每周大数据论文(一)Data-intensive applications, challenges, techniques and technologies: A survey on Big Data
自以为读国外文献,总结记录新的思路,算法以及处理方法,总结文献内容,可以开拓视野,找出问题和创新点。记录下来也顺便告诉自己這篇论文讲的是什么,以备之后需要相关内容能快速翻阅到。也能和大家分享有关文献,需要此文献的留言邮箱,之后发给你们。
文章来源:Information Sciences
作者:C.L. Philip Chen , Chun-Yang Zhang
“This paper is aimed to demonstrate a close-up view about Big Data, including Big Data applications,Big Data opportunities and challenges, as well as the state-of-the-art techniques and technologies we currently adopt to deal with the Big Data problems. We also discuss several
underlying methodologies to handle the data deluge, for example, granular computing,
cloud computing, bio-inspired computing, and quantum computing.”——–ABSTRACT
这篇综述类的文献一共33叶,算是篇幅比较长了。文章分为7部分。
分别是:
1. Introduction
2. Big Data problems
3. Big Data opportunities and challenges
4. Big Data tools: techniques and technologies
5. Principles for designing Big Data systems
6. Underlying technologies and future researches
7. Conclusion
第一部分
文章先引用了国际社会对大数据的共识,给出了大数据的定义以及大数据的几个显著特点,其他就是泛泛而谈。大数据的定义:‘‘Big Data are high-volume, high-velocity, and/or high-variety information assets 。More generally, a data set can be called Big Data if it is formidable to perform capture, curation, analysis andvisualization on it at the current technologies.大数据的特点4V:volume, velocity variety virtual.
第二部分
这部分没有什么实质内容,就是从个领域包括金融,商业,政府等方面来说大数据问题成为迫切需要解决的问题
第三部分
“Challenges in Big Data analysis include data inconsistence and incompleteness, scalability, timeliness and data security ”数据不一致,不完整,数据的时效,扩展,数据安全是大数据面临的挑战。接下里作者从数据挖掘,数据存储,数据处理等几个角度简单谈了谈目前的技术,以及仍需要解决的问题。在数据综合处理的一小节中作者提到了目前比较主流的数据库“NoSQL database , also called ‘‘Not Only SQL’’, is a current approach for large and distributed data management and
database design. Its name easily leads to misunderstanding that NoSQL means ‘‘not SQL’’. On the contrary, NoSQL doesnot avoid SQL”并简单的进行了介绍,用handoop的HBase进行了进一步介绍。总体上说的还是一个概念,并没有什么典型的例证。之后也简单的提到了数据分析的概念,数据可视化的概念。
第四部分
这一部分我觉得我收获最多的一部分,也是我精读的一部分。
“We need tools (platforms) to make sense of Big Data. Current tools concentrate on three classes, namely, batch processing tools, stream processing tools, and interactive analysis tools. Most batch processing tools are based on the Apache Hadoop infrastructure, such as Mahout and Dryad. The latter is more like necessary for real-time analytic for stream data applications.Storm and S4 are good examples for large scale streaming data analytic platforms. The interactive analysis processes the data in an interactive environment, allowing users to undertake their own analysis of information. The user is directly connected to the computer and hence can interact with it in real time. The data can be reviewed, compared and analyzed in tabular or graphic format or both at the same time. Google’s Dremel and Apache Drill are Big Data platforms based on interactive analysis. In the following sub-sections, we’ll discuss several tools for each class. More information about Big Data tools can be found in Appendix C.”
目前处理大数据的工具一般分为三类:一种是批处理工具,一种是流式处理工具,最后一种是交互分析工具。批式处理工具国际上比较有知名度和市场的是基于Apache的Handoop框架,比如Mahout(直译为象兵),Dryad(直译为森林女神)。流式处理的工具有Storm,S4等。交互式分析工具有谷歌的Dremel(直译为马达),和Apache的Drill(直译为钻头)。文章最后会展开每一个工具进行一些认知性解释,以及对比,这部分对刚入门的同学了解大数据处理的基本框架十分有用。
“Apache Hadoop and map/reduce
Apache Hadoop is one of the most well-established software platforms that support data-intensive distributed applications.It implements the computational paradigm named Map/Reduce. Apache Hadoop (see Fig. 6) platform consists of the Hadoop kernel, Map/Reduce and Hadoop distributed file system (HDFS), as well as a number of related projects, including Apache Hive, Apache HBase, and so on.
Map/Reduce [43], which is a programming model and an execution for processing and generating large volume of data sets,was pioneered by Google, and developed by Yahoo! and other web companies. Map/Reduce is based on the divide and conquer method, and works by recursively breaking down a complex problem into many sub-problems, until these sub-problems is scalable for solving directly. After that, these sub-problems are assigned to a cluster of working notes, and solved in separate and parallel ways. Finally, the solutions to the sub-problems are then combined to give a solution to the original problem. The divide and conquer method is implemented by two steps: Map step and Reduce step. In terms of Hadoop cluster, there are two kinds of nodes in Hadoop infrastructure. They are master nodes and worker nodes. The master node takes the input, divides it into smaller sub-problems, and distributes them to worker nodes in Map step. Afterwards, the master node collects the answers to all the sub-problems and combines them in some way to form the output in Reduce step.”

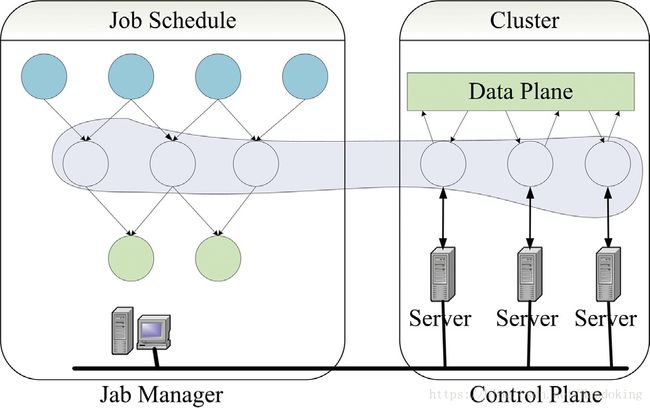
Dryad
“Dryad [75] is another popular programming models for implementing parallel and distributed programs that can scale up capability of processing from a very small cluster to a large cluster. It bases on dataflow graph processing [101]. The infrastructure for running Dryad consists of a cluster of computing nodes, and a programmer use the resources of a computer cluster to running their programs in a distributed way.”
“Dryad provides a large number of functionality, including generating the job graph, scheduling the processes on the available machines, handling transient failures in the cluster, collecting performance metrics, visualizing the job, invoking userdefined policies and dynamically updating the job graph in response to these policy decisions, without awareness of the semantics of the vertices [101]. Fig. 9 schematically shows the implementation schema of Dryad. There is a centralized job manager to supervise every Dryad job. It uses a small set of cluster services to control the execution of the vertices on the cluster.”
“ Apache mahout
The Apache Mahout [74] aims to provide scalable and commercial machine learning techniques for large-scale and intelligent data analysis applications. Many renowned big companies, such as Google, Amazon, Yahoo!, IBM, Twitter and Facebook,have implemented scalable machine learning algorithms in their projects. Many of their projects involve with Big Data problems and Apache Mahout provides a tool to alleviate the big challenges.Mahout’s core algorithms, including clustering, classification, pattern mining, regression, dimension reduction, evolutionary algorithms and batch based collaborative filtering, run on top of Hadoop platform via the Map/reduce framework [46,47].These algorithms in the libraries have been well-designed and optimized to have good performance and capabilities. A number of non-distributed algorithms are also contained. The goal of Mahout is to build a vibrant, responsive, diverse community to facilitate discussions not only on the project itself but also on potential use cases. The business users need to purchase Apache software license for Mahout. More detailed content can be found on the web site: http://mahout.apache.org/.”
“Storm
A Storm cluster consists of two kinds of working nodes. As illustrated in Fig. 11, they are only one master node and several worker nodes. The master node and worker nodes implement two kinds of daemons: Nimbus and Supervisor respectively.The two daemons have similar functions with according JobTracker and TaskTracker in Map/Reduce framework. Nimbus is in charge of distributing code across the Storm cluster, scheduling works assigning tasks to worker nodes, monitoring the whole system. If there is a failure in the cluster, the Nimbus will detect it and re-execute the corresponding task. The supervisor complies with tasks assigned by Nimbus, and starts or stops worker processes as necessary based on the instructions of Nimbus. The whole computational topology is partitioned and distributed to a number of worker processes, each worker
process implements a part of the topology. How can Nimbus and the Supervisors work swimmingly and complete the job fast? Another kind of daemon called Zookeeper play an important role to coordinate the system. It records all states of the Nimbus and Supervisors on local disk.”

论文之后的部分我粗略的看了看,设计大数据系统的遵循的原则以及新技术的简单罗列介绍,展望等。就不贴了。其实英文了一些专业名次还是需要注意的,比如分治法 the divide and conquer method等。
总之这篇综述是入门级的,对新入门同学有一定的帮助,希望大家觉得有用。