Tensorflow之构建自己的图像分类器
阅读本文时,假设你对inception有一定的了解。主要使用inception v3的模型,再后面接一个softmax,做一个分类器。具体代码都是参照tf github。
直接上干货。先简要描述下大致步骤,一句话来讲,将原先的softmax输出抛弃,自定义分类的种类,训练参数,得到自己的分类模型
步骤一:数据准备,准备自己要分类的图片训练样本。
项目下需要有以下文件夹:
bottleneck(空文件夹)
data(存放要训练的图片数据)
images(用来测试的图片数据)
注意,使用的训练数据集可以去牛津大学的Visual Geometry Group下载
步骤二:retrain.py 程序,用于下载inception v3模型及训练后面的分类器,在inception模型基础上进行自己图片分类的代码
retrain.py大家可以去github tensorflow 下载,此处给出链接:
retrain.py
步骤三:训练 命令
可以通过批处理脚本文件来执行。
如果你是windows:
#window下的批处理文件
#logdir 为retrain.py文件的根路径
#modeldir 为inception模型的参数模型文件(tgz格式)
#imagedir 为自定义训练的图片路径(图片的路径下各种类型的图片建立自己的文件夹,同时不能有大写字母)
python logdir/retrain.py ^
--bottleneck_dir bottleneck ^
--how_many_training_steps 200 ^
--model_dir modeldir ^
--output_graph output_graph.pb ^
--output_labels output_labels.txt ^
--image_dir datadir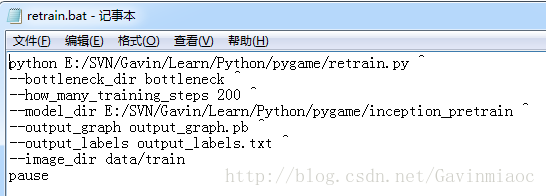
如果你用的Linux:
#linux 下的脚本文件 run.sh
#!/bin/sh
python logdir/retrain.py \
--bottleneck_dir bottleneck \
--how_many_training_steps 200 \
--model_dir modeldir \
--output_graph output_graph.pb \
--output_labels output_labels.txt \
--image_dir datadir步骤四:运行脚本程序。运行后会生成output_graph.pb和output_labels.txt两个文件 。
运行图:

文件夹下的内容如下图:
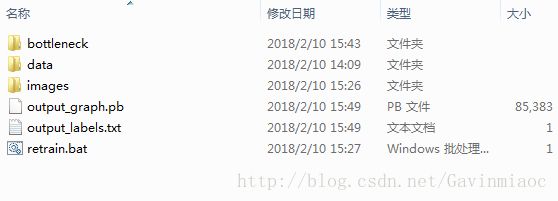
第一个pb文件为参数文件,第二个txt是标识图片类别的文件,同时bottleneck文件夹中也会有数据,每张图片都会有一个文件保存数据,一种图片传入进来之后,按照inception模型中的参数计算到bottleneck,保存的就是每一步图片与模型参数计算后的结果:
之后就可以用这两个文件(.pb和.txt文件)来进行图片分类。
步骤五:预测 prediction.py 程序,用于调用新生成的模型预测新数据的结果。
这里有两步,
1,首先需要建立一个images文件夹在文件中存放需要测试的图片
2,编写测试代码。这里直接给出:
import tensorflow as tf
import os
import numpy as np
import re
from PIL import Image
import matplotlib.pyplot as plt
lines = tf.gfile.GFile('retrain/output_labels.txt').readlines()
uid_to_human ={}
#读取参数中的数据
for uid,line in enumerate(lines):
line=line.strip('\n')
uid_to_human[uid]=line
def id_to_string(node_id):
if node_id not in uid_to_human:
return ''
return uid_to_human[node_id]
#创建图来存放训练好的模型参数
with tf.gfile.FastGFile('retrain/output_graph.pb','rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def,name='')
#测试图片分类
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('final_result:0')
#遍历目录
for root,dirs,files in os.walk('retrain/images/'):
for file in files:
#载入图片
image_data = tf.gfile.FastGFile(os.path.join(root,file),'rb').read()
#jpeg格式的图片
predictions = sess.run(softmax_tensor,{'DecodeJpeg/contents:0':image_data})
#结果转为1维度
predictions = np.squeeze(predictions)
#打印图片信息
image_path = os.path.join(root,file)
print (image_path)
#显示图片
img=Image.open(image_path)
plt.imshow(img)
plt.axis("off")
plt.show()
#排序
top_k = predictions.argsort()[::-1]
print(top_k)
for node_id in top_k:
human_string =id_to_string(node_id)
#置信度
score = predictions[node_id]
print ('%s (score = %.5f)' % (human_string, score))
print()
retrain/images/Abyssinian_33.jpg
[0 1]
animal (score = 0.97460)
flower (score = 0.02540)
retrain/images/Abyssinian_5.jpg2.

retrain/images/Abyssinian_5.jpg
[0 1]
animal (score = 0.98604)
flower (score = 0.01396)3.

retrain/images/image_0465.jpg
[1 0]
flower (score = 0.98178)
animal (score = 0.01822)4.

retrain/images/image_0472.jpg
[1 0]
flower (score = 0.93112)
animal (score = 0.06888)5.

retrain/images/image_0482.jpg
[1 0]
flower (score = 0.92636)
animal (score = 0.07364)由于我是只分了宠物和花2种类别。所以识别率还是很高的。