看了又记不住的JAVA知识整理
一、JAVA基础
1.1 、JAVA中的数据类型
(1) 基本数据类型
| 数据类型 | 大小 | 位置范围 | 默认值 | 备注 |
| byte | 8位 | -128(-2^7)~127(2^7-1) | 0 | |
| short | 16位 | -32768(-2^15)~32768(2^15-1) | 0 | |
| int | 32位 | -2^31~2^31 - 1 | 0 | |
| long | 64位 | -2^63~2^63 - 1 | 0L | |
| float | 32位 | 1.4E-45~3.4028235E38 | 0.0f | 浮点数不能用来表示精确的值,如货币(货币使用BigDecimal) |
| double | 64位 | 4.9E-324~1.7976931348623157E308 | 0.0d | double类型同样不能表示精确的值,如货币 |
| char | 16位 | \u0000(0)~\uffff(65535) | char类型是一个单一的 16 位 Unicode 字符 | |
| boolean | / | true/false | false |
Float和Double的最小值和最大值都是以科学记数法的形式输出的,结尾的"E+数字"表示E之前的数字要乘以10的多少次方。比如3.14E3就是3.14 × 10^3 =3140,3.14E-3 就是 3.14 x 10^-3 =0.00314。
实际上,JAVA中还存在另外一种基本类型void,它也有对应的包装类 java.lang.Void,不过我们无法直接对它们进行操作。
(2) 引用类型
- 在Java中,引用类型的变量非常类似于C/C++的指针。引用类型指向一个对象,指向对象的变量是引用变量。这些变量在声明时被指定为一个特定的类型。变量一旦声明后,类型就不能被改变了。
- 对象、数组都是引用数据类型。
- 所有引用类型的默认值都是null。
1.2、什么是值传递和引用传递?
值传递:方法调用时,实际参数把它的值传递给对应的形式参数,方法执行中形式参数值的改变不影响实际参数的值。
引用传递:也称为传地址。方法调用时,实际参数的引用(地址,而不是参数的值)被传递给方法中相对应的形式参数,在方法执行中,对形式参数的操作实际上就是对实际参数的操作,方法执行中形式参数值的改变将会影响实际参数的值。
而在JAVA中只有值传递,基本类型传递的是值的副本,引用类型传递(不是上面说的引用传递)的是引用的副本。
举例详解:
https://blog.csdn.net/zhzhao999/article/details/53449504
https://www.cnblogs.com/volcan1/p/7003440.html
1.3、讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当 new 的时候, 他们的执行顺序。
父类静态代变量、
父类静态代码块、
子类静态变量、
子类静态代码块、
父类非静态变量(父类实例成员变量)、
父类构造函数、
子类非静态变量(子类实例成员变量)、
子类构造函数。
1.4、解释内存中的栈(stack)和 堆(heap) 的用法。
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
在函数中定义的一些【基本类型的变量】和【对象的引用变量】都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由【new创建的对象】和【数组】,在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象
java的stack只是存放本地变量,返回值和调用方法,stack分配的内存不需要是连续的。java的heap是所有线程共享的,堆存放所有 runtime data ,里面是所有的对象实例和数组,heap是JVM启动时创建。
1.5、HashMap和Hashtable的区别
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,在只有一个线程访问的情况下,效率要高于Hashtable。
就HashMap与HashTable主要从三方面来说
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value
1.6、排序算法
https://www.cnblogs.com/10158wsj/p/6782124.html?utm_source=tuicool&utm_medium=referral
二、Spring 和Spring MVC
2.1、Spring的原理
Spring的核心是IOC和AOP ,IOC是依赖注入和控制反转, 其注入方式可分为set注入、构造器注入、接口注入等等。IOC就是一个容器,负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。简单理解就是:JAVA每个业务逻辑处理至少需要两个或者以上的对象协作进行工作,但是每个对象在使用它的合作对象的时候,都需要频繁的new 对象来实现,你就会发现,对象间的耦合度高了。而IOC的思想是:Spring容器来管理这些,对象只需要处理本身业务关系就好了。至于什么是控制反转,就是获得依赖对象的方式反转了。
AOP呢,面向切面编程,最直接的体现就是Spring事物管理。
2.2、SpringMVC的原理以及返回数据如何渲染到jsp/html上?
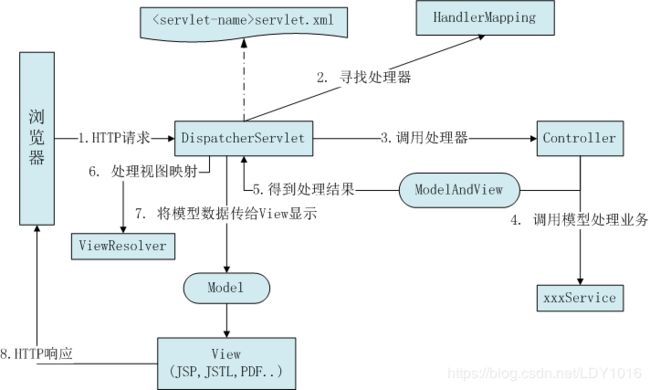
Spring MVC的核心就是 DispatcherServlet , 一个请求经过 DispatcherServlet ,转发给HandlerMapping ,然后经反射,对应 Controller及其里面方法的@RequestMapping地址,最后经ModelAndView和ViewResoler返回给对应视图 。
- 客户端请求提交到DispatcherServlet
- 由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller
- DispatcherServlet将请求提交到Controller
- Controller调用业务逻辑处理后,返回ModelAndView
- DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图
- 视图负责将结果显示到客户端
2.3、Spring事务传播行为
事物传播行为介绍:
@Transactional(propagation=Propagation.REQUIRED)
如果有事务, 那么加入事务, 没有的话新建一个(默认情况下)
@Transactional(propagation=Propagation.NOT_SUPPORTED)
容器不为这个方法开启事务
@Transactional(propagation=Propagation.REQUIRES_NEW)
不管是否存在事务,都创建一个新的事务,原来的挂起,新的执行完毕,继续执行老的事务
@Transactional(propagation=Propagation.MANDATORY)
必须在一个已有的事务中执行,否则抛出异常
@Transactional(propagation=Propagation.NEVER)
必须在一个没有的事务中执行,否则抛出异常(与Propagation.MANDATORY相反)
@Transactional(propagation=Propagation.SUPPORTS)
如果其他bean调用这个方法,在其他bean中声明事务,那就用事务.如果其他bean没有声明事务,那就不用事务.
2.3、BeanFactroy和ApplicationContext区别
1、BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化,这样,我们就不能发现一些存在的Spring的配置问题。而ApplicationContext则相反,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误。 相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
2、BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。(Applicationcontext比 beanFactory 加入了一些更好使用的功能。而且 beanFactory 的许多功能需要通过编程实现而 Applicationcontext 可以通过配置实现。比如后处理 bean , Applicationcontext 直接配置在配置文件即可而 beanFactory 这要在代码中显示的写出来才可以被容器识别。 )
3.beanFactory主要是面对与 spring 框架的基础设施,面对 spring 自己。而 Applicationcontex 主要面对与 spring 使用的开发者。基本都会使用 Applicationcontex 并非 beanFactory 。
总结
1、BeanFactory负责读取bean配置文档,管理bean的加载,实例化,维护bean之间的依赖关系,负责bean的声明周期。
2、ApplicationContext除了提供上述BeanFactory所能提供的功能之外,还提供了更完整的框架功能:
a. 国际化支持
b. 资源访问:Resource rs = ctx. getResource(“classpath:config.properties”), “file:c:/config.properties”
c. 事件传递:通过实现ApplicationContextAware接口
三、Hibernate和MyBatis
3.1 、hiberbate 原理
1.读取并解析配置文件
2.读取并解析映射信息,创建SessionFactory
3.打开Sesssion
4.创建事务Transation
5.持久化操作
6.提交事务
7.关闭Session
8.关闭SesstionFactory
3.2、 简述hibernate的缓存机制
hibernate分为2级缓存
一级缓存又叫session缓存,又叫事务级缓存,生命周期从事务开始到事务结束,一级缓存是hibernate自带的,暴力使用,当我们一创建session就已有这个缓存了。数据库就会自动往缓存存放,
二级缓存是hibernate提供的一组开放的接口方式实现的,都是通过整合第三方的缓存框架来实现的,二级缓存又叫sessionFactory的缓存,可以跨session访问。常用的EHcache、OScache,这个需要一些配置。
当我们每次 查询数据的时候,首先是到一级缓存查看是否存在该对象,如果有直接返回,如果没有就去二级缓存进行查看,如果有直接返回,如果没有在发送SQL到数据库查询数据,
当SQL发送查询回该数据的时候,hibernate会把该对象以主键为标记的形式存储到二级缓存和一级缓存,如果返回的是集合,会把集合打散然后以主键的形式存储到缓存。一级缓存和二级缓存只针对以ID查询的方式生效,get、load方法。
3.3、常用注解的使用方法
https://www.cnblogs.com/deng-cc/p/6420182.html
3.4、mybatis中的#和$的区别
1. #解析传递进来的参数数据。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id".
2. $对传递进来的参数原样拼接在SQL中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
3. #方式能够很大程度防止sql注入,能用#的就别用$,$方式无法防止Sql注入。
4.$方式一般用于传入传入表名、order by的参数、limit的参数
3.5、Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
3.6、MyBatis与Hibernate有哪些不同?
Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句,不过mybatis可以通过XML或注解方式灵活配置要运行的sql语句,并将java对象和sql语句映射生成最终执行的sql,最后将sql执行的结果再映射生成java对象。
Mybatis学习门槛低,简单易学,程序员直接编写原生态sql,可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件,工作量大。
Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用hibernate开发可以节省很多代码,提高效率。但是Hibernate的缺点是学习门槛高,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡,以及怎样用好Hibernate需要具有很强的经验和能力才行。
四、spring boot
4.1、SpringBoot 核心
@SpringBootApplication 这个 Spring Boot 核心注解是由其它三个重要的注解组合,分别是:@SpringBootConfiguration 、@EnableAutoConfiguration 和 @ComponentScan。
(1)@ SpringBootConfiguration
点开查看发现里面还是应用了@Configuration。任何一个标注了@Configuration 的 Java 类定义的都是一个 JavaConfig 配置类。SpringBoot 社区推荐使用基于 JavaConfig 的配置形式,所以,这里的启动类标注了@Configuration 之后,本身其实也是一个 IoC 容器的配置类。
(2)@EnableAutoConfiguration
是一个复合注解。最重要的是@Import(EnableAutoConfigurationImportSelector.class),借助EnableAutoConfigurationImportSelector,@EnableAutoConfiguration 可以帮助 SpringBoot 应用将所有符合条件的@Configuration 配置都加载到当前 SpringBoot 使用的 IoC 容器。
(3)@ComponentScan
这个注解在 Spring 中很重要,它对应 XML 配置中的元素, @ComponentScan 的功能其实就是自动扫描并加载符合条件的组件(比如@Component 和 @Repository 等)或者 bean 定义,最终将这些 bean 定义加载到 IoC 容器中。
4.2、@ServletComponentScan
在SpringBootApplication上使用@ServletComponentScan注解后,Servlet、Filter、Listener可以直接通过@WebServlet、@WebFilter、@WebListener注解自动注册,无需其他代码。
4.3、推荐文章
关于Spring Boot 这可能是全网最好的知识点总结:https://www.toutiao.com/i6646878877215883783/?tt_from=weixin&utm_campaign=client_share&wxshare_count=1×tamp=1548207768&app=news_article&utm_source=weixin&iid=58846995987&utm_medium=toutiao_android&group_id=6646878877215883783
五、JVM
5.1、谈谈你对JVM的理解?
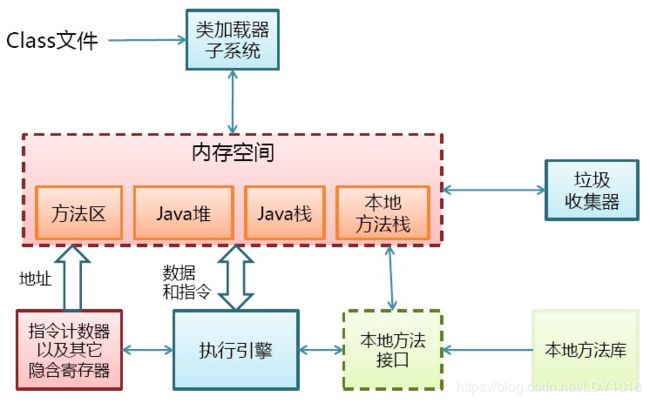
Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。Java虚拟机是一个可以执行Java字节码的虚拟机进程。Java源文件被编译成能被Java虚拟机执行的字节码文件,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。这就是Java的能够“一次编译,到处运行”的原因。
JVM执行程序的过程 :I.加载。class文件 ,II.管理并分配内存 ,III.执行垃圾收集
JRE(java运行时环境)由JVM构造的java程序的运行环境
JVM自生物理结构如下:
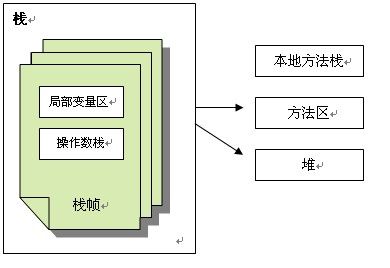
5.2JVM内存组成结构
JVM栈由堆、栈、本地方法栈、方法区等部分组成,结构图如下所示:
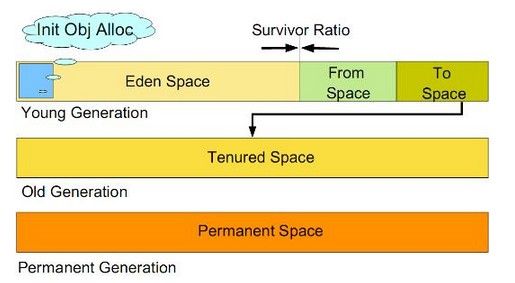
1)堆
所有通过new创建的对象的内存都在堆中分配,堆的大小可以通过-Xmx和-Xms来控制。堆被划分为新生代和旧生代,新生代又被进一步划分为Eden和Survivor区,最后Survivor由From Space和To Space组成,结构图如下所示:
-
新生代。新建的对象都是用新生代分配内存,Eden空间不足的时候,会把存活的对象转移到Survivor中,新生代大小可以由-Xmn来控制,也可以用-XX:SurvivorRatio来控制Eden和Survivor的比例
-
旧生代。用于存放新生代中经过多次垃圾回收仍然存活的对象
-
持久带(Permanent Space)实现方法区,主要存放所有已加载的类信息,方法信息,常量池等等。可通过-XX:PermSize和-XX:MaxPermSize来指定持久带初始化值和最大值。Permanent Space并不等同于方法区,只不过是Hotspot JVM用Permanent Space来实现方法区而已,有些虚拟机没有Permanent Space而用其他机制来实现方法区。

-Xmx:最大堆内存,如:-Xmx512m
-Xms:初始时堆内存,如:-Xms256m
-XX:MaxNewSize:最大年轻区内存
-XX:NewSize:初始时年轻区内存.通常为 Xmx 的 1/3 或 1/4。新生代 = Eden + 2 个 Survivor 空间。实际可用空间为 = Eden + 1 个 Survivor,即 90%
-XX:MaxPermSize:最大持久带内存
-XX:PermSize:初始时持久带内存
-XX:+PrintGCDetails。打印 GC 信息
-XX:NewRatio 新生代与老年代的比例,如 –XX:NewRatio=2,则新生代占整个堆空间的1/3,老年代占2/3
-XX:SurvivorRatio 新生代中 Eden 与 Survivor 的比值。默认值为 8。即 Eden 占新生代空间的 8/10,另外两个 Survivor 各占 1/10
2)栈
每个线程执行每个方法的时候都会在栈中申请一个栈帧,每个栈帧包括局部变量区和操作数栈,用于存放此次方法调用过程中的临时变量、参数和中间结果。
-xss:设置每个线程的堆栈大小. JDK1.5+ 每个线程堆栈大小为 1M,一般来说如果栈不是很深的话, 1M 是绝对够用了的。
3)本地方法栈
用于支持native方法的执行,存储了每个native方法调用的状态
4)方法区
存放了要加载的类信息、静态变量、final类型的常量、属性和方法信息。JVM用持久代(Permanet Generation)来存放方法区,可通过-XX:PermSize和-XX:MaxPermSize来指定最小值和最大值
六、其他面试题
1、Java高级工程师面试题总结及参考答案:https://www.cnblogs.com/java1024/p/8594784.html
2、36道Java经典基础与高级面试题:https://www.toutiao.com/i6636333587547292167/?tt_from=weixin&utm_campaign=client_share&wxshare_count=1×tamp=1548206049&app=news_article&utm_source=weixin&iid=58846995987&utm_medium=toutiao_android&group_id=6636333587547292167
3、精选30道Java笔试题解答:https://blog.csdn.net/lanxuezaipiao/article/details/16753743
4、java面试宝典(2018):https://blog.csdn.net/chen_2890/article/details/83928763