0685-6.2.0-什么是Cloudera虚拟私有集群和SDX-续
Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f,或者扫描文末二维码。
本文是续上一篇文章《0667-6.2.0-什么是Cloudera虚拟私有集群和SDX》
5 虚拟私有群集的兼容性注意事项
5.1 CDH版本兼容性
Compute集群的CDH版本必须与Base集群的major.minor版本匹配。未来可能会添加对Compute和Base集群版本的其他组合的支持。VPC支持以下CDH版本:
CDH 5.15
CDH 5.16
CDH 6.0
CDH 6.1
CDH 6.2
5.2 CDH组件
1.Kafka - Compute集群不支持
2.SOLR - Compute集群不支持
3.Kudu - Compute集群不支持
Compute集群上的Impala不能访问Hive Metastore中的Kudu数据
4.HDFS
a)Compute集群需要“本地”HDFS服务作为临时的持久空间,目的是将其用于Hive查询临时数据,也建议用于多阶段Spark ETL作业。
b)Cloudera建议每个主机存储最小空间为1TB,配置为HDFS DataNode存储目录。
c)Base集群必须具备HDFS服务。
d)Base集群不支持Isilon。
e)只有Base集群才支持S3或ADLS连接器,Compute集群使用与其关联的Base集群的S3或ADLS证书。
f)Base集群上的HDFS服务必须配置HA高可用。
g)Cloudera强烈建议在Compute群集上为HDFS服务启用高可用性,但这不是必需的。
h)Base和Compute集群的namespace命名空间必须不相同。
i)Compute集群上本地HDFS服务的以下配置必须与Base群集上的配置匹配,为了使Compute集群上的服务能够正常访问Base集群上的服务:
i.Hadoop RPC protection
ii.Data Transfer protection
iii.Enable Data Transfer Encryption
iv.Kerberos Configurations
v.TLS/SSL Configuration(仅当集群没有启用 Auto-TLS时)
j)请勿使用“高级配置代码段”覆盖Compute集群中的namespace名称服务配置。
k)Compute集群home目录的HDFS路径使用以下格式:
/mc//fs/user
您可以通过单击Cloudera Manager Admin Console中的集群名称找到
http://myco-1.prod.com:7180/cmf/clusters/1/status
5.Backup and Disaster Recovery (BDR) - 如果源集群是Compute集群,或者目标集群的Cloudera Manager的版本低于6.2,都不支持。
6.YARN和MapReduce
如果Base集群既配置了MapReduce(MR1,在CM6中已弃用)和YARN(MR2),因为Cloudera Manager中处理服务依赖的方式,Compute集群中的相关服务(如Hive Execution Service)将使用MR1。要使用YARN,您可以更新配置,以便在应用程序中使用YARN之前使这些Compute集群服务依赖于YARN(MR2)。
7.Impala
a)摄取新数据或元数据到Base集群会影响Hive Metastore,如果Compute集群中安装了Impala,需要在Compute集群中运行INVALIDATE METADATA或REFRESH METADATA。
b)Impala中的一致性由Catalog服务(catalogd)中的表级锁保证。对于多个Compute集群,通过多个集群中的多个catalogd访问相同的表或者数据会导致问题。例如,在删除文件时查询可能会失败,或者当在一个集群上运行刷新命令,但同时另一个集群正在摄取数据到Impala中如果只进行了一般,这时会导致元数据不正确。为避免一致性问题,Impala集群应在互斥的表和数据集上运行。
8.Hue
a)Compute集群上仅支持一个Hue服务实例。
b)Compute集群上的Hue服务不会与其他Compute集群上的Hue服务或Base集群上的Hue服务共享用户特定的查询历史记录。
c)由于创建表和插入数据的权限不同,Hue示例可能无法正确安装。您可以通过删除示例表然后重新添加它们来解决此问题。
d)如果在创建完Compute集群后才添加Hue服务,则需要在Compute集群中手动配置对其他服务(如Hive,Hive Execution Service和Impala)的依赖关系。
9.Hive Execution Service
新引入的“Hive execution service”仅支持Compute集群,Base或Regular集群不支持该服务。要使Hue能够在Compute集群上运行Hive查询,您必须在Compute集群上安装Hive Execution Service。
5.3 Compute集群服务
Compute集群上只能安装以下服务:
Hive Execution Service (此服务只提供给HiveService2角色)
Hue
Impala
Spark2
Oozie (装Hue服务必须该服务)
YARN
HDFS (必须)
5.4 Cloudera Navigator支持
Compute集群不支持Navigator的元数据,审计,数据溯源和KMS。
5.5 Cloudera Manager权限
被授权仅查看Base或Compute集群的集群管理员只能查看和管理这些集群,但无法创建,删除或管理数据上下文(Data Contexts)。只有使用Full Administrator这个角色的管理员才能创建和删除数据上下文。
5.6 安全
1.KMS
a)Base Cluster
i.不支持Hadoop KMS
ii.Base集群支持KeyTrustee KMS
b)Compute Cluster:不支持任何类型的KMS
2.认证/用户目录
a)Base集群和Compute集群上的用户应该是完全一致的,就像在同一个集群一样。包括Linux本地用户,LDAP,Active Directory或其他第三方用户目录集成,都应该一致。
3.Kerberos
a)如果Base集群安装了Kerberos,则Compute集群也必须使用Kerberos,而且必须和Base集群在相同的Kerberos域中。Cloudera Manager可以在集群的创建过程中帮助完成该配置。
4.TLS
a)如果Base集群为集群服务配置了TLS,则Compute集群服务也必须配置TLS才能访问Base集群中的相应服务。
b)Cloudera强烈建议启用Auto-TLS以确保Base和Compute集群上的服务统一使用TLS进行通信。
c)如果您已配置TLS但未使用Auto-TLS,请注意以下事项:
d)使用Cloudera Manager为Compute添加主机时,必须在这些主机中创建相同的配置。将位于以下配置属性指定的目录中的所有文件从Base集群复制到Compute集群主机:
i.hadoop.security.group.mapping.ldap.ssl.keystore
ii.ssl.server.keystore.location
iii.ssl.client.truststore.location
e)创建Compute集群时,Cloudera Manager会将以下配置复制到Compute群集。
i.hadoop.security.group.mapping.ldap.use.ssl
ii.hadoop.security.group.mapping.ldap.ssl.keystore
iii.hadoop.security.group.mapping.ldap.ssl.keystore.password
iv.hadoop.ssl.enabled
v.ssl.server.keystore.location
vi.ssl.server.keystore.password
vii.ssl.server.keystore.keypassword
viii.ssl.client.truststore.location
ix.ssl.client.truststore.password
5.7 Compute集群的主机存储需求
如果Compute集群中运行了Impala服务,则Compute集群的主机需要附加存储,容量至少1TB。此存储用于Impala的暂存空间(scratch space),以及用于Compute集群本身的HDFS空间。
5.8 网络
在Compute集群上运行的工作负载将与Base集群上的主机进行大量通信; 客户应该对网络硬件(例如交换机,包括TOR,spine/leaf路由器等)进行网络监控,以跟踪和调整Compute集群机架与Base集群机架之间的带宽。
5.9 Altus Director
Altus Director不支持运行Compute集群,也不能用于创建Compute群集。
5.10 Cloudera Data Science Workbench (CDSW)
计算集群不支持CDSW。
6 虚拟私有集群的网络注意事项
6.1 最低网络性能要求
虚拟私有集群部署对网络性能有以下要求:
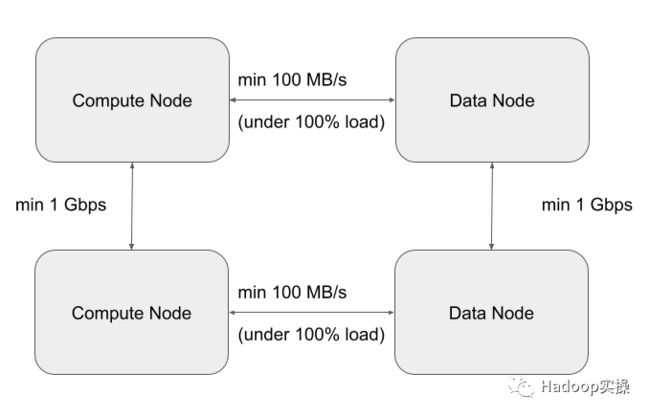
1.最坏情况下IO吞吐量为100MB/s,即任何计算节点和任何存储节点之间的网络吞吐(持续)为1Gb/s。为了达到最坏的情况,我们会测试当所有计算节点同时从存储节点读取/写入时的网络吞吐,这种并发执行也是典型的大数据应用程序。
2.最坏的情况是任何两个工作负载集群节点或任何两个Base集群节点之间的网络带宽为1Gbps。
下图总结了这些要求:
6.2 规划和设计网络拓扑
6.2.1 最低和推荐的性能要求
本章通过下表中列出的最小网络吞吐量,来了解最低要求。
注意:为了方便大家理解,后面的内容将使用以下术语:
南北(NS)流量模式表示Compute层和Storage层之间的网络流量。
东西(EW)流量模式表示Storage或Compute集群内的内部网络流量。

注意:后端Base集群上的存储跟Compute集群的节点连接数有关系,所以后端的存储不仅需要考虑容量,还包括吞吐量。由于后端的存储就是HDFS DataNode,因此需要对后端的存储节点进行合理规划,参考以下内容:
1.如果Base集群上的节点使用SATA磁盘,假设SATA磁盘在裸机上的吞吐为100MB/S,在使用DAS(Directly Attached Storage)的虚拟化集群中吞吐预计可以达到70-80MB/S。
2.每块磁盘需要一个物理的CPU核,因此,如果节点有12块磁盘,则这个节点至少应该有12个CPU核。
3.网络带宽应该规划为2倍的NS流量。例如,如果你的Base集群的一个节点有12块磁盘,则预期的NS流量应该是1200MB/S(1.2GB/S),也就大概需要~10Gbps的网络吞吐。而因为需要2倍的NS流量,所以可以为该节点规划20Gbps的网络,主要为了解决可能同时存在的EW流量。
4.Compute层和Storage层之间的网络连接需要考虑NS方向的流量的吞吐。本文后面的内容会继续讨论网络设计的注意事项,并说了不同的网络过载对于集群总吞吐量的影响。
6.2.2 网络拓扑注意事项
首选的网络拓扑是叶脊(spine-leaf)拓扑网络,在leaf和spine交换机之间的过载率接近1:1,理想情况是没有过载。这样我们就可以确保存储和计算节点的任何组合之间的全线路速率(full line-rate)。因为SDX的架构是存储和计算分离,所以为了达到最佳性能网络设计非常重要。
所需的最小网络吞吐包含以下2个方面,这也将决定计算与存储节点的比例。
1.后端存储集群的网络吞吐和磁盘IO吞吐能力。
2.计算和存储层之间的网络吞吐量和网络过载率,即南北流量(NS)。
让我们来举一个例子更好的理解这一点,假设搭建安装是绿地(greenfield)模式,计算节点和存储节点都是使用的虚拟机(VM):
1.因为EW和NS流量会共享总网络带宽,因此,对于1Gbps的NS流量,我们也应该规划1Gbps的EW流量。
2.计算和存储层之间的网络过载率为1:1。
3.后端存储集群包含5个节点(VM),每个节点有8块SATA盘。
a)对于后端存储集群,每个节点8块盘,假设每块盘的吞吐为100MB/S,则每节点总的磁盘IO吞吐为800MB/S,则一共5个节点的总IO吞吐在4GB/S。集群的网络吞吐总和为32Gbps,5*800MB/S=4GB/S,大B和小b用8换算,南北(NS)流量每节点需要7Gbps,32Gbps/5=~7Gbps。
b)考虑到EW+NS,我们需要每个节点14Gbps网络带宽来处理每个节点800MB/s的IO吞吐量。
4.然后,计算群集最好具有以下条件:
a)5个虚机节点,每个具有7 Gbps NS + 7 Gbps EW = 14Gbps的总网络吞吐。
b)这种情况可以处理~6个节点,最小吞吐量(100MB/s),前提是它的CPU和内存不是瓶颈,以便占满后端的流量(6 x 100 MB/s x 5 = 3000 MB/s)。每个节点应具有~2 Gbps的网络带宽,以满足NS+EW流量。
c)如果每节点的吞吐使用我们建议的200MB/S,则只需要3个这样的节点(3 x 200 MB/s x 5 = 3000 MB / s)。每个节点应具有~4 Gbps的网络带宽,以满足NS+EW流量。
假设计算节点和存储节点的比例为4:1,当然这个比例会因为实际情况有所不同,需要充分考虑各种工作负载才能做到更精确的节点数目规划。
以下表格按照假设计算节点和存储节点的比例为4:1,即50个节点的存储集群,200个阶段节点来举例说明:
Storage-Compute Node Level Sizing

Storage and Compute Hypervisor level sizing

根据不同的虚机整合率(consolidation ratios)和不同的吞吐量要求,上表给出了如何规划私有云每一层的硬件规划。
6.3 物理网络拓扑
Hadoop集群的最佳网络拓扑是spine-leaf。每个机架都有自己的叶子交换机,每个叶子交换机都连接到每个脊(spine)交换机。理想情况下我们不希望叶子和脊之间有任何过载,这样我们就可以确保存储和计算节点的任何组合之间的全线路速率(full line-rate)。
交换机,带宽等的选择可以基于前一章节的计算方法。
如果存储节点和计算节点在不同的机架,需要确保计算节点机架的交换机和存储节点机架的交换机之间的上行链路带宽至少与存储提供的理论最大值相同。换句话说,所有计算节点机架的带宽总和应该与存储节点所在机架的带宽总和相等。
例如,以上一节为例,应该在存储集群和计算集群节点之间至少有60Gbps的上行链路。
我们根据上章提到的例子构建所需的网络拓扑,需要满足以下要求:

假设所有机器都是2U的,我们需要5个42U的机架来装下所有硬件。
如果我们将每个层中的节点尽可能均匀地分布在5个机架上,我们最终会得到以下配置。
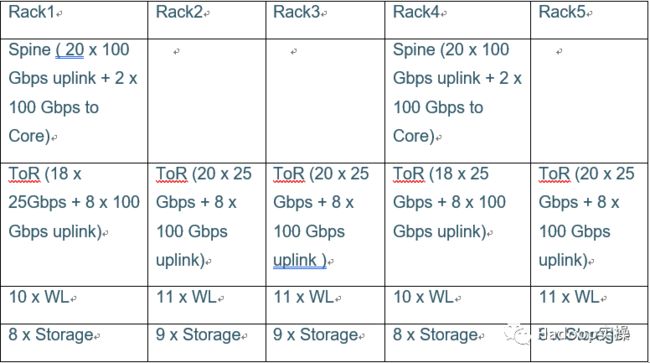
所以ToR交换机需要至少20 x 25 Gbps个端口以及8 x 100 Gbps上行链路端口。此外,Spine交换机至少需要22 x 100 Gbps端口。
使用来自叶子交换机的八个100Gbps上行链路将导致叶子(最多20 x 25 Gbps端口)和主干(每个主干交换机4 x 100 Gbps)之间几乎1:1(1.125:1)的过载率。
以下方式混合Workload和Storage节点将有助于将每个叶子的一些流量本地化,从而减少N-S流量(工作负载和存储集群之间)的压力。

注意:为了显示清楚,主干交换机画在了机架外面。
下图说明了虚拟机级别的逻辑拓扑。
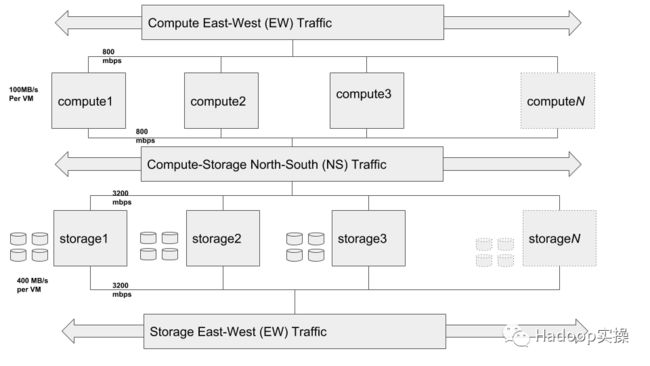
上面显示的存储E-W,计算N-S和计算E-W组件不是单独的网络,而是具有不同流量模式的相同网络,其已被分解以便清楚地表示不同的流量模式。
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操
