-
Client:INCR X
-
Server:1
-
Client:INCR X
-
Server:2
-
Client:INCR X
-
Server:3
-
Client:INCR X
-
Server:4
客户端与服务器通过网络连接,影响性能的关键因素往返时间(RTT Round Trip Time)则受限于网络
速度,如在网速较慢情况下RTT需要250毫秒,哪怕服务器性能卓越可以每秒处理1万个请求,然而整体
则客户端受网络制约只能每秒处理4个请求。即便使用了loopback接口节省RTT时间,但如果需要大量的
写操作,整体性能仍不可观。
Redis引入了批处理,管道(Pipelining),即客户端可以一次发送多个命令给服务器,无须等待服务器的
返回,而服务器端则回将请求放入一个有序的管道中,在执行完成后,一次性将返回值发送回客户端。
上述事例在使用Pipelining时如下,客户端通过缓冲区,一次性批量发送请求INCR,服务端则处理后统一
返回结果:
-
Client:INCR X
-
Client:INCR X
-
Client:INCR X
-
Client:INCR X
-
Server:1
-
Server:2
-
Server:3
-
Server:4
4.2 Pub/Sub
Reids提供了解耦消息的发布/订阅(Pub/Sub)通信模式,Pub/Sub采用事件作为基本通信机制,支持时间
(非同时),空间(无须知道具体位置)与同步(可异步模式)等解耦合,而发布与订阅则通过通道
(channel)来通信。
Antirez称,最初引入Pub/Sub是应用户需求,并且Redis本身的架构已经支持Pub/Sub, 所以只用了150行
代码就把Pub/Sub已实现的内部功能暴露称Pub/Sub API。
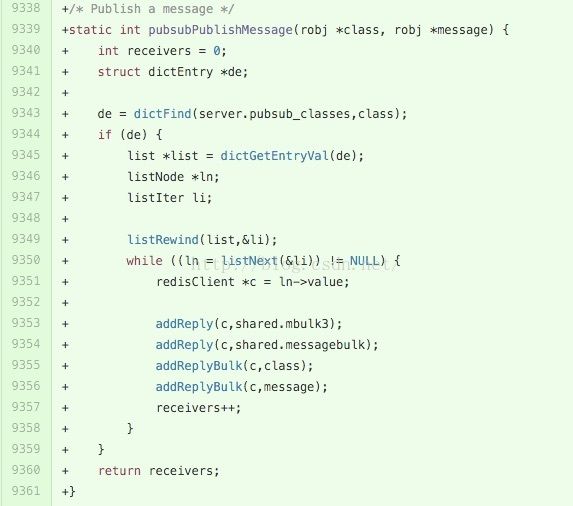
上图为较早版本中发布消息的一段代码片段,可以看出消息保存在一个List链表数据结构中,消息的类型为
messagebulk。另外,Redis也支持通配符模式匹配的订阅方式。
Pub/Sub v.s. 消息中间件
Reids的Pub/Sub与消息中间件相比,并不支持持久化,如系统宕机,网络问题等都会造成消息丢失;
Redis的消息多用于实时性较高的消息推送,并不保证可靠性。Redis的消息也无法支持水平扩展,
如通过增加consumer或者订阅者分组之类进行负载均衡。
性能方面,Redis的Pub/Sub与常用消息中间件如著名的RabbitMQ比较,则伯仲之间。

上图以处理10万个消息为例,在发布消息方面,RabbitMQ的耗时为Redis的75%;订阅消费消息
RabbitMQ耗时为Redis的86%,可见整体性能Redis已与消息中间件相近。
4.3 LRU
LRU(Least Recently Used) 最近最久未使用算法,是多数缓存系统当内存受限时自动清理旧数据的
常用常用算法之一。当Redis使用内存达到配置maxmemory时,Redis会根据配置的policy进行数据置
换处理,其中策略包括如下:
-
noenviction(不清除)
-
allkeys-lru(从所有数据集选择最近最少用)
-
volatile-lru(从设置过期时间的数据集选择最近最少用)
-
allkeys-random(所有数据集随机选取淘汰),
-
volatile-random(以设置过期时间数据集中随机),
-
volatile-ttl(从已设置过期过期时间的数据集中选择,非LRU)
Redis出于性能及节约内存考量,采用的并非严格意义LRU算法算法,而是近似的LRU算法,即Redis通过采样
一小部分键,然后在样本池中进行LRU。当然在Redis 3.0中,算法进一步改进为维护回收候选键池,改善了性
能同时更接近于LRU算法行为。
下图为官网提供Reids LRU性能测试,分别为理论LRU算法,10个样本的Redis 3.0 LRU算法,以及5个样本的
Redis 2.8与3.0算法的表现,其中浅灰色表示被置换出去的key,灰色为没有被置换的key,绿色为新增的key。

测试算法较简单,首先默认导入一定数目key,之后从第一个key遍历至最后一个key(相当于按时间顺序使用过了
当前遍历的key),之后再增加50%的数目触发清理策略。
可以看出,理论算法为最旧的50%被替换;同样样本为5情况下,3.0表现要优于2.8,3.0则更接近于理论值,
2.8算法则略为逊色。
4.4 Transactions
绝大多数NoSQL选择不支持事务,而Reids以命令方式(MULTI, EXEC, DISCARD, WA WATCH)提供了简单的
类/伪事务支持,之所以称之为类/伪事务,是因为Redis的只保证了事务必须ACID的C(一致性),I(隔离性),
并不保证A(原子性)与持久性(D),Redis事务甚至不支持回滚操作。
实际上,Redis的事务提供了一种将多个命令打包并置入事务队列,之后批量一次性,有序的按照先进先出
(FIFO)的顺序执行机制。事务在执行过程中不会被中断,所有命令命令执行之后,事务才结束。
Transaction v.s. Pipelining
Redis的Transaction与Pipelining都是批量执行命令,其主要差别为:
-
Pipelining主要是提供了网络层面的优化,客户端通过缓存多个命令并按批次发送给服务端处理以节省网络RTT(Round Trip TIme)时间开销,但这些命令并不保证事务性(Redis的单线程保证了单个命令本身是原子的,但多个client可以发起多个命令串行执行)。
-
Transaction则保证了一个client发起的事务中的命令可以连续的执行,中间不会插入其它client的命令,而此则受益于Redis的单线程模式,很容易实现。
所以,Transaction与Pipelining不但不冲突,对于批量命令甚至可以结合起来使用以达到网络优化及事务性
保证双重收效。
4.5 Persistence
Redis提供了两种常用的不同级别的磁盘持久化方式,RDB与AOF(Append-Only-File)。RDB持久化在指定
的时间间隔生成数据集的时间点快照(Snapshot), AOF则类似RDMS的binlog日志。
由于单线程运行,Redis的RDB在备份时为不影响系统正常使用,借助Linux的fork命令及copy on write机制,
在fork出的子进程中进行备份写RDB文件。RDB的备份相对简单并且文件小,但无法保证数据的完整性,
如Redis在RDB的间隔时间内宕机,则面临丢失期间的数据。RDB较适合定期的归档备份及方便灾难恢复。
而AOF则提供了更好的持久性,Redis会将每个命令都追加到AOF文件中,并提供了三种持久化策略:
-
no fsync at all:Redis不调用fsync持久化, 操作系统决定同步时机(多数30秒)
-
fsync everysecond:每秒(延迟会两秒)进行一次fsync将缓冲区数据写入磁盘
-
fsync always:每个命令都进行同步,持久化写入磁盘,安全但较慢
AOF后台执行的方式与RDB类似,也是借助fork开启子进程进行写入AOF文件。为了减少AOF文件的大小,
Redis提了了文件压缩命令,另外支持日志重写,后台重构AOF文件以减少所需命令。
4.6 Replication
Redis支持Master/Slave主从配置,实现弱一致性,支持负载均衡,提高HA。Redis的Master可以对应
多个Slave, Slave也可以级联多个Slave。通常Master负责读写服务,Slave负责读服务,Master与Slave
间靠Replication定期来进行同步。
Redis的主从结构如下图所示DAG(有向无环图)

Slave会定期给Master发送SYNC命令进行同步,如果第一次连接则进行全量同步否则增量同步。
Master则启动后台快找进程saving来收集最近修改数据集所有命令并将其用db file传输给Slave。
5. Redis系统架构
Sentinel架构
Reids Sentinel诞生于2012年(Redis 2.4版本),建议在单机Redis或者客户端模式Cluster的时候
(非 3.0版本Redis Cluster)采用,作为HA, Failover来使用。

Sentinel主要提供了集群管理,包括监控,通知,自动故障恢复。如上图,当其中一个master无法
正常工作时,Sentinel将把一个Slave提升为Master, 从而自动恢复故障。而Sentinel本身也做到了
分布式,可以部署多个Sentinel实例来监控Redis实例(建议基数,至少3个Sentinel实例来监控一
组Redis Master/Slaves),多个Sentinel进程间通过Gossip协议来确定Master是否宕机,通过
Agreement协议来决定是否执行故障自动迁移以及重新选主,整体设计类似ZooKeeper
(应该是作者参考了当年的ZK吧?)。
Cluster架构
Redis Cluster开始设计于2011年(早于Sentinel),正式诞生于2015年愚人节,Redis 3.0,其中之
苦辣酸甜只有Antirez自己知道。

如上图,从3.0开始, Redis从一个单纯的NoSQL内存数据库变成了一个真正分布式NoSQL数据库。
概括来说,所谓分布式即支持数据分片,并且自动管理故障恢复(failover)与备份(replication)。

如上图Redis Cluster采用了无中心结构,每个节点都保存,共享数据和集群状态,每个节点与
其它所有节点通信,使用Gossip协议来传播及发现新节点,通过分区来提供一定程度可用性,
当某个node的Master宕机时,Cluste会自动选举一个Slave形成一个新的Master,这里应该是
借鉴,重用了Sentinel的功能。
另外,Redis Cluster并没有使用通常的一致性哈希, 而引入哈希槽的概念,Cluster中固定有
16384个slot, 每个key通过CRC16校验后对16384取模来决定其对应slot的位置,而每个node
负责一部分的slot管理,当node变化时,动态调整slot的分布,而数据则无须挪动。对于客户端
来说,client可以向任意一个实例请求,Cluster会自动定位需要访问的slot。
上图查询路由过程中,我们随机发送到任意一个Redis实例,这个实例会按照上文提到的CRC16
校验后取模定位,并转发至正确的Redis实例中。

然而,完全去中心化的架构同时也失去了一些灵活与总控能力,如可通过引入中央控制的自动发
现节点的变化及时Rebalance,分区粒度的备份,故障时分区自动调整,Gossip消息的通信开销,
路由表维护等。
值得一提的是,Redis的企业版/商业版Redis Labs Enterprise Cluster(RLEC)则似乎解决了我们
上述问题,如引入了中央控制Cluster Manager来管理,监控,分片迁移等工作, 引入高性能Proxy
隐藏幕后的路由实现等。

当然,前提是商业化付费版本了,我们也期待未来的开源Redis逐步可以引入这些概念。
Redis支持丰富的数据类型,并提供了大量简单高效的功能。为了高效使用Redis,开发设计人员需要对Redis的数据结构进行选型,如选择链表还是集合等。 下面我们快速了解一下Redis内部数据结构及其代码实现。Redis的底层数据结构总览图:

上图列出了Redis内部底层的一些重要数据结构,包括List, Set, Hash, String等。
来看几个比较核心的的数据结构。
Redis 3.x后的redisObject如下图所示:

redisObject定义中使用了位字段(bit filed)。简单来说,redisObject定义了类型,编码方式,
LRU时间,引用计数,*ptr指向实际保存值指针。
-
type: redisObject的类型,字符串,列表,集合,有序集,哈希表等
-
encoding: 底层实现结构,字符串,整数,跳跃表,压缩列表等
-
ptr:实际指向保存值的数据结构
举个具体例子,redisObject{type: REDIS_LIST, encoding:REDIS_ENCODING_LINKEDLIST},
这个对象是Redis列表,其值保存在一个链表中,ptr指针指向这个列表。
用惯了JVM的虚拟机,我们也来回顾一下C或者Redis是如何管理对象的。总体而言,Redis自己实现对象管理机制,并基于引用计数的垃圾回收。

毫无疑问的直接malloc开辟内存空间,设置type,encoding,引用计数默认1,设置默认LRU。可以看出refcount,猜测其内部是基于引用计数来管理释放内存空间的。事实要以代码为准。
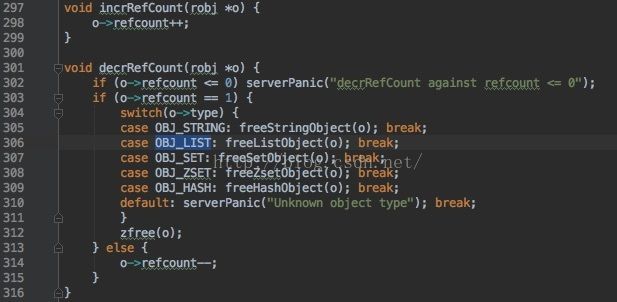
果不其然,Redis提供了incrRefCount与decrRefCount来管理对象跟踪对象的引用, 当减少引用时检测计数器为是否需要释放内存对象。
RedisDB
RedisDB内部数据结构,封装了数据库层面的信息:
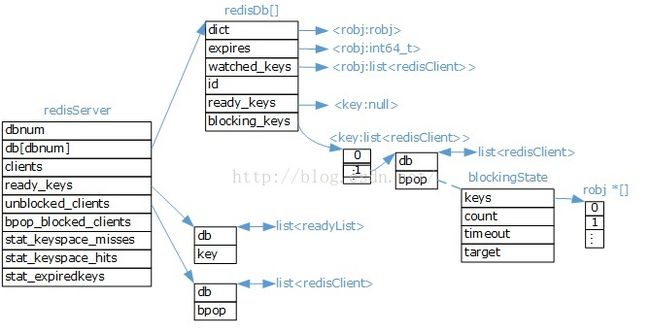
从redisDB来看,几个重要属性:
-
id:数据库内部编号,仅供内部操作使用,如AOF等
-
dict:存放整个数据库的键值对,键为字符串,值为Redis的数据结构,如List, Set, Hash等。
-
expires:键的过期时间
具体代码如下:

代码注释较为清晰,其中long long是C99标准新加的,64位长整型。
RedisServer代码在Redis 3.0支持Cluster后变得较复杂,我们只列出部分代码。
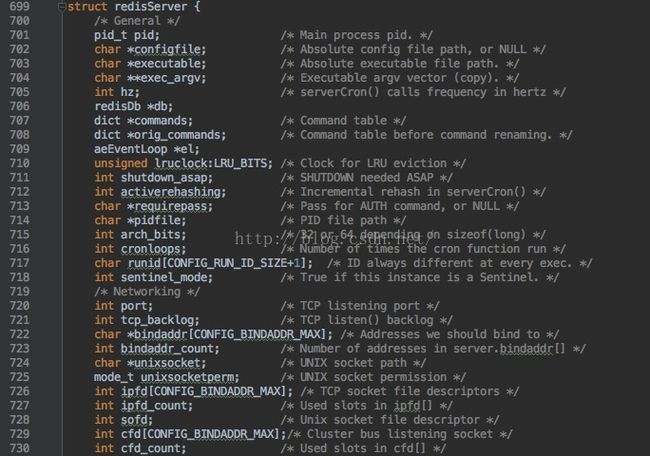
总体来说包含如下几个大部分:
-
通用部分:如pid进程id,数据库指针,命令字典表,Sentinel模式标志位等
-
网络信息:如port TCP监听端口,Cluster Bus监听socket, 已使用slot数量,Active的客户端列表, 当前客户端,Slaves列表等。
-
其它信息:如AOF信息,统计信息, 配置信息(如已经配置总db数量dbnum等),日志信息,Replication配置,Pub/Sub, Cluster信息,Lua脚本信息配置等等。
Redis Hash
Redis的哈希表/字典是其核心数据结构之一,值得深入研究。Redis Hash数据结构, Hash新创建时,
在不影响效率情况下,Redis默认使用zipmap作为底层实现以节省空间,只有当size超出一定限制后
(hash-max-zipmap-entries ),Redis才会自动把zipmap转换为下图Hash Table。
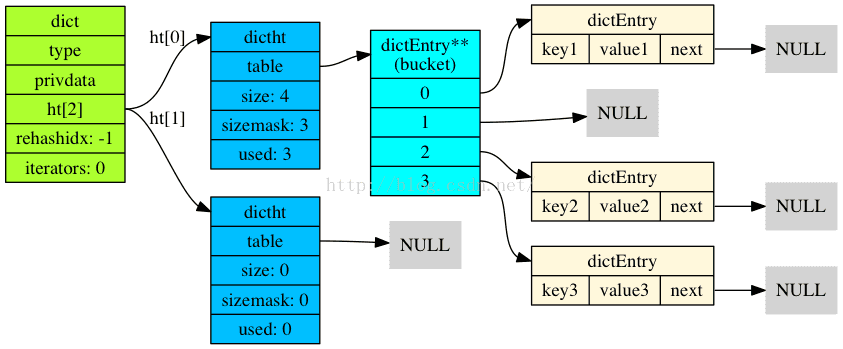
上图字典的底层实现为哈希表,每个字典包含2个哈希表,ht[0], ht[1], 1号哈希表是在rehash过程中才
使用的。而哈希表则由dictEntry构成。
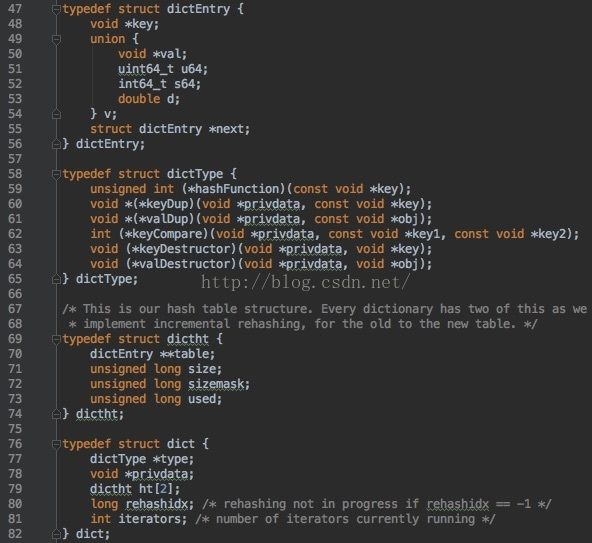
代码层面,每个字典包含了3个内部数据结构:
-
Dict:字典的根结构,包含了2个dictht,其中2作为rehashing之用
-
Dictht:包含了linkedlist dictEntry
-
DictEntry:包含了3个数据结构(double/uint64_6/int64t)的链表,类似Java HashMap中的Entry结构
Hash算法
目前Redis中引入了一些经典哈希算法,而HashTable则主要为以下两种:
-
MurmurHash2 32bit算法:著名的非加密型哈希函数,能产生32位或64位哈希值,最新版本为
-
MurmurHash3。该算法针对一个字符串进行哈希,可表现较强离散性。
-
基于djb算法实现散列算法:该算法较为简单,同样是将字符串转换为哈希值。主要利用字符串中
-
的ASCII码与一个随机seed,进行变换得到哈希值。
评估一个哈希算法的优劣,主要看其哈希值的离散均匀效果以及消除冲突程度。Redis在HashTable中
引入的上述两种算法不失简单高效,离散均匀。
Rehash
类似Java中的HashMap, 当有新键值对添加到Redis字典时,有可能会触发rehash。Redis中处理哈希
碰撞的方法与Java一样,都是采用链表法,整个哈希表的性能则依赖于它的大小size和它已经保存节点
数量used的比率。
比率在1:1时,哈希表的性能最好,如果节点数量比哈希表大小大很多的话,则整个哈希表就退化成多个
链表,其性能优势全无。
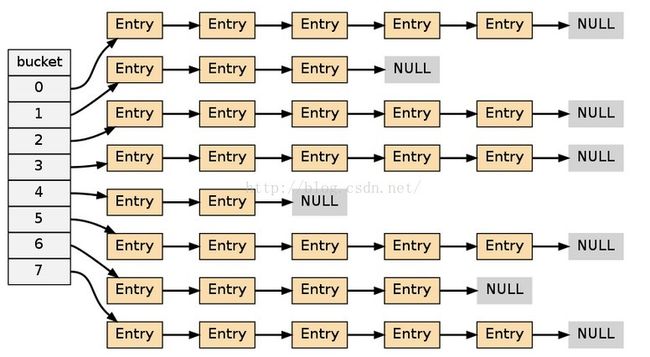
上图的哈希表,平均每次失败查找需要访问5个节点。为了保持高效性能,在不修改键值对情况下,
需要进行rehash,目标是将ratio比率维持在1:1左右。
Ratio = Used / Size
rehash触发条件:
-
自然rehash:ratio >= 1, 且变量dict_can_resize为真
-
强制rehash:ratio大于dict_force_resize_ratio(v 3.2.1版本为5)
rehash执行过程:
-
创建ht[1]并分配至少2倍于ht[0] table的空间
-
将ht[0] table中的所有键值对迁移到ht[1] table
-
将ht[0]数据清空,并将ht[1]替换为新的ht[0]
Redis哈希为了避免整个rehash过程中服务被阻塞,采用了渐进式的rehash,即rehash程序激活后,并不是
马上执行直到完成,而是分多次,渐进式(incremental)的完成。同时,为了保证并发安全,在执行rehash
中间执行添加时,新的节点会直接添加到ht[1]而不是ht[0], 这样保证了数据的完整性与安全性。
另一方面,哈希的Rehash在还提供了创新的(相对于Java HashMap)收缩(shrink)字典,当可用节点远远
大于已用节点的时候,rehash会自动进行收缩,具体过程与上面类似以保证比率始终高效使用。
7. 总结
本文从Redis的一些核心功能,适用范围与本质原因,分布式架构设计,Cluster,重要内部数据结构及代码片段等层面深入了解,在Redis使用方面,开发及设计人员通常需要对Redis有一定深度理解,对业务模型进行相应的数据结构选型,还需提前预估内存使用,是否需要持久化,分布式等。总体来说,Redis非常适合与传统关系型数据库结合使用,做高性能数据缓存,轻量级消息队列及跨机器共享内存。希望本文对Redis开发人员有所帮助,碰到一些实现细节,建议还是要深入其源代码一探究竟。有关其它Redis的命令操作及其它高级功能则可参考Redis官网。
公众号:技术极客TechBooster
