SSD: Single Shot MultiBox Detector 训练KITTI数据集(2)
前言
博主在上篇中花了很大篇幅讲解如何一步步把KITTI原始数据做成了SSD可以训练的格式,接下来就可以使用相关caffe代码实现SSD的训练了。
下载VGG预训练模型
将 SSD 用于自己的检测任务,是需要 Fine-tuning a pretrained network,看过论文的朋友可能都知道,论文中的SSD框架是是由VGG网络为基底(base)的。除此之外,作者也提供了另外两种结构的网络:ZF-SSD和Resnet-SSD,可以在caffe/examples/ssd 文件夹中查看相应的python训练代码。
初次训练,还是用VGG网络吧,下载该预训练模型,将其放到/home/mx/caffe/models/VGGNet文件夹之下。
修改训练代码
这里先说下电脑硬件配置,这决定了一些训练参数的设定。博主使用的主机CPU为Intel i7 6700,GPU为TITAN X,运行内存16GB,搭载Ubuntu16.04系统。
一般的caffe训练都是使用train.prototxt和solver.prototxt文件,有同学可能想问了,为什么SSD项目下找不到这些文件呢?原因是SSD的模型很大,train.prototxt就有1000多行,直接修改参数的工作量太大,而且train.prototxt一旦改动,test.prototxt和solver.prototxt也要跟着改动。因此,作者使用了一个很有效的方法,利用python脚本,自动生成这些文件。初次训练,博主选择了ssd_pascal.py 脚本来训练SSD_300x300,那么将ssd_pascal.py复制一份,重命名为ssd_pascal_kitti.py,然后修改这个ython文件。
ssd_pascal.py脚本也有500多行,博主也不可能全部贴出来,这里就贴出可以修改的部分,作为一个参照。
PS.根据博友反馈,还是提供修改过的的训练脚本 ssd_pascal_kitti.py,以供参考。
自定义路径和常用参数
train_data = "examples/VOC0712/VOC0712_trainval_lmdb" # 训练数据路径,修改前
train_data = "examples/KITTI/KITTI_trainval_lmdb" # 修改后
------
test_data = "examples/VOC0712/VOC0712_test_lmdb" # 测试数据路径
test_data = "examples/KITTI/KITTI_test_lmdb"
------
model_name = "VGG_VOC0712_{}".format(job_name) # 模型名字
model_name = "KITTI_{}".format(job_name)
------
save_dir = "models/VGGNet/VOC0712/{}".format(job_name) # 模型保存路径
save_dir = "models/VGGNet/KITTI/{}".format(job_name)
------
snapshot_dir = "models/VGGNet/VOC0712/{}".format(job_name) # snapshot快照保存路径
snapshot_dir = "models/VGGNet/KITTI/{}".format(job_name)
------
job_dir = "jobs/VGGNet/VOC0712/{}".format(job_name) # job保存路径
job_dir = "jobs/VGGNet/KITTI/{}".format(job_name)
------
output_result_dir = "{}/data/VOCdevkit/results/VOC2007/{}/Main".format(os.environ['HOME'], job_name) # 测试结果txt保存路径
output_result_dir = "{}/data/KITTIdevkit/results/KITTI/{}/Main".format(os.environ['HOME'], job_name)
-------
name_size_file = "data/VOC0712/test_name_size.txt" # test_name_size.txt文件路径
name_size_file = "data/KITTI/test_name_size.txt"
-------
label_map_file = "data/VOC0712/labelmap_voc.prototxt" # label文件路径
label_map_file = "data/KITTI/labelmap_kitti.prototxt"
------
num_classes = 21 # 总类别数
num_classes = 4
------
gpus = "0,1,2,3" # 使用哪块GPU
gpus = "0" # 只有1块GPU
------
batch_size = 32 # 一次处理的图片数
batch_size = 自定义 # TITAN X刚好可以达到32,请根据显存大小调整
------
num_test_image = 4952 # 测试图片数量
num_test_image = 自定义 # 这个数量应该和test_name_size.txt保持一致
------
run_soon = True # 生成文件后自动开始训练
run_soon = False # 手动挡自定义训练参数
SSD的训练参数比较多,具体含义之前也了解过。但是初次试验,不太清楚该怎么调,所以决定基本先不改动其他参数(等训练一次后根据结果再调整,反复训练),只对初始学习率做调整。事实证明,对于KITTI数据集,初始学习率0.001过大,会导致网络不收敛,此处应调整为0.0001,具体如下:
# If true, use batch norm for all newly added layers.
# Currently only the non batch norm version has been tested.
use_batchnorm = False
lr_mult = 1
# Use different initial learning rate.
if use_batchnorm:
base_lr = 0.0004
else:
# A learning rate for batch_size = 1, num_gpus = 1.
base_lr = 0.00004
......
if normalization_mode == P.Loss.NONE:
base_lr /= batch_size_per_device
elif normalization_mode == P.Loss.VALID:
base_lr *= 25. / loc_weight
elif normalization_mode == P.Loss.FULL:
# Roughly there are 2000 prior bboxes per image.
# TODO(weiliu89): Estimate the exact # of priors.
base_lr *= 2000.
# 从以上代码可以看出,训练脚本没有使用batchnorm,未修改前,初始学习率 = base_lr * 25 / loc_weight=0.001
# 将base_lr变量改为原来十分之一,也就是0.00004->0.000004,就能把学习率调整为0.0001PS.学习率0.0001确实偏小,可以适当调大一些,我自己的试验表明,0.0005~0.0007都是可选的参数,高于0.0008就会发散。
训练模型
修改完脚本参数后,运行该脚本程序。
$ cd caffe/
$ python examples/ssd/ssd_pascal_kitti.py然后模型就训练起来了,可能会遇到“out of memory”的问题,那是batch_size设的太高,导致显存不足,此时调低batch_size再重新运行即可解决。
本次训练迭代120000次,博主估算训练时间大约50多小时,由于该主机还有别的任务,也只能断断续续进行训练(直接导致训练日志不完整,没法画accuracy和loss曲线)。感觉直接套用人家的训练参数,loss收敛比较慢。
终于训练完成,截图留念。
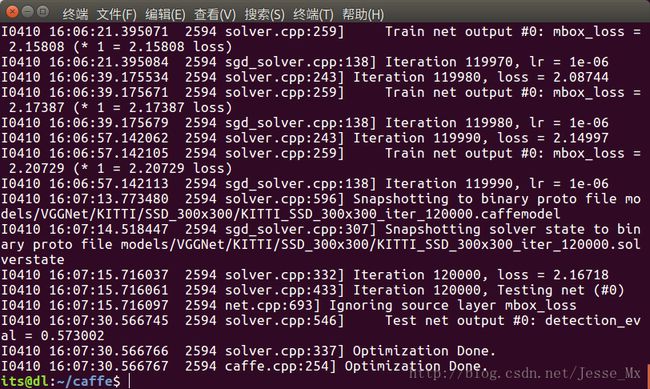
测试模型
从训练结束的截图来看,本次训练结果是不太理想的,经过120000次迭代后,loss还在2左右,收敛性比较差;测试准确率也仅有57.3%,和论文中VOC训练结果差得蛮远。虽然模型有点渣,但还是拿出来用用,看到底是个什么程度。
这里使用ssd_detect.py来检测单张图片,部分检测效果如下:
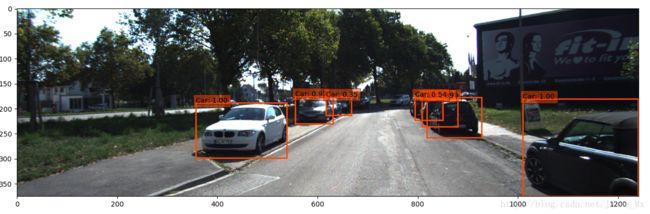

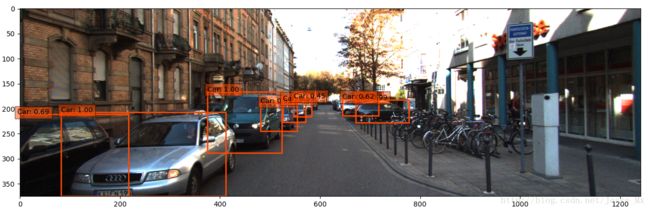
由图可知,汽车和行人训练的比较充分,检测结果还差强人意;自行车不知道是标注样本太少还是训练的不好,基本很难检测出来。
总结和思考
本次训练,过程是跑通了,但是结果并不是很理想,总结下可能的原因和改进方向:
- 训练参数上,直接照搬肯定不行,后面需要有选择性的调参;
- VOC图片大小多为500x375,而KITTI图片大小为1242x375,不仅分辨率上去了,长宽比也达到了3:1,仍然使用SSD_300x300可能不太合适,之后将试着训练SSD_512x512或者其他大小的模型,准确率应该能上升,但是运行时间将变长;
- 换底,看看ZF-SSD和Resnet-SSD的表现如何,一方面是准确率,另一方面是运行时间;
- 为了更高的准确率,感觉训练图片仍显不够(尤其在自行车这一类上),可以试着补充类似的数据集。
更新:针对精度低的问题,博主阅读一些论文,发现数据集失衡应该是主要原因,确切来说,我制作的KITTI中car占比太大,而其他类别太少,mAP被拉低了,如果平衡数据集,应该能有所提升。