DenseNet及相关代码简介
论文:Densely Connected Convolutional Networks
论文链接:https://arxiv.org/pdf/1608.06993.pdf
这几年卷积神经网络的提升效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而论文作者则是从特征入手,以实现更好的效果和更少的参数的问题。DenseNet的优点可以主要概括为以下几个方面:
- 减轻了vanishing-gradient(梯度消失)
- 加强了feature的传递
- 更有效地利用了feature
- 一定程度上较少了参数数量
在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,目前很多论文都针对这个问题提出了解决方案,比如ResNet,Highway Networks,Stochastic depth,FractalNets等。至于DenseNet主要是在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来。
了解DenseNet就不得不提dense block的结构图,在传统的网络结构中,如果有L层,就会有L个连接,但是对于DenseNet就会有(L+1)*L/2个连接,简而言之,就是将所有层都连接到一起。如图所示,将X0当作Input,那么H2的输入就包括X0和H1的输出X1。
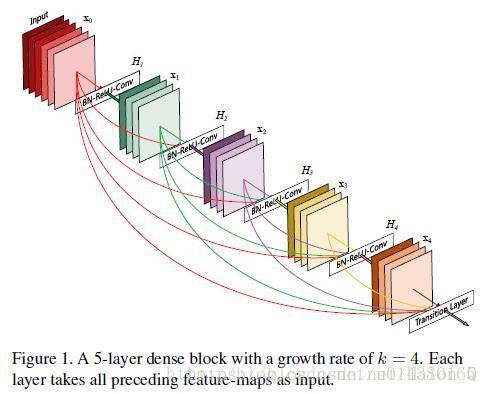
接下来我们侧重点在于DenseNet的网络的搭建,下面的图为DenseNet的结构图,在这个结构图中包含了3个dense block。论文的作者将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
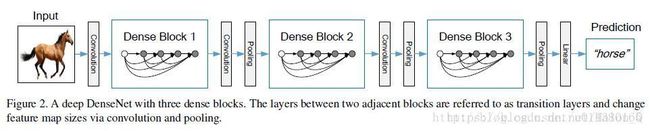
接下来,我们从代码层次下对DenseNet进行探讨,首先我们可以先看下论文中给的网络结构图。在这个表中,k=32,k=48中的k是growth rate,表示每个dense block中每层输出的feature map个数。为了避免网络变得很宽,作者都是采用较小的k,比如32这样,作者的实验也表明小的k可以有更好的效果。根据dense block的设计,后面几层可以得到前面所有层的输入,因此concat后的输入channel还是比较大的。另外这里每个dense block的3*3卷积前面都包含了一个1*1的卷积操作,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征。另外作者为了进一步压缩参数,在每两个dense block之间又增加了1*1的卷积操作。本次网络搭建设计中我们既有bottleneck layer,又有Translation layer。
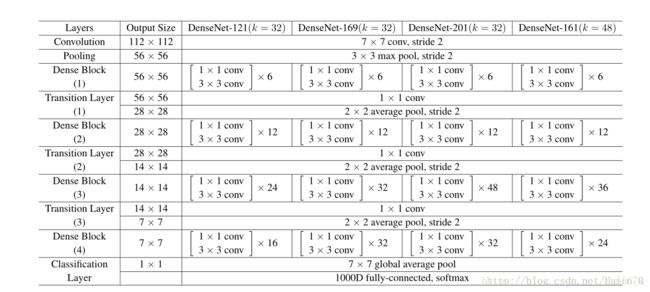
首先我们加一个卷积层和最大池化层,降低输入的维度,之后我们加入了一个循环,分别进行dense block和transition layer的操作,并且循环了3次,在此之后又加入了一个32层的dense block,它包含32个1*1和3*3的卷积操作,这样大大减少了计算量,具体内容我们将在dense block的bottleneck操作进行讲述。最后的操作就是将从dense block输出的结果进行BN操作等,进而完成网络的搭建。
def Dense_net(self, input_x):
x = conv_layer(input_x, filter=2 * self.filters, kernel=[7, 7], stride=2, layer_name='conv0')
x = Max_Pooling(x, pool_size=[3, 3], stride=2)
#3个dense block
for i in range(self.nb_blocks):
x = self.dense_block(input_x=x, nb_layers=self.list[i], layer_name='dense_' + str(i))
x = self.transition_layer(x, scope='trans_' + str(i))
x = self.dense_block(input_x=x, nb_layers=32, layer_name='dense_final')
x = Batch_Normalization(x, training=self.training, scope='linear_batch')
x = Relu(x)
x = Global_Average_Pooling(x)
x = flatten(x)
x = Linear(x)
return x
DenseNet中最重要的操作就是dense block,如何将输入concat一起,是本网络最大的难点。我们主要采用拼接的方式,将size等完全相同的输入拼接起来。在每个dense block中都包含很多个子结构,以最后一个dense block为例,包含32个1*1和3*3的卷积操作,也就是第32个子结构的输入是前面31层的输出结果,每层输出的channel是32(growth rate),那么如果不做bottleneck操作,第32层的3*3卷积操作的输入就是31*32+(上一个dense block的输出channel),近1000了。而加上1*1的卷积,代码中的1*1卷积的channel是growth rate*4,也就是128,然后再作为3*3卷积的输入。这就大大减少了计算量,这就是bottleneck。至于transition layer,放在两个dense block中间,是因为每个dense block结束后的输出channel个数很多,需要用1*1的卷积核来降维。虽然第32层的3*3卷积输出channel只有32个(growth rate),但是紧接着还会像前面几层一样有通道的concat操作,即将第32层的输出和第32层的输入做concat,前面说过第32层的输入是1000左右的channel,所以最后每个Dense Block的输出也是1000多的channel。因此这个transition layer有个参数reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是transition layer的作用。此外还有dropout操作来随机减少分支,避免过拟合。
def dense_block(self, input_x, nb_layers, layer_name):
with tf.name_scope(layer_name):
layers_concat = list()
layers_concat.append(input_x)#拼接到列表
x = self.bottleneck_layer(input_x, scope=layer_name + '_bottleN_' + str(0))
layers_concat.append(x)
for i in range(nb_layers - 1):
x = Concatenation(layers_concat)
x = self.bottleneck_layer(x, scope=layer_name + '_bottleN_' + str(i + 1))
layers_concat.append(x)
x = Concatenation(layers_concat)
return x
def transition_layer(self, x, scope):
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope + '_batch1')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[1, 1], layer_name=scope + '_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Average_pooling(x, pool_size=[2, 2], stride=2)
return x
def bottleneck_layer(self, x, scope) :
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope + '_batch1')
x = Relu(x)
x = conv_layer(x, filter=4 * self.filters, kernel=[1, 1], layer_name=scope + '_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Batch_Normalization(x, training=self.training, scope=scope + '_batch2')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[3, 3], layer_name=scope + '_conv2')
x = Drop_out(x, rate=dropout_rate, training=self.training)
return x