ForkJoinPool入门篇
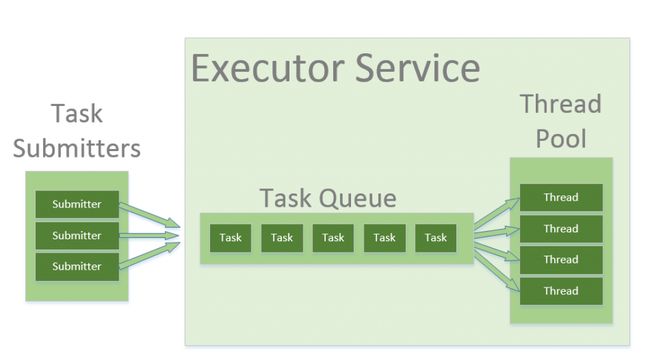
《线程池ThreadPoolExecutor详解》和《任务调度线程池ScheduledThreadPoolExecutor》两篇文章已经将ThreadPoolExecutor和ScheduledThreadPoolExecutor两个核心线程池详细介绍过了,它们整体的工作结构如下图所示。
这篇文章将介绍最后一个线程池——Java7中最引人瞩目的ForkJoinPool线程池。
1. 为什么使用ForkJoinPool
ThreadPoolExecutor中每个任务都是由单个线程独立处理的,如果出现一个非常耗时的大任务(比如大数组排序),就可能出现线程池中只有一个线程在处理这个大任务,而其他线程却空闲着,这会导致CPU负载不均衡:空闲的处理器无法帮助工作繁忙的处理器。
ForkJoinPool就是用来解决这种问题的:将一个大任务拆分成多个小任务后,使用fork可以将小任务分发给其他线程同时处理,使用join可以将多个线程处理的结果进行汇总;这实际上就是分治思想的并行版本。
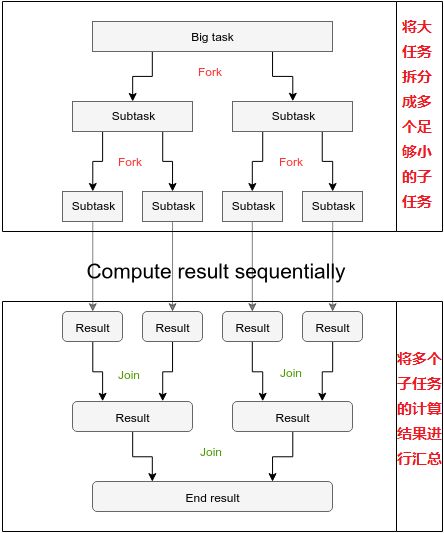
2. ForkJoinPool的基本原理
ForkJoinPool 类是Fork/Join 框架的核心,和ThreadPoolExecutor一样它也是ExecutorService接口的实现类。
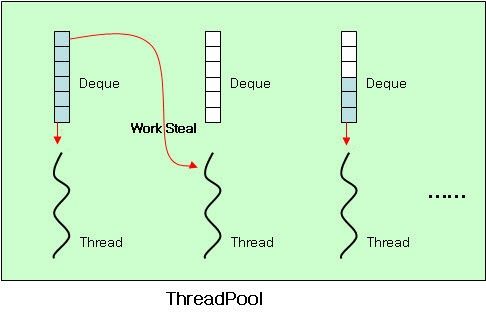
虽说了ForkJoinPool会把大任务拆分成多个子任务,但是ForkJoinPool并不会为每个子任务创建单独的线程。相反,池中每个线程都有自己的双端队列(Deque)用于存储任务。这个双端队列对于工作窃取算法至关重要。
public class ForkJoinWorkerThread extends Thread {
final ForkJoinPool pool; // 工作线程所在的线程池
final ForkJoinPool.WorkQueue workQueue; // 线程的工作队列(这个双端队列是work-stealing机制的核心)
...
}
ForkJoinPool的两大核心就是分而治之(Divide and conquer)和工作窃取(Work Stealing)算法
2.1 工作窃取算法
Fork/Join框架中使用的work stealing灵感来源于Cilk(开发Cilk的公司被Intel收购,原项目后来被升级为Clik Plus)。
Intel公司除了Clik Plus还有一个TBB(Threading Building Blocks)也是使用work stealing算法实现。
Work Stealing算法是Fork/Join框架的核心思想:
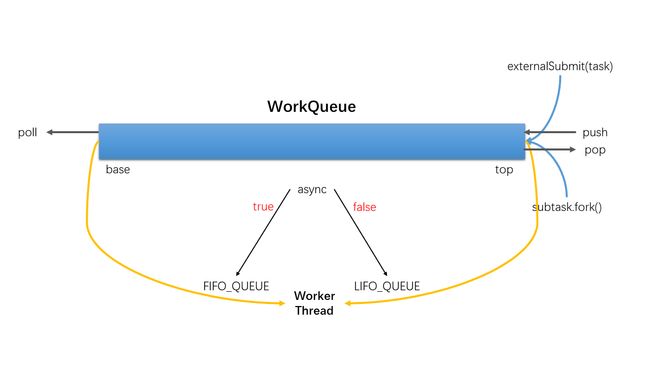
- 每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列。
- 队列支持三个功能push、pop、poll
- push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
- 划分的子任务调用fork时,都会被push到自己的队列中。
- 默认情况下,工作线程从自己的双端队列获出任务并执行。
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务。
3. 创建ForkJoinPool对象
1、使用Executors工具类
Java8在Executors工具类中新增了两个工厂方法:
// parallelism定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为JVM可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
2、使用ForkJoinPool内部已经初始化好的commonPool
public static ForkJoinPool commonPool();
// 类静态代码块中会调用makeCommonPool方法初始化一个commonPool
3、使用构造器创建
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE, // 队列工作模式
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
前两个构造器最终都是调用第三个构造器,下面解释一下第四个构造器中各个参数的含义:
-
parallelism:并行级别,通常默认为JVM可用的处理器个数
Runtime.getRuntime().availableProcessors() -
factory:用于创建ForkJoinPool中使用的线程。
public static interface ForkJoinWorkerThreadFactory { public ForkJoinWorkerThread newThread(ForkJoinPool pool); }ForkJoinPool管理的线程均是扩展自Thread类的ForkJoinWorkerThread类型(里面包含了一个双端队列)。
-
handler:用于处理工作线程未处理的异常,默认为null。
-
asyncMode:用于控制WorkQueue的工作模式
// asyncMode用于控制WorkQueue取任务模式 final ForkJoinTask<?> peek() { ForkJoinTask<?>[] a = array; int m; if (a == null || (m = a.length - 1) < 0) return null; // 如果是FIFO_QUEUE从base取任务,LIFO_QUEUE从top取任务 int i = (config & FIFO_QUEUE) == 0 ? top - 1 : base; int j = ((i & m) << ASHIFT) + ABASE; return (ForkJoinTask<?>)U.getObjectVolatile(a, j); } final void execLocalTasks() { int b = base, m, s; ForkJoinTask<?>[] a = array; if (b - (s = top - 1) <= 0 && a != null && (m = a.length - 1) >= 0) { if ((config & FIFO_QUEUE) == 0) { // 从队列top端取任务执行 } else // 从队列base端取任务执行 pollAndExecAll(); } } final void pollAndExecAll() { // 从队列base端取任务执行 for (ForkJoinTask<?> t; (t = poll()) != null;) t.doExec(); }
Java9中提供的构造参数更复杂了,可以在JSR166 Concurrency论坛看看作者Doug Lea是怎么想的。
4. 提交任务到ForkJoinPool
// 提交没有返回值的任务
public void execute(ForkJoinTask<?> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
}
public void execute(Runnable task) {
if (task == null)
throw new NullPointerException();
ForkJoinTask<?> job;
if (task instanceof ForkJoinTask<?>) // 避免二次包装
job = (ForkJoinTask<?>) task;
else
job = new ForkJoinTask.RunnableExecuteAction(task); // 包装成ForkJoinTask
externalPush(job);
}
// 提交有返回值的任务
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task;
}
public <T> ForkJoinTask<T> submit(Callable<T> task) {
// 包装成ForkJoinTask
ForkJoinTask<T> job = new ForkJoinTask.AdaptedCallable<T>(task);
externalPush(job);
return job;
}
public <T> ForkJoinTask<T> submit(Runnable task, T result) {
// 包装成ForkJoinTask
ForkJoinTask<T> job = new ForkJoinTask.AdaptedRunnable<T>(task, result);
externalPush(job);
return job;
}
public ForkJoinTask<?> submit(Runnable task) {
if (task == null)
throw new NullPointerException();
ForkJoinTask<?> job;
if (task instanceof ForkJoinTask<?>) // 避免二次包装
job = (ForkJoinTask<?>) task;
else
job = new ForkJoinTask.AdaptedRunnableAction(task); // 包装成ForkJoinTask
externalPush(job);
return job;
}
// 同步提交,阻塞等结果
public <T> T invoke(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task.join(); // 等待任务完成
}
可以看到所有的任务最终都会以ForkJoinTask类型提交到线程池中。
5. ForkJoinTask
大多数情况下,我们都是直接提交ForkJoinTask对象到ForkJoinPool中。
因为ForkJoinTask有以下三个核心方法:
-
fork():在任务执行过程中将大任务划分为多个小的子任务,调用子任务的
fork()方法可以将任务放到线程池中异步调度。 -
join():调用子任务的
join()方法等待任务返回的结果。这个方法类似于Thread.join(),区别在于前者不受线程中断机制的影响。如果子任务中有运行时异常,
join()会抛出异常,quietlyJoin()方法不会抛出异常也不会返回结果,需要你调用getException()或getRawResult()自己去处理异常和结果。 -
invoke():在当前线程同步执行该任务。该方法也不受中断机制影响。
如果子任务中有运行时异常,
invoke()会抛出异常,quietlyInvoke()方法不会抛出异常也不会返回结果,需要你调用getException()或getRawResult()自己去处理异常和结果。
ForkJoinTask中
join(),invoke()都不受中断机制影响,内部调用externalAwaitDone()方法实现如果是在ForkJoinTask内部调用
get()方法,本质上和join()方法一样都是调用externalAwaitDone()。但如果是在ForkJoinTask外部调用
get()方法,这时会受线程中断机制影响,因为内部是通过调用externalInterruptibleAwaitDone()方法实现的。public final V get() throws InterruptedException, ExecutionException { int s = (Thread.currentThread() instanceof ForkJoinWorkerThread) ? doJoin() : externalInterruptibleAwaitDone(); ... }
ForkJoinTask由上面三个方法衍生出了几个静态方法:
public static void invokeAll(ForkJoinTask<?> t1, ForkJoinTask<?> t2);
public static void invokeAll(ForkJoinTask<?>... tasks);
public static <T extends ForkJoinTask<?>> Collection<T> invokeAll(Collection<T> tasks);
上面几个方法都是让第一个任务同步执行,其他任务异步执行(注意:其他任务先fork,第一个任务再invoke)。
5.1 任务状态
ForkJoinTask内部维护了四个状态:
/** The run status of this task */
volatile int status; // 默认等于0
static final int DONE_MASK = 0xf0000000; // 小于0表示任务已经执行过,大于0说明任务没执行完
// NORMAL,CANCELLED,EXCEPTIONAL均小于0
static final int NORMAL = 0xf0000000; // must be negative
static final int CANCELLED = 0xc0000000; // must be < NORMAL
static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
static final int SIGNAL = 0x00010000; // must be >= 1 << 16
static final int SMASK = 0x0000ffff; // short bits for tags
ForkJoinTask内部维护了上图中的四个状态,并提供了以下方法查询任务当前的状态:
isCancelled() => CANCELLED
isCompletedAbnormally => status < NORMAL => CANCELLED || EXCEPTIONAL
isCompletedNormally => NORMAL
isDone() => status<0 => NORMAL || CANCELLED || EXCEPTIONAL
6. RecursiveAction与RecursiveTask
通常我们不会直接使用ForkJoinTask,而是使用它的两个抽象子类:
- RecursiveAction:没有返回值的任务
- RecursiveTask:有返回值的任务
6.1 使用RecursiveAction
public class RecursiveActionTest {
static class Sorter extends RecursiveAction {
public static void sort(long[] array) {
ForkJoinPool.commonPool().invoke(new Sorter(array, 0, array.length));
}
private final long[] array;
private final int lo, hi;
private Sorter(long[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
}
private static final int THRESHOLD = 1000;
protected void compute() {
// 数组长度小于1000直接排序
if (hi - lo < THRESHOLD)
Arrays.sort(array, lo, hi);
else {
int mid = (lo + hi) >>> 1;
// 数组长度大于1000,将数组平分为两份
// 由两个子任务进行排序
Sorter left = new Sorter(array, lo, mid);
Sorter right = new Sorter(array, mid, hi);
invokeAll(left, right);
// 排序完成后合并排序结果
merge(lo, mid, hi);
}
}
private void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++) {
if (k == hi || buf[i] < array[k]) {
array[j] = buf[i++];
} else {
array[j] = array[k++];
}
}
}
}
public static void main(String[] args) {
long[] array = new Random().longs(100_0000).toArray();
Sorter.sort(array);
System.out.println(Arrays.toString(array));
}
}
5.2 使用RecursiveTask
public class RecursiveTaskTest {
static class Sum extends RecursiveTask<Long> {
public static long sum(int[] array) {
return ForkJoinPool.commonPool().invoke(new Sum(array, 0, array.length));
}
private final int[] array;
private final int lo, hi;
private Sum(int[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
}
private static final int THRESHOLD = 600;
@Override
protected Long compute() {
if (hi - lo < THRESHOLD) {
return sumSequentially();
} else {
int middle = (lo + hi) >>> 1;
Sum left = new Sum(array, lo, middle);
Sum right = new Sum(array, middle, hi);
right.fork();
long leftAns = left.compute();
long rightAns = right.join();
// 注意subTask2.fork要在subTask1.compute之前
// 因为这里的subTask1.compute实际上是同步计算的
return leftAns + rightAns;
}
}
private long sumSequentially() {
long sum = 0;
for (int i = lo; i < hi; i++) {
sum += array[i];
}
return sum;
}
}
public static void main(String[] args) {
int[] array = IntStream.rangeClosed(1, 100_0000).toArray();
Long sum = Sum.sum(array);
System.out.println(sum);
}
}
上面的两个例子都是将一个大任务划分成两个子任务进行计算,有些时候可能会划分成两个以上的子任务,甚至可能每次生成的子任务数都是动态的(比如使用Fork/Join并行遍历文件目录来查找文件或统计文件夹中所有文件的大小):
public class DirectoryTask extends RecursiveTask {
protected Long compute() {
File[] files = dir.listFiles();
List<RecursiveTask> tasks = new ArrayList<>(files.length);
for (File f : files) {
if (f.isDirectory()) {
tasks.add(new DirectoryTask(f));
} else {
tasks.add(new FileTask(f));
}
}
long sum = 0;
for (RecursiveTask task : invokeAll(tasks)) {
// exception handling omitted
sum += task.get();
}
return sum;
}
}
7. Fork/Join的陷阱与注意事项
使用Fork/Join框架时,需要注意一些陷阱
7.1、避免不必要的fork()
划分成两个子任务后,不要同时调用两个子任务的fork()方法。
表面上看上去两个子任务都fork(),然后join()两次似乎更自然。但事实证明,直接调用compute()效率更高。因为直接调用子任务的compute()方法实际上就是在当前的工作线程进行了计算(线程重用),这比“将子任务提交到工作队列,线程又从工作队列中拿任务”快得多。

当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的
invokeAll方法,因为使用它们能避免不必要的fork()。
7.2、注意fork()、compute()、join()的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意。
right.fork(); // 计算右边的任务
long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算)
long rightAns = right.join(); // 等待右边的结果
return leftAns + rightAns;
如果我们写成:
left.fork(); // 计算完左边的任务
long leftAns = left.join(); // 等待左边的计算结果
long rightAns = right.compute(); // 再计算右边的任务
return leftAns + rightAns;
或者
long rightAns = right.compute(); // 计算完右边的任务
left.fork(); // 再计算左边的任务
long leftAns = left.join(); // 等待左边的计算结果
return leftAns + rightAns;
下面两种实际上都没有并行。
7.3、选择合适的子任务粒度
选择划分子任务的粒度(顺序执行的阈值)很重要,因为使用Fork/Join框架并不一定比顺序执行任务的效率高:如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork()子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗。
官方文档给出的粗略经验是:任务应该执行100~10000个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是“上上策”。
和其他Java代码一样,Fork/Join框架测试时需要“预热”或者说执行几遍才会被JIT(Just-in-time)编译器优化,所以测试性能之前跑几遍程序很重要。
7.4、避免重量级任务划分与结果合并
Fork/Join的很多使用场景都用到数组或者List等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免System.arraycopy这样耗时耗空间的操作,从而最小化任务的处理开销。
8. 异常处理
Java的受检异常机制一直饱受诟病,所以在ForkJoinTask的invoke()、join()方法及其衍生方法中都没有像get()方法那样抛出个ExecutionException的受检异常。
所以你可以在ForkJoinTask中看到内部把受检异常转换成了运行时异常。
static void rethrow(Throwable ex) {
if (ex != null)
ForkJoinTask.<RuntimeException>uncheckedThrow(ex);
}
@SuppressWarnings("unchecked")
static <T extends Throwable> void uncheckedThrow(Throwable t) throws T {
throw (T)t; // rely on vacuous cast
}
关于Java你不知道的10件事中已经指出,JVM实际并不关心这个异常是受检异常还是运行时异常,受检异常这东西完全是给Java编译器用的:用于警告程序员这里有个异常没有处理。
但不可否认的是invoke、join()仍可能会抛出运行时异常,所以ForkJoinTask还提供了两个不提取结果和异常的方法quietlyInvoke()、quietlyJoin(),这两个方法允许你在所有任务完成后对结果和异常进行处理。
使用quitelyInvoke()和quietlyJoin()时可以配合isCompletedAbnormally()和isCompletedNormally()方法使用。
参考链接:
Javadoc文档:https://docs.oracle.com/javase/9/docs/api/java/util/concurrent/ForkJoinPool.html
Fork/Join框架:http://gee.cs.oswego.edu/dl/papers/fj.pdf
初学者的F/J框架导论:https://homes.cs.washington.edu/~djg/teachingMaterials/spac/grossmanSPAC_forkJoinFramework.html
《Java8 In Action》:https://www.manning.com/books/java-8-in-action
OpenMP并行编程简介: http://www.bowdoin.edu/~ltoma/teaching/cs3225-GIS/fall16/Lectures/openmp.html
Cilk Plus与其他并行框架的比较:https://www.cilkplus.org/faq/24
TBB与其他并行框架的比较:https://www.threadingbuildingblocks.org/compare
F/J框架与Parallel Stream vs. ExecutorService:https://blog.takipi.com/forkjoin-framework-vs-parallel-streams-vs-executorservice-the-ultimate-benchmark/
Fork/Join灾难:http://www.coopsoft.com/ar/CalamityArticle.html
使用Fork/Join框架的范例与反例:https://rmod.inria.fr/archives/papers/DeWa14a-PPPJ14-ForkJoin.pdf
Fork/Join与MapReduce:http://www.macs.hw.ac.uk/cs/techreps/docs/files/HW-MACS-TR-0096.pdf
任务并行Wikipedia:https://en.wikipedia.org/wiki/Task_parallelism
http://www.oracle.com/technetwork/articles/java/fork-join-422606.html
http://ifeve.com/java7-concurrency-cookbook-4/
http://jsr166-concurrency.10961.n7.nabble.com/CountedCompleters-td5213.html