Python知识点——遍历文件、excel操作、数据合并操作
目录
- 目标问题
- 原始数据
- 最终输出
- 代码内容
- 知识点储备
- 遍历文件
- 概述
- 参数
- 实例
- 注意:
- excel操作
- excel读操作
- 注意:
- 代码示例
- excel 写操作
- 数据处理
- 处理末尾的换行符
- 文件名去重
目标问题
本文中主要是将相同后缀的多个文件合并到excel中,通过此思路可以解决:
- 完成不同类型的文件向excel的操作。
- 完成不同sheet的excel操作。
原始数据
1. 文件夹内容

2. 单个文件内容,以14.G1125为例

最终输出
1 最终效果

2 单个文件内容
说明:相同站点放到同一个excel中,不同日期放到不同的sheet中。

代码内容
import os
import xlwt
'''
Author:zflyee
思路:
1. 先对所有文件名进行收集并切分后去重
2. 再找到所有后缀文件名的路径
3. 做循环读入数据,同一个excel的不同sheet里面
'''
# 获取所有的文件后缀名
def file_name(file_dir):
name_suffix=[] # 创建文件后缀列表
file_path=[] # 创建文件路径空列表
for root, dirs, files in os.walk(file_dir): # 遍历文件,返回一个三元组
# 获取文件所有路径
for file in files:
file_path.append(os.path.join(root,file)) # 拼接文件路径
L=file.split('.')[1] # 得到文件的后缀
if L not in name_suffix: # 去重
name_suffix.append(L)
return file_path,name_suffix # 返回文件名路径与后缀路径
def main():
## 汇总同后缀名文件
dir_path='W:\Solar Radiation\Data\Data_original\Temp_data\秒级数据' # 设置文件路径
File_Path,Name_Suffix=file_name(dir_path) #得到所有文件名的路径 和 后缀名的列表
# print(Name_Suffix)
## 进行数据处理
for upfile in Name_Suffix: # 遍历所有后缀
res_path=r'W:\Solar Radiation\Data\Data_original\Temp_data\res/'+upfile+'.xls' #以后缀为文件名,然后设置文件输出路径
DataWriter=xlwt.Workbook(style_compression=0) # 创建一个excel
for file in File_Path: # 遍历所有文件路径
data_name = os.path.basename(file).split(sep='.')[0] # 得到每个数据文件的名称
data_suffix = os.path.basename(file).split(sep='.')[1] # 得到每个数据文件的后缀
# 核心部分
if data_suffix==upfile: # 对比数据文件后缀与列标中的后缀
sheet = DataWriter.add_sheet(data_name, cell_overwrite_ok=True) # 在打开的excel中增加数据文件的sheet
f=open(file, encoding='utf-8') # 读取单个文件,注意转码
lines=f.readlines() # 读取内容,常规操作
i=0 # 这里设置单元格的“行”
for line in lines: # 读取每一行数据
line=line.strip('\n') # 去掉每行末尾的转行符
# print(line) # 为了有安全感,可以选择打印
# 下面偷了个懒,读者可以根据实际需要写入不同的列!
sheet.write(i,0,line) # 将每一行数据写入到excel的第i行,第1列中(python中,是从0开始计数的),可以
i+=1 # 设置下一行
f.close() # 关闭文件
DataWriter.save(res_path) # 保存写完的excel
if __name__ == '__main__':
main()
知识点储备
下面是我在处理过程中用到的主要知识点,仅供参考~
遍历文件
概述
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
在Unix,Windows中有效。
语法
walk()方法语法格式如下:
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
参数
- top – 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
– root 所指的是当前正在遍历的这个文件夹的本身的地址
– dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
– files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录) - topdown --可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
- onerror – 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
- followlinks – 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-import osfor root, dirs, files in os.walk(".", topdown=False):for name in files:print(os.path.join(root, name))for name in dirs:print(os.path.join(root, name))
注意:
在一个目录下面只有文件,没有文件夹,这个时候可以使用os.listdir
在我们的桌面上有一个file目录(文件夹),里面有三个文件
file(dir)|
–|test1.txt
–|test2.txt
–|test3.txt
用下面的程序获得文件的绝对路径:
import os
path = r'C:\Users\Administrator\Desktop\file'
for filename in os.listdir(path):
print(os.path.join(path,filename))
使用os.listdir读取到一个目录下面所有的文件名,然后使用os.path.join把目录的路径和文件名结合起来,就得到了文件的绝路路径,结果如下:
C:\Users\Administrator\Desktop\file\test1.txt
C:\Users\Administrator\Desktop\file\test2.txt
C:\Users\Administrator\Desktop\file\test3.txt
excel操作
excel读操作
功能:读取一个excel里的第2个sheet,将该sheet的内容全部输出。
#coding=utf8
import xlrd
def read_excel():
workbook = xlrd.open_workbook('demo.xlsx')
sheet2 = workbook.sheet_by_index(1) # sheet索引从0开始
rowNum = sheet2.nrows
colNum = sheet2.ncols
llst = []
for i in range(rowNum):
lst = []
for j in range(colNum):
lst.append(sheet2.cell_value(i, j))
llst.append(lst)
for i in range(rowNum):
for j in range(colNum):
print(llst[i][j],'\t\t',)# 这里的逗号是为了不让换行
print
if __name__ == '__main__':
read_excel()
注意:
- python对于缩进非常严苛。如果最后两句话不小心向后缩进了一下,与17行的for对齐了,那说明这两句话是read_excel函数体内部的。那就乱套了。
- 指定一个excel里的具体哪一个sheet,即可以按序号顺序来定位(比如第一个sheet,第2个sheet),也可以按名字来找(比如第2个sheet如果名字叫‘Sheet2’的话,就用
workbook.sheet_by_name('Sheet2')来定位sheet。 - 获取一个cell里面的内容,可以有多种方式,比如:
sheet2.cell_value(1,0)
sheet2.row(1)[0].value
sheet2.cell(1,0).value - 读取到的excel的表格里的值都是unicode模式的。这种情况下如果想正确输出的话,直接print就可以。比如放在list里面,依次对list的每个元素进行print。但是不能直接print lst。这样的话打出来还是unicode的形式。正常情况下对于unicode的对象,用encode可以将一个unicode对象转换为参数中编码格式的普通字符。这一部分可参考 了解Unicode
代码示例
情景:读取原始excel内容并打印出来

#coding=utf8
import xlrd
def read_excel():
# 打开文件
workbook = xlrd.open_workbook('demo.xlsx')
# 获取所有sheet
#print workbook.sheet_names() # [u'Sheet1', u'Sheet2']
sheet2_name = workbook.sheet_names()[1]
# 根据sheet索引或者名称获取sheet内容
sheet2 = workbook.sheet_by_index(1) # sheet索引从0开始
sheet2 = workbook.sheet_by_name('Sheet2')
# sheet的名称,行数,列数
print 'sheet的名称,行数,列数'
print sheet2.name,sheet2.nrows,sheet2.ncols
rowNum = sheet2.nrows
colNum = sheet2.ncols
# 获取整行和整列的值(数组)
rows = sheet2.row_values(3) # 获取第四行内容
cols = sheet2.col_values(2) # 获取第三列内容
print '第四行:'
print rows
llst = []
for i in range(rowNum):
lst = []
for j in range(colNum):
lst.append(sheet2.cell_value(i, j))
llst.append(lst)
for i in range(rowNum):
for j in range(colNum):
print llst[i][j],'\t\t',
print
if __name__ == '__main__':
read_excel()
输出

excel 写操作
#coding=utf8
'''
设置单元格样式
'''
import xlwt, xlrd
def set_style(name,height,bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
# borders= xlwt.Borders()
# borders.left= 6
# borders.right= 6
# borders.top= 6
# borders.bottom= 6
style.font = font
# style.borders = borders
return style
#写excel
def write_excel():
f = xlwt.Workbook() #创建工作簿
'''
创建第一个sheet:
sheet1
'''
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) #创建sheet
row0 = [u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计']
column0 = [u'机票',u'船票',u'火车票',u'汽车票',u'其它']
status = [u'预订',u'出票',u'退票',u'业务小计']
#生成第一行
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
#生成第一列和最后一列(合并4行)
i, j = 1, 0
while i < 4*len(column0) and j < len(column0):
sheet1.write_merge(i,i+3,0,0,column0[j],set_style('Arial',220,True)) #第一列
sheet1.write_merge(i,i+3,7,7) #最后一列"合计"
i += 4
j += 1
sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
#生成第二列
i = 0
while i < 4*len(column0):
for j in range(0,len(status)):
sheet1.write(j+i+1,1,status[j])
i += 4
f.save('demo1.xls') #保存文件.这里如果是.xlsx的话会打不开。
if __name__ == '__main__':
#generate_workbook()
#read_excel()
write_excel()
注意:最终生成的文件如果是demo1.xlsx的话打不开,.xls就没问题。
如果对一个单元格重复操作,会引发error。所以在打开时加cell_overwrite_ok=True解决
table = file.add_sheet('sheet name',cell_overwrite_ok=True)
生成的demo1.xls效果如下。
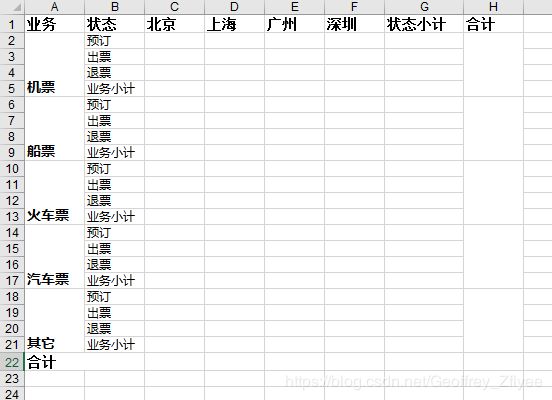
数据处理
处理末尾的换行符
程序如下:
for line in file.readlines():
line=line.strip('\n')
使用strip()函数去掉每行结束的\n
strip()函数原型
声明:s为字符串,rm为要删除的字符序列
s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符
s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符
注意:
当rm为空时,默认删除空白符(包括’\n’, ‘\r’, ‘\t’, ’ ')
文件名去重
方案一:通过列表去重
情况:读取同一个文件夹下所有相同的后缀名,原始文件如下

def file_name(file_dir):
name_suffix=[]
file_path=[]
for root, dirs, files in os.walk(file_dir): # 改
# 获取文件所有路径
for file in files:
file_path.append(os.path.join(root,file))
L=file.split('.')[1]
if L not in name_suffix:
name_suffix.append(L)
return file_path,name_suffix
这是最后数据的后缀名集合
['G1125', 'G1132', 'G1143', 'G1145', 'G1179', 'G1189', 'G3526', 'G3536', 'G3544', 'G3555', 'G3561', 'G3567', 'G3636', 'G3726', 'G3779']
方案二:通过集合去重
思路是通过将其他类型的数据变成集合,利用集合的元素唯一性来去重