Spark运行机制与原理详解
先上图(自己画的有点丑)
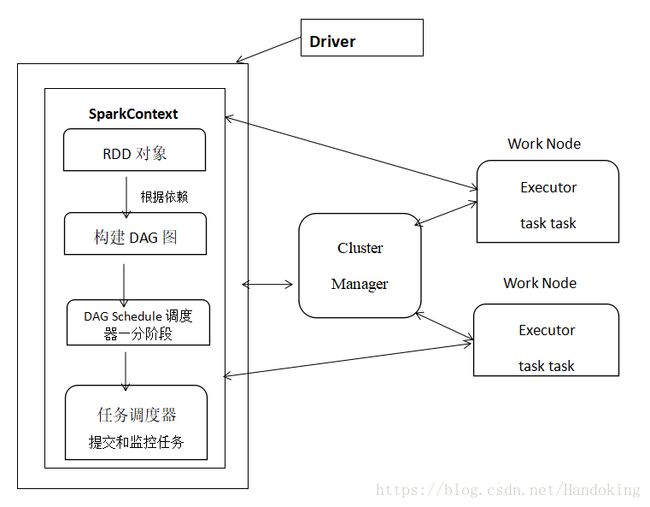
这个就是Spark运行的基本流程图。
或者看这个图

可以看出Spark运行经过以下几个阶段:
1.用户编写好SparkContext,新创建的SparkContext连接资源管理器cluster manager,其实Spark的还有其他优秀的资源管理器可以用,比如Standalone,Apache Mesos,YARN等。资源管理器根据用户提交SparkContext时的设置,分配CPU和内存等信息,也包括任务分配以及任务监控等,这些是SparkContext向资源管理器申请的。
2.资源管理器收到用户应用提交,为应用启动执行任务的进程executor。可以看到系统可以有很多工作节点WorkNode,executor为某工作节点的一个进程。executor通过心跳向资源管理器汇报运行情况,也就是实现任务调度与监控。
3.具体是怎么执行任务的?SparkContext是用户编写创建的,里面有环境配置信息以及应用程序。SparkContext内部是这样的:结合RDD对象和依赖关系创建出有向无环图——DAG图(我理解为拓扑结构),RDD是一种内存共享模型,全称为弹性分布式数据集,可以这么理解RDD从之前的RDD中衍生出来并包含了依赖信息(就是和之前的数据有啥不一样),这样避免了数据丢失时进行检查点操作(就是=一步一步查),它只需要找到父RDD就能很好的恢复,粗略的想象成C++的继承派生会好理解一点。创建成DAG图后调用DAG Scheduler调度器将DAG分为几个阶段,阶段就是任务集,然后交给任务调度器来处理,任务调度器TaskScheduler把任务task发送给executor,SparkContext将应用程序也发给executor来执行。任务控制点Driver会不断的调用task给executor来执行,直到完成或者超过运行次数。
**梳理一下:
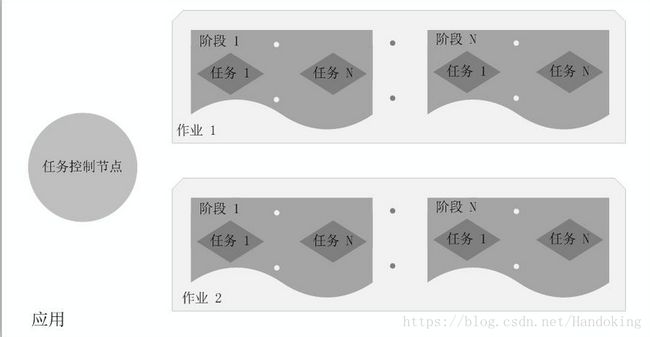
从构成关系看,一个用户应用由一个任务控点Driver和几个作业job构成,作业由几个阶段stage构成,一个阶段由几个任务task构成,多个任务并发(多线程处理)开销更低效率更高。
从任务执行的角度看,控制点Driver向资源管理器申请资源,资源管理器启动executor,配置好环境,executor向控制点申请任务,task和应用程序发送给executor执行,迭代调用到任务完成。**
下图能帮助理解构成关系
**至于RDD,调度器,资源管理器的机制下一篇博文会进行简单的总结**