CDN Glossary
What is caching?
Caching is the process of storing copies of files in a cache, or temporary storage location, so that they can be accessed more quickly. Technically, a cache is any temporary storage location for copies of files or data, but usually the term is used in reference to Internet technologies. DNS servers cache DNS records for faster lookups, CDN servers cache content to reduce latency, and web browsers cache HTML files, JavaScript, and images in order to load websites more quickly.
To understand how caches work, consider real-world caches of food and other supplies. When explorer Roald Amundsen made his return journey from his trip to the South Pole in 1912, he and his men subsisted on the caches of food they had stored along the way. This was much more efficient than waiting for supplies to be delivered from their base camp as they traveled. Caches on the Internet serve a similar purpose; they temporarily store the 'supplies', or content, needed for users to make their journey across the web.
What is CDN caching?
A CDN, or content delivery network, caches content (such as images, videos, or webpages) in proxy servers that are located closer to end users than origin servers. (A proxy server is a server that receives requests from clients and passes them along to other servers.) Because the servers are closer to the user making the request, a CDN is able to deliver content more quickly.
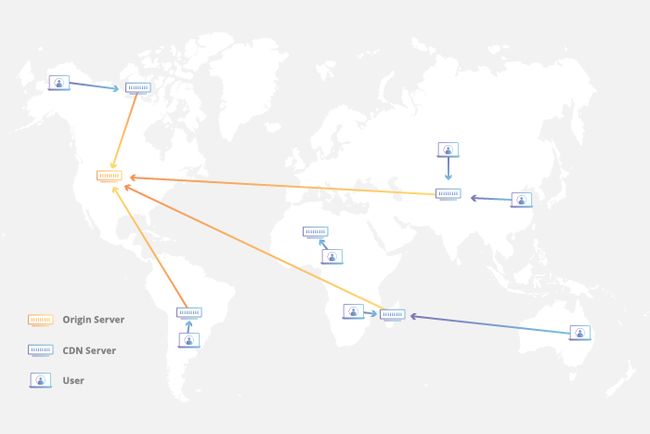
Think of a CDN as being like a chain of grocery stores: Instead of going all the way to the farms where food is grown, which could be hundreds of miles away, shoppers go to their local grocery store, which still requires some travel but is much closer. Because grocery stores stock food from faraway farms, grocery shopping takes minutes instead of days. Similarly, CDN caches 'stock' the content that appears on the Internet so that webpages load much more quickly.
How does content become cached?
When a user requests content from a website using a CDN, the CDN fetches that content from an origin server, and then saves a copy of the content for future requests. Cached content remains in the CDN cache as long as users continue to request it.
What is a cache hit? What is a cache miss?
A cache hit is when a client device makes a request to the cache for content, and the cache has that content saved. A cache miss occurs when the cache doesn't have the requested content. In the case of a cache miss, a CDN server will pass the request along to the origin server, then cache the content once the origin server responds, so that subsequent requests will result in a cache hit.
Where are CDN caching servers located?
CDN caching servers are located in data centers all over the globe. Cloudflare has CDN servers in 194 data centers spread out throughout the world in order to be as close to end users accessing the content as possible. A location where CDN servers are present is also called a point of presence (PoP).
How long does cached data remain in a CDN server?
When websites respond to CDN servers with the requested content, they attach information to the content that will let the servers know how long to store it. This information is stored in a part of the response called the HTTP header, and it specifies for how many seconds, minutes, or hours content will be cached. This is known as the Time-To-Live (TTL). When the TTL expires, the cache removes the content. Some CDNs will also purge files from the cache early if the content is not requested for a while, or if a CDN customer manually purges certain content.
How do other kinds of caching work?
Web browser caching takes place when a browser saves a copy of files from a website on the user device's hard drive. When a webpage is cached, the browser only needs to load new or updated pieces of a page, which enables browsers to deliver pages quickly even if an Internet connection is slow. Browsers store these files until their TTL expires or until the hard drive cache is full. Users can also clear their browser cache if desired.
DNS caching takes place on DNS servers. The servers store recent DNS lookups in their cache so that they don't have to query nameservers and can instantly reply with the IP address of a domain.
Search engines may cache webpages that frequently appear in search results in order to answer user queries even if the website they are attempting to access is temporarily down or unable to respond.
What is Anycast?
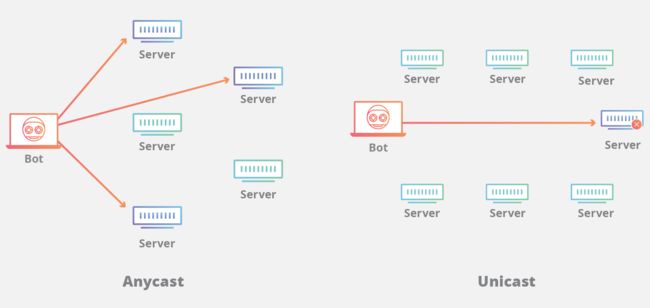
Anycast is a network addressing and routing method in which incoming requests can be routed to a variety of different locations or “nodes.” In the context of a CDN, Anycast typically routes incoming traffic to the nearest data center with the capacity to process the request efficiently. Selective routing allows an Anycast network to be resilient in the face of high traffic volume, network congestion, and DDoS attacks.
How does Anycast Work?
Anycast network routing is able to route incoming connection requests across multiple data centers. When requests come into a single IP address associated with the Anycast network, the network distributes the data based on some prioritization methodology. The selection process behind choosing a particular data center will typically be optimized to reduce latency by selecting the data center with the shortest distance from the requester. Anycast is characterized by a 1-to-1 of many association, and is one of the 5 main network protocol methods used in the Internet protocol.
Why Use an Anycast Network?
If many requests are made simultaneously to the same origin server, the server may become overwhelmed with traffic and be unable to respond efficiently to additional incoming requests. With an Anycast network, instead of one origin server taking the brunt of the traffic, the load can also be spread across other available data centers, each of which will have servers capable of processing and responding to the incoming request. This routing method can prevent an origin server from extending capacity and avoids service interruptions to clients requesting content from the origin server.
What is the Difference between Anycast and Unicast?
Most of the Internet works via a routing scheme called Unicast. Under Unicast, every node on the network gets a unique IP address. Home and office networks use Unicast; when a computer is connected to a wireless network and gets a message saying the IP address is already in use, an IP address conflict has occurred because another computer on the same Unicast network is already using the same IP. In most cases, that isn't allowed.

When a CDN is using a unicast address, traffic is routed directly to the specific node. This creates a vulnerability when the network experiences extraordinary traffic such as during a DDoS attack. Because the traffic is routed directly to a particular data center, the location or its surrounding infrastructure may become overwhelmed with traffic, potentially resulting in denial-of-service to legitimate requests.
Using Anycast means the network can be extremely resilient. Because traffic will find the best path, an entire data center can be taken offline and traffic will automatically flow to a proximal data center.
How does an Anycast network mitigate a DDoS attack?
After other DDoS mitigation tools filter out some of the attack traffic, Anycast distributes the remaining attack traffic across multiple data centers, preventing any one location from becoming overwhelmed with requests. If the capacity of the Anycast network is greater than the attack traffic, the attack is effectively mitigated. In most DDoS attacks, many compromised "zombie" or “bot” computers are used to form what is known as a botnet. These machines can be scattered around the web and generate so much traffic that they can overwhelm a typical Unicast-connected machine.
A properly Anycasted CDN increases the surface area of the receiving network so that the unfiltered denial-of-service traffic from a distributed botnet will be absorbed by each of the CDN’s data centers. As a result, as a network continues to grow in size and capacity it becomes harder and harder to launch an effective DDoS against anyone using the CDN.
It is not easy to setup a true Anycasted network. Proper implementation requires that a CDN provider maintains their own network hardware, builds direct relationships with their upstream carriers, and tunes their networking routes to ensure traffic doesn't "flap" between multiple locations. This Cloudflare blog post explains how Cloudflare uses Anycast to load balance without load balancers.
What is a data center?
A data center is a facility housing many networked computers that work together to process, store, and share data. Most major tech companies rely heavily upon data centers as a central component in delivering online services.
What is the difference between a data center and a point-of-presence (PoP)?
The terms data center and point-of-presence are sometimes used interchangeably, though distinctions can be made between them. Speaking generally, a PoP may refer to a company having a single server presence in a location while a data center may refer to a location that houses multiple servers. Instead of referring to multiple PoPs in one location, Cloudflare uses the term data center to indicate a location in which many of our servers are maintained.
The concept of a point-of-presence rose to prominence during the court ordered breakup of the Bell telephone system. In the court decision, a point-of-presence referred to a location where long-distance carriers terminate services and shift connections onto a local network. Similarly, on the modern Internet a PoP typically refers to where CDNs have a physical presence in a location, often in the junctures between networks known as Internet exchange points (IxP).
A data center refers to a physical location in which computers are networked together in order to improve usability and reduce costs related to storage, bandwidth, and other networking components. Data centers such as IxP co-location facilities allow different Internet service providers, CDN’s, and other infrastructure companies to connect with each other to share transit.
What are the common concerns in the design of a data center?
Many components and factors are taken into consideration when creating a modern data center. With proper planning, maintenance, and security, a data center is at lower risk of both downtime and data breaches.
Data center considerations include:
- Redundancy/backup - the level of redundancy varies widely based on the quality of a data center; in high tier data centers, multiple redundancies in power and backup servers are built into the infrastructure.
- Efficiency - the amount of electricity used at a large data center rivals that of a small town. Whenever possible, data centers attempt to cut down on costs by optimizing cooling processes and using energy-efficient hardware.
- Security - proper physical security, both in terms of electronic surveillance, access controls, and on-site security guards reduce the risk associated with bad actors attempting to gain site access.
- Environmental controls/factors - maintaining the right environmental conditions is necessary for the proper functioning of electronic hardware. Keeping both temperature and humidity within acceptable parameters requires the proper balance of air conditioning, humidity control, and airflow regulation. In areas that are vulnerable to earthquakes, properly secured servers are also a necessary concern.
- Maintenance and monitoring - on-site or on-call network engineers are needed in order stay on top of server crashes and other hardware failures. Proper response helps to ensure server uptime and eliminate reductions in quality of service.
- Bandwidth - a data center is incomplete without the bandwidth necessary to handle all the requisite network traffic. Bandwidth considerations are a central component in data center infrastructure, with external network connections and internal data center topology both designed around sufficient network capacity.
What is an Origin Server?
The purpose of an origin server is to process and respond to incoming internet requests from internet clients. The concept of an origin server is typically used in conjunction with the concept of an edge server or caching server. At its core, an origin server is a computer running one or more programs that are designed to listen for and process incoming internet requests. An origin server can take on all the responsibility of serving up the content for an internet property such as a website, provided that the traffic does not extend beyond what the server is capable of processing and latency is not a primary concern.
The physical distance between an origin server and a client making a request adds latency to the connection, increasing the time it takes for an internet resource such as a webpage to be loaded. The additional round-trip time (RTT) between client and origin server required for a secure internet connection using SSL/TLS also add additional latency to the request, directly impacting the experience of the client requesting data from the origin. By using a Content Distribution Network (CDN) round-trip time is able to be reduced, and the amount of requests to an origin server are also able to be reduced.
What is the difference between an Origin Server and a CDN Edge server?
Put simply, CDN edge servers are computers placed in important junctures between major internet providers in locations across the globe in order to deliver content as quickly as possible. An edge server lives inside a CDN on the “edge” of a network and is specifically designed to quickly process requests. By placing edge servers strategically inside of the Internet Exchange Points (IxPs) that exist between networks, a CDN is able to reduce the amount of time it takes to get to a particular location on the Internet.
These edge servers cache content in order to take the load off of one or more origin servers. By moving static assets like images, HTML and JavaScript files (and potentially other content) as close as possible to the requesting client machine, an edge server cache is able to reduce the amount of time it takes for a web resource to load. Origin servers still have an important function to play when using a CDN, as important server-side code such as the database of hashed client credentials used for authentication is typically maintained inside an origin server.
Here's a simple example of how an edge server and an origin server work together to serve up a login page and allow a user to login to a service. A very simple login page requires the following static assets to be downloaded for the webpage to render properly:
- A HTML file for the webpage
- A CSS file for the webpage styling
- Several image files
- Several JavaScript libraries
These files are all static files; they are not dynamically generated and are the same for all visitors to the website. As a result, these files can be both cached and served to the client from the edge server. All of these files can be loaded closer to the client machine and without any bandwidth consumption by the origin.

Next, when the user enters their login and password and presses “login,” the request for dynamic content travels back to the edge server who then proxies the request back to the origin server. The origin then verifies the user's identity in the associated database table before sending back the specific account information.

This interplay between edge servers handling static content and origin servers serving up dynamic content is a typical separation of concerns when using a CDN. The capability of some CDNs can also extend beyond this simplistic model.
Can an origin server still be attacked while using a CDN?
The short answer is yes. A CDN does not render an origin server invincible, but when used properly it can render an origin server invisible, acting as a shield for incoming requests. Hiding the real IP address of an origin server is an important part of setting up a CDN. As such, a CDN provider should recommend that the IP address of the origin server be changed when implementing a CDN strategy in order to prevent DDoS attacks from going around the shield and hitting the origin directly.
What is a CDN edge server?
A CDN edge server is a computer that exists at the logical extreme or “edge” of a network. An edge server often serves as the connection between separate networks. A primary purpose of a CDN edge server is to store content as close as possible to a requesting client machine, thereby reducing latency and improving page load times.
An edge server is a type of edge device that provides an entry point into a network. Other edges devices include routers and routing switches. Edge devices are often placed inside Internet exchange points (IxPs) to allow different networks to connect and share transit.
How does an edge server work?
In any particular network layout, a number of different devices will connect to each other using one or more predefined network pattern. If a network wants to connect to another network or the larger Internet, it must have some form of bridge in order for traffic to flow from one location to another. Hardware devices that creates this bridge on the edge of a network are called edge devices.
Networks connect across the edge
In a typical home or office network with many devices connected, devices such as mobile phones or computers connect and disconnect to the network through a hub-and-spoke network model. All of the devices exist within the same local area network (LAN), and each device connects to a central router, through which they are able to connect with each other.
In order to connect a second network to the first network, at some point the connection must be made between the networks. The device through which the networks are able to connect with each other is, by definition, an edge device.
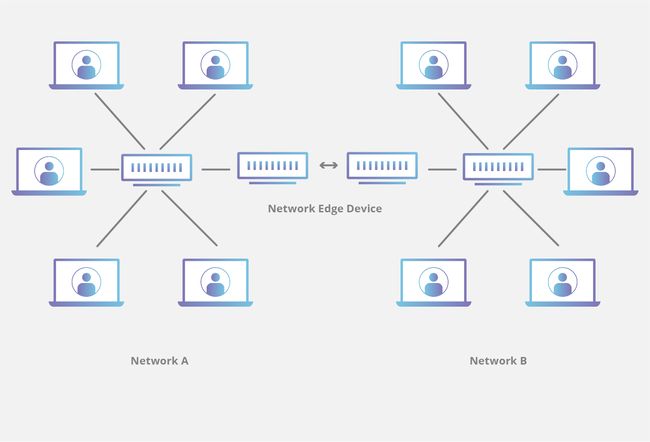
Now, if a computer inside Network A needs to connect to a computer inside Network B, the connection must pass from network A, across the network edge, and into the second network. This same paradigm also works in more complex contexts, such when a connection is made across the Internet. The ability for networks to share transit is bottlenecked by the availability of edge devices between them.
When a connection must traverse the Internet, even more intermediary steps must be taken between network A and network B. For the sake of simplicity, let's imagine that each network is a circle, and the place in which the circles touch is the edge of the network. In order for connection to move across the Internet, it will typically touch many networks and move across many network edge nodes.Generally speaking, the farther the connection must travel, the greater the number of networks that must be traversed. A connection may traverse different Internet service providers and Internet backbone infrastructure hardware before reaching its target.
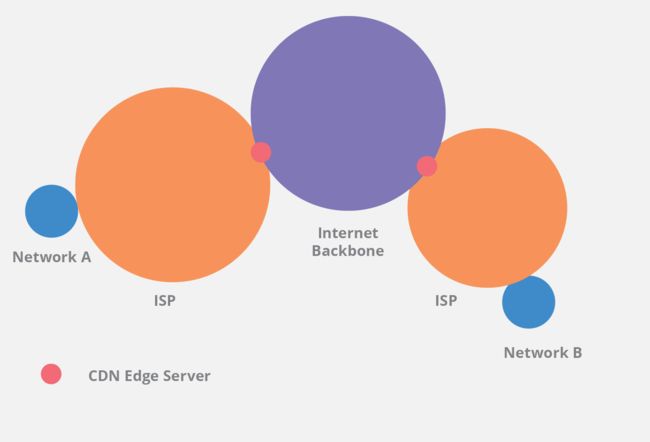
A CDN provider will place servers in many locations, but some of the most important are the connection points at the edge between different networks. These edge servers will connect with multiple different networks and allow for traffic to pass quickly and efficiently between networks. Without a CDN, transit may take a slower and/or more convoluted route between source and destination. In worst case scenarios, traffic will “trombone” large distances; when connecting to another device across the street, a connection may move across the country and back again. By placing edge servers in key locations, a CDN is able to quickly deliver content to users inside different networks. To learn more about the improvements of using CDN, explore how CDN performance works.
What is the difference between an edge server and an origin server?
An origin server is the web server that receives all Internet traffic when a web property is not using a CDN. Using an origin server without a CDN means that each Internet request must return to the physical location of that origin server, regardless of where in the world it resides. This creates an increase in load times which increases the further the server is from the requesting client machine.
CDN edge servers store (cache) content in strategic locations in order to take the load off of one or more origin servers. By moving static assets like images, HTML and JavaScript files (and potentially other content) as close as possible to the requesting client machine, an edge server cache is able to reduce the amount of time it takes for a web resource to load. Origin servers still have an important function to play when using a CDN, as important server-side code such as a database of hashed client credentials used for authentication, typically is maintained at the origin.
What is an Internet exchange point?
An Internet exchange point (IXP) is a physical location through which Internet infrastructure companies such as Internet Service Providers (ISPs) and CDNs connect with each other. These locations exist on the “edge” of different networks, and allow network providers to share transit outside their own network. By having a presence inside of an IXP location, companies are able to shorten their path to the transit coming from other participating networks, thereby reducing latency, improving round-trip time, and potentially reducing costs.
How does an Internet exchange point work?
At its core, an IXP is essentially one or more physical locations containing network switches that route traffic between the different members networks. Via various methods, these networks share the costs of maintaining the physical infrastructure and associated services. Similar to how costs are accrued when shipping cargo through third-party locations such as via the Panama Canal, when traffic is transferred across different networks, sometimes those networks charge money for the delivery. To avoid these costs and other drawbacks associated with sending their traffic across a third-party network, member companies connect with each other via IXP to cut down on costs and reduce latency.
IXPs are large Layer 2 LANs (of the OSI network model) that are built with one or many Ethernet switches interconnected together across one or more physical buildings. An IXP is no different in basic concept to a home network, with the only real difference being scale. IXPs can range from 100s of Megabits/second to many Terabits/second of exchanged traffic. Independent of size, their primary goal is to make sure that many networks’ routers are connected together cleanly and efficiently. In comparison, at home someone would normally only have one router and many computers or mobile devices.
Over the last twenty years, there has been a major expansion in network interconnections, running parallel to the enormous expansion of the global Internet. This expansion includes new data center facilities being developed to house network equipment. Some of those data centers have attracted massive numbers of networks, in no small part due to the thriving Internet exchange points that operate within them.
Why are Internet exchange points important?
Without IXPs, traffic going from one network to another would potentially rely on an intermediary network to carry the traffic from source to destination. These are called transit providers. In some situations there’s no problem with doing this: it’s how a large portion of international Internet traffic flows, as it’s cost prohibitive to maintain direct connections to each-and-every ISP in the world. However, relying on a backbone ISP to carry local traffic can be adverse to performance, sometimes due to the backbone carrier sending data to another network in a completely different city. This situation can lead to what’s known as tromboning, where in the worst case, traffic from one city destined to another ISP in the same city can travel vast distances to be exchanged and then return again. A CDN with IXP presence has the advantage of optimizing the path through which data flows within it’s network, cutting down on inefficient paths.
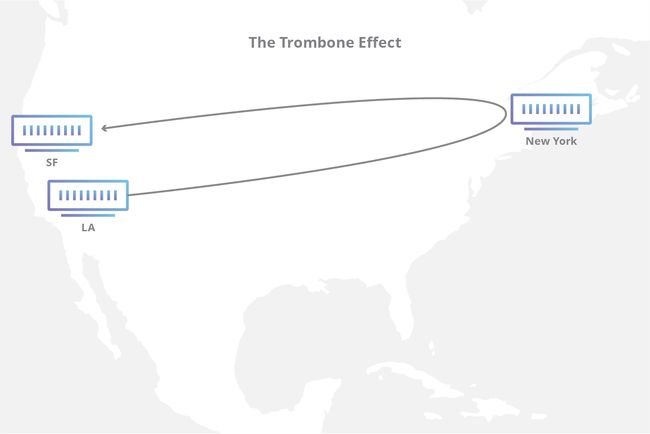
BGP, the Internet’s backbone protocol
Networks talk between each other using the BGP (Border Gateway Protocol). This protocol allows networks to cleanly delinerate between their internal requirements and their network-edge configurations. All peering at IXPs uses BGP
How do providers share traffic across different networks?
Transit
The agreement between a customer and it’s upstream provider. A transit provider provides its customers with full connectivity to the rest of the Internet. Transit is a paid-for service. BGP protocol is used to allow customer IP addresses to be announced towards the transit provider and then onwards towards the rest of the global Internet.
Peering
The arrangement behind how networks share IP addresses without an intermediary between them. At Internet exchange points, there is predominantly no cost associated with transferring data between member networks. When traffic is transferred for free from one network to the next, the relationship is called settlement-free peering.
Peering vs paid transit
Unfortunately for some networks, transferring data is not always without cost. For example, large networks with relatively equal market share are more likely to peer with other large networks but may charge smaller networks for the peering service. In a single IXP, a member company may have different arrangements with several different members. In instances like this, a company may configure their routing protocols to make sure that they optimize for reduced costs or reduced latency using the BGP protocol.
Deepering
Over time relationships can change, and sometimes networks no longer want to share free interconnection. When a network decides end their peering arrangement they go through a process called deepering. Deepering can occur for a variety of reasons such as when one party is benefiting more than the other due to bad traffic ratios, or when a network simply decides to start charging the other party money. This process can be highly emotional, and a spurned network may intentionally disrupt the traffic of the other party once the peering relationship has been terminated.
How do IXP’s use BGP?
Across an IXP's local network, different providers are able to create one-to-one connections using the BGP protocol. This protocol was created to allow disparate networks to announce their IP addresses to each other plus the IP addresses that they have provided connectivity to downstream (i.e. their customers). Once two networks set up a BGP session, their respective routes are exchanged and traffic can flow directly between them. Cloudflare CDN
IXP or PNI interconnection
Two networks may consider their traffic to be important enough that they want to move from the shared infrastructure of an IXP and onto a dedicated interconnection between the two networks. A PNI (Private Network Interconnect) is simply a dark fiber connection (normally within a single datacenter, or building) that directly connects a port on network A with a port on network B. The BGP is nearly identical as a shared IXP peering setup.
What is a reverse proxy?
A reverse proxy is a server that sits in front of web servers and forwards client (e.g. web browser) requests to those web servers. Reverse proxies are typically implemented to help increase security, performance, and reliability. In order to better understand how a reverse proxy works and the benefits it can provide, let’s first define what a proxy server is.
What’s a proxy server?
A forward proxy, often called a proxy, proxy server, or web proxy, is a server that sits in front of a group of client machines. When those computers make requests to sites and services on the Internet, the proxy server intercepts those requests and then communicates with web servers on behalf of those clients, like a middleman.
For example, let’s name 3 computers involved in a typical forward proxy communication:
- A: This is a user’s home computer
- B: This is a forward proxy server
- C: This is a website’s origin server (where the website data is stored)
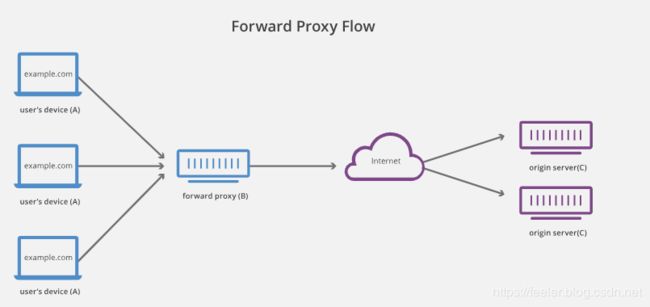
In a standard Internet communication, computer A would reach out directly to computer C, with the client sending requests to the origin server and the origin server responding to the client. When a forward proxy is in place, A will instead send requests to B, which will then forward the request to C. C will then send a response to B, which will forward the response back to A.
Why would anyone add this extra middleman to their Internet activity? There are a few reasons one might want to use a forward proxy:
- To avoid state or institutional browsing restrictions - Some governments, schools, and other organizations use firewalls to give their users access to a limited version of the Internet. A forward proxy can be used to get around these restrictions, as they let the user connect to the proxy rather than directly to the sites they are visiting.
- To block access to certain content - Conversely, proxies can also be set up to block a group of users from accessing certain sites. For example, a school network might be configured to connect to the web through a proxy which enables content filtering rules, refusing to forward responses from Facebook and other social media sites.
- To protect their identity online - In some cases, regular Internet users simply desire increased anonymity online, but in other cases, Internet users live in places where the government can impose serious consequences to political dissidents. Criticizing the government in a web forum or on social media can lead to fines or imprisonment for these users. If one of these dissidents uses a forward proxy to connect to a website where they post politically sensitive comments, the IP address used to post the comments will be harder to trace back to the dissident. Only the IP address of the proxy server will be visible.
How is a reverse proxy different?
A reverse proxy is a server that sits in front of one or more web servers, intercepting requests from clients. This is different from a forward proxy, where the proxy sits in front of the clients. With a reverse proxy, when clients send requests to the origin server of a website, those requests are intercepted at the network edge by the reverse proxy server. The reverse proxy server will then send requests to and receive responses from the origin server.
The difference between a forward and reverse proxy is subtle but important. A simplified way to sum it up would be to say that a forward proxy sits in front of a client and ensures that no origin server ever communicates directly with that specific client. On the other hand, a reverse proxy sits in front of an origin server and ensures that no client ever communicates directly with that origin server.
Once again, let’s illustrate by naming the computers involved:
- D: Any number of users’ home computers
- E: This is a reverse proxy server
- F: One or more origin servers
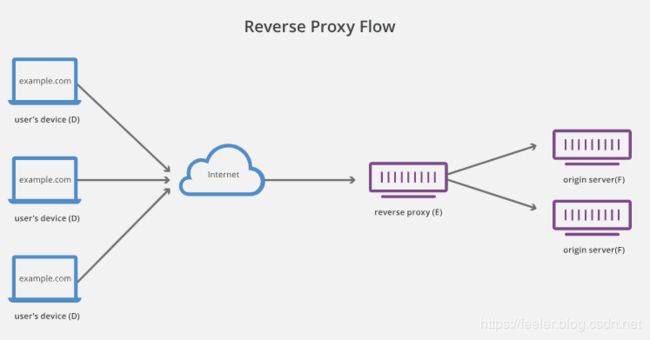
Typically all requests from D would go directly to F, and F would send responses directly to D. With a reverse proxy, all requests from D will go directly to E, and E will send its requests to and receive responses from F. E will then pass along the appropriate responses to D.
Below we outline some of the benefits of a reverse proxy:
- Load balancing - A popular website that gets millions of users every day may not be able to handle all of its incoming site traffic with a single origin server. Instead, the site can be distributed among a pool of different servers, all handling requests for the same site. In this case, a reverse proxy can provide a load balancing solution which will distribute the incoming traffic evenly among the different servers to prevent any single server from becoming overloaded. In the event that a server fails completely, other servers can step up to handle the traffic.
- Protection from attacks - With a reverse proxy in place, a web site or service never needs to reveal the IP address of their origin server(s). This makes it much harder for attackers to leverage a targeted attack against them, such as a DDoS attack. Instead the attackers will only be able to target the reverse proxy, such as Cloudflare’s CDN, which will have tighter security and more resources to fend off a cyber attack.
- Global Server Load Balancing (GSLB) - In this form of load balancing, a website can be distributed on several servers around the globe and the reverse proxy will send clients to the server that’s geographically closest to them. This decreases the distances that requests and responses need to travel, minimizing load times.
- Caching - A reverse proxy can also cache content, resulting in faster performance. For example, if a user in Paris visits a reverse-proxied website with web servers in Los Angeles, the user might actually connect to a local reverse proxy server in Paris, which will then have to communicate with an origin server in L.A. The proxy server can then cache (or temporarily save) the response data. Subsequent Parisian users who browse the site will then get the locally cached version from the Parisian reverse proxy server, resulting in much faster performance.
- SSL encryption - Encrypting and decrypting SSL (or TLS) communications for each client can be computationally expensive for an origin server. A reverse proxy can be configured to decrypt all incoming requests and encrypt all outgoing responses, freeing up valuable resources on the origin server.
How to implement a reverse proxy
Some companies build their own reverse proxies, but this requires intensive software and hardware engineering resources, as well as a significant investment in physical hardware. One of the easiest and most cost-effective ways to reap all the benefits of a reverse proxy is by signing up for a CDN service.
What is time-to-live (TTL) in networking?
Time to live (TTL) refers to the amount of time or “hops” that a packet is set to exist inside a network before being discarded by a router. TTL is also used in other contexts including CDN caching and DNS caching.
How does TTL work?
When a packet of information is created and sent out across the Internet, there is a risk that it will continue to pass from router to router indefinitely. To mitigate this possibility, packets are designed with an expiration called a time-to-live or hop limit. Packet TTL can also be useful in determining how long a packet has been in circulation, and allow the sender to receive information about a packet’s path through the Internet.
Each packet has a place where it stores a numerical value determining how much longer it should continue to move through the network. Every time a router receives a packet, it subtracts one from the TTL count and then passes it onto the next location in the network. If at any point the TTL count is equal to zero after the subtraction, the router will discard the packet and send an ICMP messageback to the originating host.
The commonly used network commands ping and traceroute both utilize TTL. When using the traceroute command, a stream of packets with increasingly higher sequential TTLs are sent across the Internet towards a destination. Because each step along the connection is the last stop for one of the packets, each location will return an ICMP message to the sender after discarding the packet. The time it takes for the ICMP message to return to the sender is then used to determine how long it takes to get to each successive hop along the network.
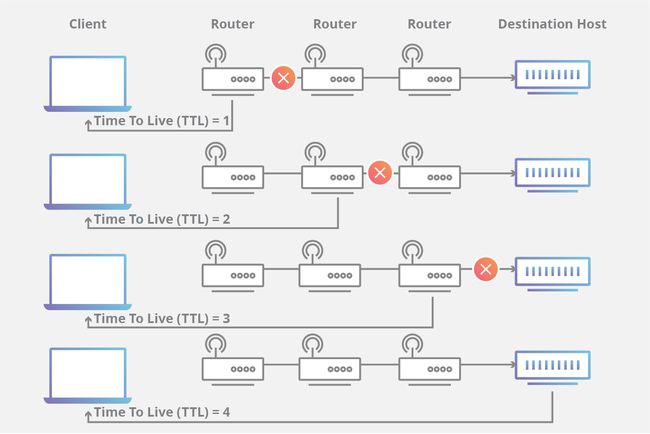
In what other circumstances is TTL used?
Apart from tracing the route packets take across the Internet, time-to-live is used in the context of caching information for a set period of time. Instead of measuring time in hops between routers, each of which can take a variable amount of time, some networking use cases operate in a more traditional fashion.
CDN's like Cloudflare's CDN commonly use a TTL to determine how long cached content should be served from a CDN edge server before a new copy will be fetched from an origin server. By properly setting the amount of time between origin server pulls, a CDN is able to serve updated content without requests continuously propagating back to the origin. This optimization allows a CDN to efficiently serve content closer to a user while reducing the bandwidth required from the origin.
In the context of a DNS record, TTL is a numerical value that determines how long a DNS cache server can serve a DNS record before reaching out to the authoritative DNS server and getting a new copy of the record.
What is cache-control?
Cache-control is an HTTP header that dictates browser caching behavior. In a nutshell, when someone visits a website, their browser will save certain resources, such as images and website data, in a store called the cache. When that user revisits the same website, cache-control sets the rules which determine whether that user will have those resources loaded from their local cache, or whether the browser will have to send a request to the server for fresh resources. In order to understand cache-control in greater depth, a basic understanding of browser caching and HTTP headers is required.
What is browser caching?
As explained above, browser caching is when a web browser saves website resources so it doesn’t have to fetch them again from a server. For example, a background image on a website might be saved locally in cache so that when a user visits that page for the second time, the image will load from the user’s local files and the page will load much faster.
Browsers will only store these resources for a specified period of time, known as the Time To Live (TTL). If a user requests a cached resource after the TTL has expired, the browser will have to reach out to the server again and download a fresh copy of the resource. How do browsers and web servers know the TTL for each resource? This is where HTTP headers come into play.
What are HTTP headers?
The Hypertext Transfer Protocol (HTTP) outlines the syntax for communications on the World Wide Web, and this communication consists of requests from clients to servers and responses from servers back to clients. These HTTP requests and responses each come stamped with a series of key-value pairs called headers.
These headers contain a lot of important information about each communication. For example, a request header usually contains:
- Information on what resource is being requested
- Which browser the client is using
- What data formats the client will accept
Response headers often include information on:
- Whether or not the request was successfully fulfilled
- The language and format of any resources in the body of the response.
A cache-control header can appear in both HTTP requests and responses.
What’s in a cache-control header?
Headers consist of key-value pairs which are separated by a colon. For cache-control, the ‘key’, or the part to the left of the colon, is always ‘cache-control’. The ‘value’ is what’s found on the right of the colon, and there can be one or several comma-separated values for cache control.
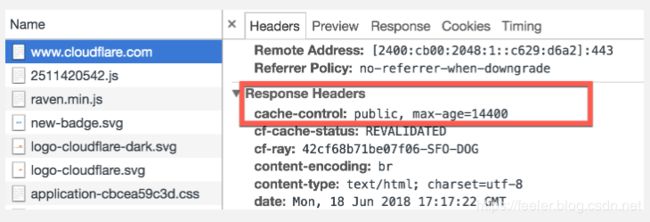
These values are called directives, and they dictate who can cache a resource as well as how long those resources can be cached before they must be updated. Below we go through some of the most common cache-control directives:
cache-control: private
A response with a ‘private’ directive can only be cached by the client and never by an intermediary agent, such as a CDN or a proxy. These are often resources containing private data, such as a website displaying a user’s personal information.
cache-control: public
Conversely, the ‘public’ directive means the resource can be stored by any cache.
cache-control: no-store
A response with a ‘no-store’ directive cannot be cached anywhere, ever. This means that every time a user requests this data, a request must be sent to the origin server for a fresh copy. This directive is typically reserved for resources that contain extremely sensitive data, such as bank account information.
cache-control: no-cache
This directive means that cached versions of the requested resource cannot be used without first checking to see if there is an updated version. This is typically done using an ETag.
An ETag is another HTTP header which contains a token unique to the version of the resource at the time it was requested. This token is changed on the origin server whenever the resource is updated.
When a user returns to a page with a ‘no-cache’ resource, the client will always have to connect to the origin server and compare the ETag on the cached resource with one on the server. If the ETags are identical, the cached resource will be provided to the user. If not, this means that the resource has been updated and the client will need to download a fresh version to provide to the user. This process ensures that the user is always getting the most up-to-date version of that resource without requiring unnecessary downloads.
cache-control: max-age
This directive dictates the time to live, in other words how many seconds a resource can be served from cache after it's been downloaded. For example, if the max age is set to 1800, this means that for 1,800 seconds (30 minutes) after the resource was first requested from the server, the user will be served a cached version of that resource on subsequent requests. If the user requests the resource again after that 30 minutes has expired, the client will have to request a fresh copy from the origin server.
The ‘s-maxage’ directive is specifically for shared caches such as CDNs, and it dictates how long those shared caches can keep serving up the resource from cache. This directive overrides the ‘max-age’ directive for individual clients.
Why does cache-control matter?
Browser caching is a great way to both preserve resources and improve user experience on the Internet, but without cache-control, it would be very brittle. Every resource on every site would be bound by the same caching rules, meaning that sensitive information would be cached the same way as public information, and frequently-updated resources would be cached for the same amount of time as ones that rarely change.
What Is GSLB?
Global Server Load Balancing or GSLB is the practice of distributing Internet traffic amongst a large number of connected servers dispersed around the world. The benefits of GSLB include increased reliability and reductions in latency.
Imagine a store that sells shoes through the mail to customers all over the world. If that shoe store operates out of a single location, it will take a very long time for faraway customers to submit orders and receive their shoes. During busy shopping seasons, the store might get overloaded with orders and lose the ability to fill all their customers’ orders quickly.
Now imagine that the shoe store opens several more locations all over the world. This means customers can order shoes from a nearby location, cutting down on shipping times and reducing the possibility of one store getting overloaded with orders. This is exactly what GSLB does for web sites and services, making it one of the most popular load balancing solutions for companies with a global user base.
What is load balancing?
Load balancing is the practice of distributing traffic among two or more servers. Some load balancing technique utilize a ‘dumb’ load balancing strategy, based on randomizing the distribution of traffic. For example round-robin DNS, a randomized DNS load balancing technique, sends each request to a different server than the last. There are also ‘smart’ load balancing techniques that analyze data in order to decide which is the best server to handle a request. Anycast routing, for example, picks a server based in part on the quickest travel time between the client and the server.
How does GSLB reduce latency?
Even before an origin server overloads and stops fulfilling requests, high amounts of traffic to that server can still cause significant latency issues. A GSLB system can distribute that traffic among several different locations, ensuring that no single location is handling so many requests that it causes delay.
Additionally GSLB can greatly reduce the travel time of requests and responses between users and servers. If a user is in Los Angeles and they are using a web service with a Paris-based origin server, then both the requests and responses will have to travel a very long distance, cut up into smaller travel segments called ‘hops’. This can cause significant delays in load time.
Using GSLB, a worldwide pool of servers ensures that each user can connect to a server that is geographically close to them, minimizing hops and travel time. In the example above, if the Paris-based company was utilizing GSLB, the Los Angeles user could connect to a server within 100 miles of their location, resulting in a much snappier user experience.