《ElasticStack从入门到实践》学习笔记5
五、ElasticSearch的分布式特性
1、分布式介绍
1)ES支持集群模式,即一个分布式系统。其好处主要有以下2个:
A、可增大系统容量。比如:内存、磁盘的增加使得ES能够支持PB级别的数据;
B、提高了系统可用性。即使一部分节点停止服务,集群依然可以正常对外服务。
2)ES集群由多个ES实例构成。
不同集群通过集群名字来区分,通过配置文件elasticsearch.yml中的cluster.name可以修改,默认为elasticsearch。
每个ES实例的本质,其实是一个JVM进程,且有自己的名字,通过配置文件中的node.name可以修改。
3)新增一个插件cerebro
下载地址:https://github.com/lmenezes/cerebro/releases 此处选择0.7.2版本。
解压并启动即可:
#cerebro的安装与启动
tar -zxvf cerebro-0.7.2 -C /opt
cd /opt/cerebro-0.7.2
bin/cerebrocerebro默认监听9000端口:
![]()
通过网页访问本地9000端口,进入cerebro登录界面:

输入ElasticSearch的http地址,并连接,可以进入cerebro客户端界面,插件界面自行摸索即可,和其他的插件类似,不过有自己独特的功能,包含:
A、Overview。集群的基本情况,节点的基本情况,shards分布情况等,支持过滤索引和节点;
A、nodes。节点详细状态,load、process cpu%、heap useage%等;
A、rest。类似于Kibana的DevTools,开发者工具;
D、more。包含更多功能,如:create index(可以直接指定分片和副本数),clustering settings修改集群配置等。
2、构建ES集群
1)启动一个节点:
#ES启动单节点,配置集群名称,节点名称,文件路径
bin/elasticsearch -Epath.data=node1 -Ecluster.name=my_cluster -Enode.name=node1 -d每个集群包含cluster state,主要记录一下信息:
节点信息:如节点名称、连接地址等
索引信息:如索引名称、配置等
2)几个节点的名称:
A、主节点master:可修改cluster state的节点。一个集群仅一个。
cluster state存储于每个节点上,master维护最新版本并向其他从节点同步。
B、选举节点master-eligible:可以参与选举master的节点。
配置为:node.master:true。默认所有节点都可以参与选举。
C、协调节点cordinating:处理请求的节点。是所有节点的默认角色,且不能取消。
路由请求到正确的节点处理,如:创建索引的请求到master节点。
D、从节点data:存储数据的节点,默认所有节点都是data类型。
配置为:node.data:true。
3)如何在本地启动一个集群:
当一个集群中只有一个节点,意味着这个节点宕机之后,整个集群都停止对外服务功能,所以,为了解决这个办法,可以在本地启动多个节点创建一个本地化集群:
#创建一个本地化集群my_cluster
bin/elasticsearch -Epath.data=node1 -Ecluster.name=my_cluster -Enode.name=node1 -d
bin/elasticsearch -Ehttp.port=8200 -Epath.data=node2 -Ecluster.name=my_cluster -Enode.name=node2 -d
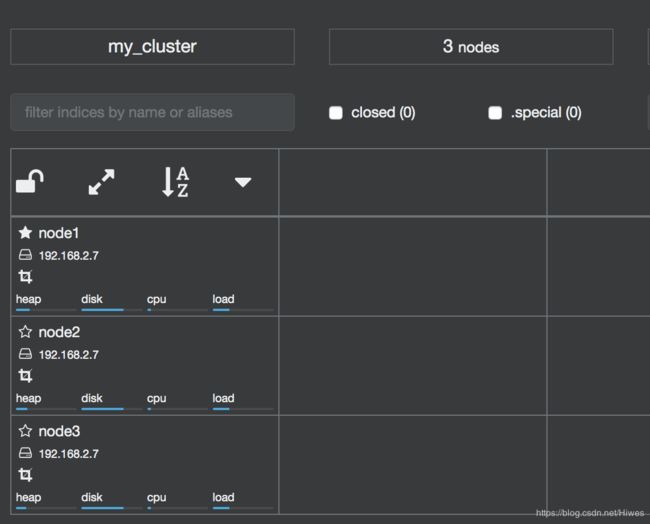
bin/elasticsearch -Ehttp.port=7200 -Epath.data=node3 -Ecluster.name=my_cluster -Enode.name=node3 -d此时可以通过cerebro插件可以看到,集群mu_cluster中存在三个节点,分别为:node1、node2、node3:
3、副本和分片
1)提高系统可用性
为了提高系统的可用性,从两个角度进行考虑:
A、服务可用性:在2个/多个节点的情况下,允许1个/一部分节点停止服务,整个集群依然可以对外提供服务;
B、 数据可用性:引入副本(replication)解决1个/一部分节点停止,节点上数据也同时丢失的情况。此时每个节点都有完备数据。
2)增大系统容量
先思考一个问题:如何将数据分布到所有节点?
答案是:引入分片(shard)。
A、什么是分片?
分片是ES能支持PB级别数据的基石。
a、分片存储部分数据,可以分布于任意节点;
b、分片数在索引创建时指定,且后续不能更改,默认为5个;
c、有主分片和副本分片之分,以实现数据的高可用;
d、副本分片由主分片同步数据,可以有多个,从而提高数据吞吐量。
B、如何设置分片数和副本数?
a、通过在DevTools在创建索引时指定:
#设置分片数和副本数
PUT my_index
{
"settings":{
"number_of_shards":3, #设置分片数为3
"number_of_replicas":1 #设置副本数为1
}
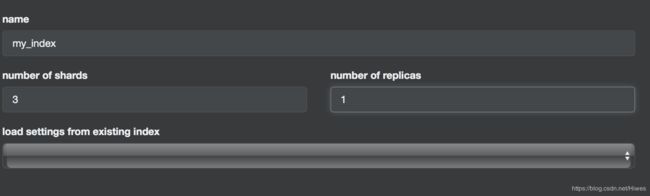
}b、使用cerebro插件的more下create index时同时指定:
C、两个很有意义的问题:
假设现在有3个节点,每个几点上有一个主分片和一个副本分片,那么:
a、此时增加新的节点,能否提高索引的数据容量?
b、此时增加新的副本,能否提高索引读取时的吞吐量?
答案是:不行。
原因:a)三个节点上分布了同一个索引的三个主分片和三个副本分片,已经将所有的数据存到了这三个节点,如果此时增加新的节点,却没有数据给它们利用,造成了资源浪费,且不能提高索引的数据容量;b)新增的副本数,也会增加到这三个节点上,利用的还是同样的资源,所以在三个同样的节点上读取索引数据,吞吐量也不会提高。
那么,在这种情况下,如何才能提高这个索引的吞吐量呢?
答案是:既增加新的节点,又增加新的副本,这样把新的副本放在新的节点上,进行索引数据读取的时候,并且读取,就会提升索引数据读取的吞吐量。
4、ES集群健康状态
ES的健康状态分为三种:
1)Greed,绿色。表示所有主分片和副本分片都正常分配;
2)Yellow,黄色。表示所有主分片都正常分配,但有副本分片未分配;
3)Red,红色。表示有主分片未分配。
集群的状态可以通过api或者插件查看,下面是使用api查看集群状态的命令:
#使用api,查看集群的状态
GET _cluster/health此时,会返回集群名称,集群状态,节点数,活跃分片数等信息。
如果此时磁盘空间不够,name在创建新的索引的时候,主副分片都不会再分配,此时的集群状态会直接飙红,但此时依然可以访问集群和索引,也可以正常进行搜索。
所以:ES的集群状态为红色,不一定就不能正常服务。
5、故障转移 Failover
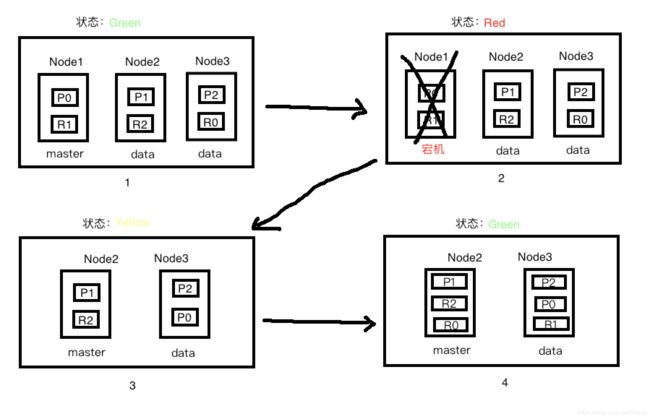
1)什么是故障转移?
在一个多节点集群中的master节点突然宕机,此时集群缺少主节点,剩余的节点组成新的集群,并将幸存副本分片转为主分片,同时在剩余节点生成副本分片,并依然对外进行正常服务的情况,称为故障转移。
2)如何进行故障转移?
当其余节点发现定时ping主节点master无响应的时候,集群状态转为Red。此时会发起master选举。称为master的新主节点发现有主分片没有进行分配,会将继续工作的节点上的副本分片升级为主分片,此时集群状态转为Yellow。之后,主节点会为对应节点生成未分配的副本分片,此时集群状态转为Green。整个故障转移过程结束。
6、文档分布式存储
Document最终存储到分片上,那么文档的数据是如何选择要存储的分片的呢?
此时,就需要文档到分片的映射算法。
目的:是文档均匀分布到所有分片上,以充分利用资源。之所以不用随机和轮询round-robin算法的原因是:需要维护文档到分片的映射关系,那么在PB级别的数据量的时候,这是一个成本非常大的工程。
所以:直接根据文档值实时计算对应的分片即可。分片的计算公式:
shard = hash(routing)%number_of_primary_shardshash保证数据均匀分布在分片中,routing作为关键参数,默认为文档ID,number_of_primary_shards为主分片数。
这也是为什么,主分片数一旦设定,不能更改的原因————为了保证文档对应的分片不会发生改变。
接下来介绍文档创建和读取的流程,以一个集群三个节点为例:
1)文档创建的流程
A、Client向node3发送创建文档请求;
B、node3通过routing计算该文档存储在shard1上,查询cluster state后,确认主shard1在node2上,然后转发请求到node2;
C、node2上的主shard1接收并执行创建文档的请求后,将同样的请求转发到副shard1,查询cluster state后,确认副shard1在node1,向node1发送请求;
D、node1上的副shard1接收并执行创建文档的请求后, 通知主shard1结果;
E、node2上的主shard1接收到副shard1创建文档成功的结果,通知node3创建成功;
F、node3返回结果给Client。
2)文档读取的流程
A、Client向node3发送读取文档doc1的请求;
B、node3通过routing计算该doc1在shard1上,查询cluster state后,确认主shard1和副shard1的位置,然后以轮询的机制获取一个shard(比如这次是主shard1,下次就是副shard1);
C、本次是在node2上的主shard1接收到读取文档的请求,执行并返回结果给node3;
D、node3返回结果给Client。
3)文档批量创建的流程
A、Client向node3发送批量创建文档请求(bulk);
B、node3通过routing计算文档对应的所有shard,然后按主shard分配对应执行的操作,同时发送请求到设计的主shard;
C、每个主shard接收并执行请求后,发送同样的请求到副shard;
D、每个副shard接收并执行请求后,返回结果到主shard,再由主shard返回给 node3;
E、node3整合所有结果,并返回给Client。
4)文档批量读取的流程
A、Client向node3发送批量读取文档请求(bulk);
B、node3通过routing计算文档对应的所有shard,再以轮询的机制,按shard构建mget请求,通过发送给设计的shard;
C、由shard返回文档结果;
D、node3整合后返回结果到Client。
7、脑裂问题
1)什么是脑裂问题?
在分布式系统中有一个经典的网络问题。
当一个集群在运行时,作为master节点的node1的网络突然出现问题,无法和其他节点通信,出现网络隔离情况。那么node1自己会组成一个单节点集群,并更新cluster state;同时作为data节点的node2和node3因为无法和node1通信,则通过选举产生了一个新的master节点node2,也更新了cluster state。那么当node1的网络通信恢复之后,集群无法选择正确的master。
2)如何解决脑裂问题?
解决方案也很简单:仅在可选举的master-eligible节点数 >= quorum的时候才进行master选举。
quorum(至少为2)=master-eligible数量/2 + 1。
通过discovery.zen.minimum_master_nodes为quorum即可避免脑裂。
8、Shards分片详解
1)倒排索引一旦生成,不能更改。
A、优点:
a、不用考虑并发写文件的问题,杜绝了锁机制带来的性能问题;
b、文件不在更改,则可以利用文件系统缓存,只需载入一次,只要内存足够,直接从内存中读取该文件,性能高;
c、利于生成缓存数据(且不需更改);
d、利于对文件进行压缩存储,节省磁盘和内存存储空间。
B、缺点:
在写入新的文档时,必须重构倒排索引文件,然后替换掉老倒排索引文件后,新文档才能被检索到,导致实时性差。
2)解决文档搜索的实时性问题的方案:
新文档直接生成新待排索引文件,查询时同时查询所有倒排索引文件,然后做结果的汇总即可,从而提升了实时性。
3)Segment
Lucene就采用了上述方案,构建的单个倒排索引称为Segment,多个Segment合在一起称为Index(Lucene中的Index)。在ES中的一个shard分片,对应一个Lucene中的Index。且Lucene有一个专门记录所有Segment信息的文件叫做Commit Point。
Segment写入磁盘的过程依然很耗时,可以借助文件系统缓存的特性。【先将Segment在内存中创建并开放查询,来进一步提升实时性】,这个过程在ES中被称为:refresh。
在refresh之前,文档会先存储到一个缓冲队列buffer中,refresh发生时,将buffer中的所有文档清空,并生成Segment。
ES默认每1s执行一次refresh操作,因此实时性提升到了1s。这也是ES被称为近实时的原因(Near Real Time)。
4)translog文件
那么,如果在节点写入磁盘之前就发生了宕机,这时候内存中的segment丢失,该怎么解决呢?
此时,引入了translog机制:当文档写入buffer时,同时会将该操作写入到translog中,这个文件会即时将数据写入磁盘,在6.0版本之后默认每个要求都必须落盘,这个操作叫做fsync操作。这个时间也是可以通过配置:index.translog.*进行修改的。比如每五秒进行一次fdync操作,那么风险就是丢失这5s内的数据。
5)文档搜索实时性————flush(十分重要)
flush的功能,就是:将内存中的Segment写入磁盘,主要做如下工作:
A、将translog写入磁盘;
B、将index bufffer清空,其中的文档生成一个新的Segment,相当于触发一次refresh;
C、更新Commit Point文件并写入磁盘;
D、执行fsync落盘操作,将内存中的Segment写入磁盘;
E、删除旧的translog文件。
6)refresh与flush的发生时机
A、refresh:发生时机主要有以下几种情况:
a、间隔时间达到。
通过index.settings.refresh_interval设置,默认为1s。
b、index.buffer占满时。
通过indices.memory.index_buffer_size设置,默认JVM heap的10%,且所有shard共享。
c、flush发生时。会触发一次refresh。
B、flush:发生时机主要有以下几种情况:
a、间隔时间达到。
5.x版本之前,通过index.translog.flush_threshold_period设置,默认30min。
5.x版本之后,ES强制每30min执行一次flush,不能再进行更改。
b、translog占满时。
通过index.translog.flush_threshold_size设置,默认512m。且每个Index有自己的translog。
7)删除和更新文档:
A、删除:
Segment一旦生成,就不能更改,删除的时候,Lucene专门维护一个.del文件,记录所有已删除的文档。
.del 文件 上记录的是文档在Lucene中的ID,在查询结果返回之前,会过滤掉.del 文件 中的所有文档。
B、更新:
先删除老文档,再创建新文档,两个文档的ID在Lucene中的ID不同,但是在ElasticSearch中ID相同。
8)Segment Merging(合并)
A、随着Segment的增多,由于每次查询的Segment数量也增多,导致查询速度变慢;
B、ES会定时在后台进行Segment merge的操作,减少Segment数量;
C、通过force_merge api可以手动强制做Segment的合并操作。