Lucene6.6的介绍和使用
一,什么是Lucene
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的 架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。说白了就是一个做索引的开源框架。
二,如何使用Lucene
我使用的是lucene6.6的版本,以后可能有新版本的出现,关于lucene6.6和4.x版本是不同的,使用时需要注意,下面我就来说下lucene的使用方法以及不同
lucene6.6要求jdk必须是1.8的版本,不然会报错,关于错误原因。我的博客有,其实你换下jdk就行了,下面我就直接贴个代码,然后说下不同的地方,以及使用要注 意的地方
========================================================分割线====================================================================
/**
* 使用IndexWrite向索引库中写入数据
* Ctrl+T显示某个类的继承结构
* @throws IOException
*/
@Test
public void CreateIndex() throws IOException{
//索引存放的位置,设置在当前目录中
Directory directory = FSDirectory.open(Paths.get("indexDir/"));
//添加Lucene的版本
Version version = Version.LUCENE_6_6_0;
//创建lucene的分词器,主要用于进行分词,比如识别你好,中国,甚至一些以前没有,但现在出先的词
Analyzer analyzer = new StandardAnalyzer();
//创建索引写入配置
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
//创建索引写入对象
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//创建Document对象,存储索引
Document doc = new Document();
//创建字段用于存储数据
/**
* @param:name:字段名
* @param:value:字段值
* @param:store:是否存储
*/
int iD = 6;
Field id = new IntPoint("id",iD);
Field storeField = new StoredField("id", iD);
Field title = new StringField("title","ImportNew - 专注Java & Android 技术分享",Store.YES);
Field content = new TextField("content","ImportNew 是一个专注于 Java & Android 技术分享的博客,为Java 和 Android开发者提供有价值的内容。包括:Android开发与快讯、Java Web开发和其他的Java技术相关的",Store.YES);
//将字段加入到doc中
doc.add(id);
doc.add(title);
doc.add(content);
doc.add(storeField);
//将doc对象保存到索引库中
indexWriter.addDocument(doc);
//关闭流
indexWriter.close();
}
/**
* @throws IOException
*
*/
@Test
public void SelectIndex() throws IOException{
//索引存放的位置
Directory directory = FSDirectory.open(Paths.get("indexDir/"));
//创建索引的读取器
IndexReader indexReader = DirectoryReader.open(directory);
//创建一个索引的查找器,来检索索引库
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//这是一个条件查询的api,用于添加条件
Term term = new Term("title","ImportNew - 专注Java & Android 技术分享");
TermQuery termQuery = new TermQuery(term);
//搜索先搜索索引库
//返回符合条件的前100条记录
TopDocs topDocs = indexSearcher.search(termQuery, 100);
//打印查询到的记录数
System.out.println("总记录数:"+topDocs.totalHits);
//得到得分文档数组
ScoreDoc scoreDocs[] = topDocs.scoreDocs;
//遍历数组,返回一个击中
for(ScoreDoc scoreDoc : scoreDocs){
int docID = scoreDoc.doc;
//取得对应的文档对象
Document document = indexSearcher.doc(docID);
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
}
}使用lucene离不开核心的两个核心的api,indexWriter 和 indexSearcher ,上面已经给出了如何创建indexWriter和indexSearcher方法,然后说下不同的lucene6.6和4.4不同的地方,lucene6.6不能在使用new File(Path)的方式来传递路径了,而是使用Path类,但是这个Path是个接口,不能new,你需要使用Paths这个工具类,使用get(uri)方法传入路径,还有lucene6.6不需要,你再传递版本信息,即那个Version.66这个参数不在需要,indexWriter这个api,主要完成向索引库写入数据,删除数据,更新数据
你需要将存入的数据,放入一个叫字段的对象中,但是Int这种数字类型,没有IntField这个api了,取而代之是IntPoint这个api,你需要
把你的数据存入到Intpoint中,才能存入到索引库中,同时IntPoint没有Store.YES这个属性,这个属性表示是否将字段存入索引库中
由于没有该属性,所以我们需要在创建一个字段StoredField,这个字段表示那个数据是否要被存入索引库,创建该字段,将你的数据放进去,在来如果你要实现索引库对你的这个字段进行排序你还要创建一个NumericDocValuesField字段,不然会出现unexpected docvalues type NONE for field 'id'错误,最后需要将这些字段放入一个Document对象中,才能存入索引库,document就像数据库中的一张表,存放多个字段的数据,还有如果你想讲indexWriter变成一个工具类方法,返回indexWriter话,注意,indexWriterConfig,要保证每产生一个indexWriter就要产生一个indexWriterConfig,不然会报indexWriterConfig不能share的错误
接下来说下IndexSearcher,这个Api主要用来做查询的操作,上面的demo说明了如何用一个词条进行查询,还有很多查询方式,下面再说,注意返回的是一个ScoreDocs,表示命中了多少个数据,最后使用docID,查询,返回document,相当于表查询一样,Term相当于查询条件,整个操作像是select * from document where id=?这样的,下面给这个图,解释下索引库的结构
三,索引库的结构
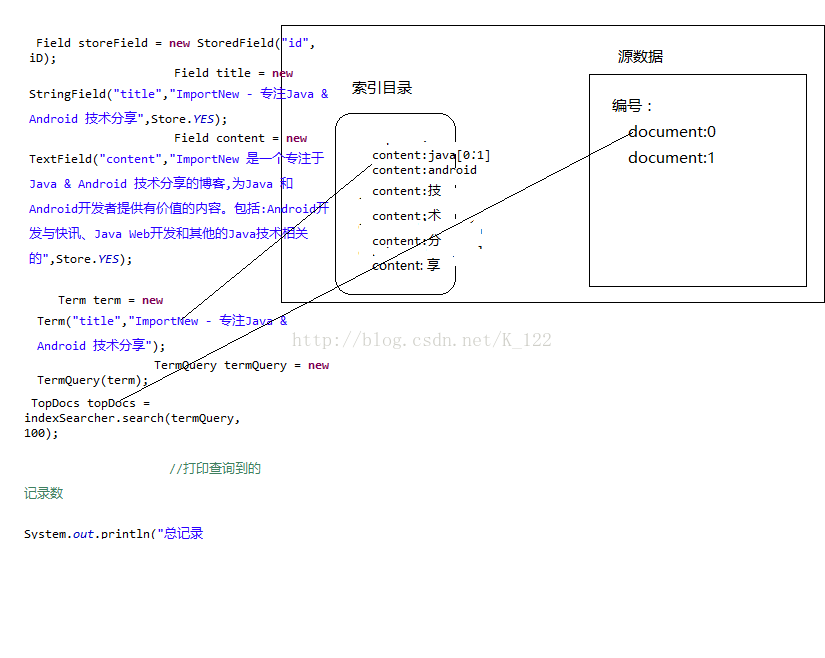
索引库包含数据区和索引目录区,查询时,通过查询索引目录看能命中几个数据区的document对象,来进行查询的
四,查询的方式和排序
lucene6.6不在支持过滤这种方式,改为使用查询代替过滤,当然查询本身也能过滤的。下面介绍
1.sort(排序),代码如下
public static void main(String[] args) throws Exception {
testSearcher("张总");
}
public static void testSearcher(String keywords) throws Exception{
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
//创建需要用于查询的字段数组
String[] fields = {"title"};
//创建查询用的类
QueryParser queryParser = new MultiFieldQueryParser(fields, LuceneUtil.getAnalyzer());
//查询符合关键字的数据
Query query = queryParser.parse(keywords);
//开始插叙
//创建排序字段,升序
// SortField sortField = new SortField("id", Type.INT);
//创建排序字段,降序
SortField sortField = new SortField("id", Type.INT,true);
//创建一个Sort排序
Sort sort = new Sort();
//添加排序条件
sort.setSort(sortField);
TopDocs topDocs = indexSearcher.search(query, 100,sort);
System.out.println("总记录数:"+topDocs.totalHits);
List list = new ArrayList();
//返回击中
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//int result = (start+rows)<(scoreDocs.length)?(start+rows):(scoreDocs.length);
//如果start+rowsVSscoreDocs.length的话,返回较小值
for(ScoreDoc scoreDoc : scoreDocs){
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("id"));
}
}
2.接下来说查询如下
public static void main(String[] args) throws Exception {
//第一种查询TermQuery
// Query query = new TermQuery(new Term("author","张三"));
// testSearcher(query);
//第二种查询 字符串查询
//String fields []={"author"};
//
//QueryParser queryParser=new MultiFieldQueryParser(LuceneUtils.getMatchVersion(),fields,LuceneUtils.getAnalyzer());
//Query query=queryParser.parse("毕加索");
//第三种查询,查询所有
// Query query = new MatchAllDocsQuery();
// testSearcher(query);
//第四种查询,范围查询,可以使用次查询来替代过滤器(lucene6.6不支持过滤)
//Query query = IntPoint.newRangeQuery("id", 1, 10);
//testSearcher(query);
/**
* 第五种查询,通配符拆查询
* ?代表单个任意字符
* *代表多个任意字符
*/
// Query query = new WildcardQuery(new Term("title","luce*"));
//testSearcher(query);
//第六种查询,模糊查询
/**
* 1.需要根据条件查询
*
* 2.最大可编辑数,取值范围0,1,2
* 允许我的查询条件的值,可以错误几个字符
*
*/
Query query = new FuzzyQuery(new Term("author","欧阳夏文某小"),1);
/**
* 第七种查询,短语查询
* @param slop:设置两个短语之间的最大间隔数,设置的间隔数越大,他能匹配的结果就越多,性能就越慢
* @param field:设置查找的字段
* @param terms:设置查找的短语,是一个可变长的数组
* (lucene4.4是用add方法来添加短语,6.6通过构造函数)
*/
//PhraseQuery query =new PhraseQuery(11,"title", new String[]{"lucene","全"});
/**
* 第八种查询,布尔查询(类似于sql语句中的 and,or等查询方式)
*
* (和lucene4.4使用方式有些区别,主要在于不能直接创建BooleanQuery,而是要创建BooleanQuery.Builder,)
*/
BooleanQuery.Builder booQuery = new BooleanQuery.Builder();
//范围查询id从0-10
Query query1 = IntPoint.newRangeQuery("id", 1, 10);
Query query2 = IntPoint.newRangeQuery("id", 5, 15);
booQuery.add(query1, Occur.MUST);
booQuery.add(query2,Occur.MUST_NOT);
//使用build方法返回BooleanQuery对象
Query query = booQuery.build();
testSearcher(query);
}
public static void testSearcher(Query query) throws Exception{
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
TopDocs topDocs = indexSearcher.search(query, 100);
System.out.println("总记录数:"+topDocs.totalHits);
List list = new ArrayList();
//返回击中
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc scoreDoc : scoreDocs){
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println(document.get("author"));
System.out.println(document.get("link"));
}
} 主要是api,不多说了,提下StringField和TextField在查询时的区别,StringField查询时必须是全部内容,比如author,你给他一个张,是查不出结果了,必须是全部内容"张三",而TextField则是可以的,
五,索引库的优化
1.使用lucene的api优化,代码如下
public void testOptimise1() throws Exception{
//可以通过indexWriterConfig这个对象来进行优化。。。
//在lucene4.0之后的版本会对索引进行自动的优化。。。
//改配置即可
Directory directory = FSDirectory.open(Paths.get(Contants.File_Path));
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(LuceneUtil.getAnalyzer());
//在lucene里面都是配置,都是拖过设置对象的参数来进行配置。。
/**
*
* MergePolicy设置合并规则
*
*/
LogDocMergePolicy mergePolicy = new LogDocMergePolicy();
/**
*
* 1.mergeFactor
*
* 当这个值越小,更少的内存被运用在创建索引的时候,搜索的时候越快,创建索引的时候越慢。。
* 当这个值越大,更多的内存被运用在创建索引的时候,搜索的时候越慢,创建索引的时候越快。。
*
* smaller value 2 < smaller<10
* big value big>10
*
*/
//设置索引的合并因子。。。
mergePolicy.setMergeFactor(6);
indexWriterConfig.setMergePolicy(mergePolicy);
IndexWriter indexWriter = new IndexWriter(directory,indexWriterConfig);
}
3.将索引数据分区存放
类似百度有,贴吧,新闻,网页,音乐不同索引区
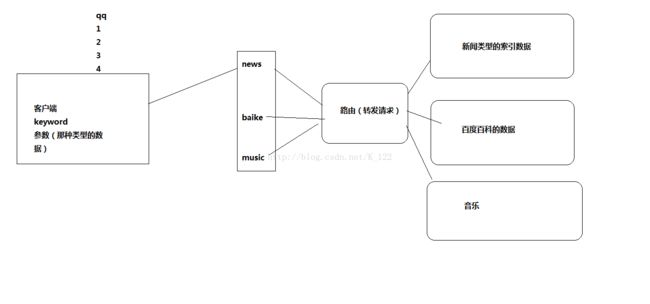
4.使用索引放到内存中提高索引效率
因为项目一旦上线,基本不会停下来,可以将索引放入内存提高效率
六.关于IKAnalyzer,
这是一个支持中文分词的工具包 ,支持扩展自己的词典和停用词
需要使用更新的版本,老版本不支持
下载地址:http://download.csdn.net/detail/k_122/9915646。对不起,我很穷,所以需要积分下载
七,关于高亮显示关键词
还要补充一些东西,查询BooleanQuery(布尔查询)和(PhraseQuery)短语查询,这两个和4.4版本的使用方式改变了不少
(我可是找了半天才弄好,技术不好啊!) 查询代码我放在上面的查询中了,你可以自己看,下面我说下高亮,一如既往的贴
代码
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
//创建需要用于查询的字段数组
String[] fields = {"title","content"};
//创建查询用的类
QueryParser queryParser = new MultiFieldQueryParser(fields, LuceneUtil.getAnalyzer());
//查询符合关键字的数据
Query query = queryParser.parse("张");
//格式化高亮的字符串
Formatter formatter = new SimpleHTMLFormatter("", "");
//query里面的条件,条件里面有搜索关键词
Scorer fragmentScorer = new QueryScorer(query);
//构建高亮插寻
/**
* 1.需要高亮什么颜色
* 2.将那些关键词进行高亮
*/
Highlighter highlighter = new Highlighter(formatter, fragmentScorer);
//开始插叙
TopDocs topDocs = indexSearcher.search(query,100);
System.out.println("总记录数:"+topDocs.totalHits);
List list = new ArrayList();
//返回击中
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//如果start+rowsVSscoreDocs.length的话,返回较小值
for(ScoreDoc scoreDoc:scoreDocs){
Article article = new Article();
int docID = scoreDoc.doc;
//System.out.println("docuemntID======="+docID);
Document document=indexSearcher.doc(docID);
String title = document.get("title");
String content = document.get("content");
System.out.println("没有高亮的title:"+title);
System.out.println("没有高亮的content:"+content);
//将某段文本进行高亮,返回高亮的结果
String highTitle = highlighter.getBestFragment(LuceneUtil.getAnalyzer(), "title",title);
String highContent= highlighter.getBestFragment(LuceneUtil.getAnalyzer(), "content",content);
//打印高亮后字符串
if(highTitle==null){
highTitle=title;
}
if(highContent==null){
highContent=content;
}
System.out.println("高亮后字符串 title:"+highTitle);
System.out.println("高亮后字符串 content:"+highContent);
}
} 代码中有,其实他就是在关键词那套个html标签而已。