
前言
在开发十万博客系统的的过程中,前面主要分享了爬虫、缓存穿透以及文章阅读量计数等等。爬虫的目的就是解决十万+问题;缓存穿透是为了保护后端数据库查询服务;计数服务解决了接近真实阅读数以及数据库服务的压力。
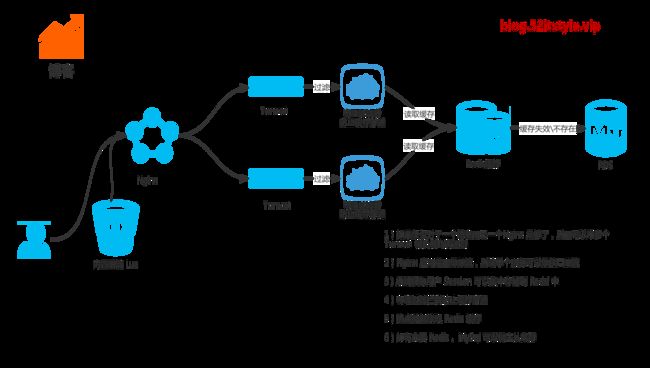
架构图
限流
就拿十万博客来说,如果存在热点文章,可能会有数十万级别的并发用户参与阅读。如果想让这些用户正常访问,无非就是加机器横向扩展各种服务,但凡事都有一个利益平衡点,有时候只需要少量的机器保证大部分用户在大部分时间可以正常访问即可。
亦或是,如果存在大量爬虫或者恶意攻击,我们必须采取一定的措施来保证服务的正常运行。这时候我们就要考虑限流来保证服务的可用性,以防止非预期的请求对系统压力过大而引起的系统瘫痪。通常的策略就是拒绝多余的访问,或者让多余的访问排队等待服务。
限流算法
任何限流都不是漫无目的的,也不是一个开关就可以解决的问题,常用的限流算法有:令牌桶,漏桶。
令牌桶
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送(百科)。
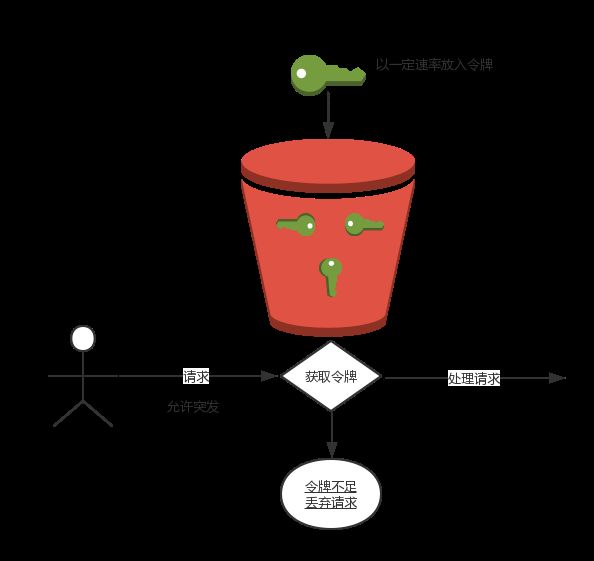
用户的请求速率是不固定的,这里我们假定为10r/s,令牌按照5个每秒的速率放入令牌桶,桶中最多存放20个令牌。仔细想想,是不是总有那么一部分请求被丢弃。
漏桶
漏桶算法的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量(百科)。

令牌桶是无论你流入速率多大,我都按照既定的速率去处理,如果桶满则拒绝服务。
应用限流
Tomcat
在Tomcat容器中,我们可以通过自定义线程池,配置最大连接数,请求处理队列等参数来达到限流的目的。
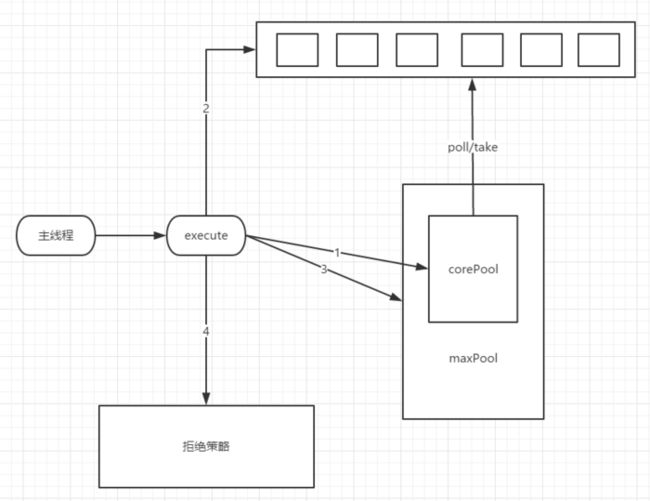
Tomcat默认使用自带的连接池,这里我们也可以自定义实现,打开/conf/server.xml文件,在Connector之前配置一个线程池:
- name:共享线程池的名字。这是Connector为了共享线程池要引用的名字,该名字必须唯一。默认值:None;
- namePrefix:在JVM上,每个运行线程都可以有一个name 字符串。这一属性为线程池中每个线程的name字符串设置了一个前缀,Tomcat将把线程号追加到这一前缀的后面。默认值:tomcat-exec-;
- maxThreads:该线程池可以容纳的最大线程数。默认值:200;
- maxIdleTime:在Tomcat关闭一个空闲线程之前,允许空闲线程持续的时间(以毫秒为单位)。只有当前活跃的线程数大于minSpareThread的值,才会关闭空闲线程。默认值:60000(一分钟)。
- minSpareThreads:Tomcat应该始终打开的最小不活跃线程数。默认值:25。
配置Connector
- executor:表示使用该参数值对应的线程池;
- minProcessors:服务器启动时创建的处理请求的线程数;
- maxProcessors:最大可以创建的处理请求的线程数;
- acceptCount:指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理。
API限流
这里我们采用开源工具包guava提供的限流工具类RateLimiter进行API限流,该类基于"令牌桶算法",开箱即用。
自定义定义注解
/**
* 自定义注解 限流
* 创建者 爪洼笔记
* 博客 https://blog.52itstyle.vip
* 创建时间 2019年8月15日
*/
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ServiceLimit {
/**
* 描述
*/
String description() default "";
/**
* key
*/
String key() default "";
/**
* 类型
*/
LimitType limitType() default LimitType.CUSTOMER;
enum LimitType {
/**
* 自定义key
*/
CUSTOMER,
/**
* 根据请求者IP
*/
IP
}
}自定义切面
/**
* 限流 AOP
* 创建者 爪洼笔记
* 博客 https://blog.52itstyle.vip
* 创建时间 2019年8月15日
*/
@Aspect
@Configuration
@Order(1)
public class LimitAspect{
//根据IP分不同的令牌桶, 每天自动清理缓存
private static LoadingCache caches = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.DAYS)
.build(new CacheLoader() {
@Override
public RateLimiter load(String key){
// 新的IP初始化 每秒只发出5个令牌
return RateLimiter.create(5);
}
});
//Service层切点 限流
@Pointcut("@annotation(com.itstyle.blog.common.limit.ServiceLimit)")
public void ServiceAspect() {
}
@Around("ServiceAspect()")
public Object around(ProceedingJoinPoint joinPoint) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
ServiceLimit limitAnnotation = method.getAnnotation(ServiceLimit.class);
ServiceLimit.LimitType limitType = limitAnnotation.limitType();
String key = limitAnnotation.key();
Object obj;
try {
if(limitType.equals(ServiceLimit.LimitType.IP)){
key = IPUtils.getIpAddr();
}
RateLimiter rateLimiter = caches.get(key);
Boolean flag = rateLimiter.tryAcquire();
if(flag){
obj = joinPoint.proceed();
}else{
throw new RrException("小同志,你访问的太频繁了");
}
} catch (Throwable e) {
throw new RrException("小同志,你访问的太频繁了");
}
return obj;
}
} 业务实现:
/**
* 执行顺序
* 1)限流
* 2)布隆
* 3)计数
* 4) 缓存
* @param id
* @return
*/
@Override
@ServiceLimit(limitType= ServiceLimit.LimitType.IP)
@BloomLimit
@HyperLogLimit
@Cacheable(cacheNames ="blog")
public Blog getById(Long id) {
String nativeSql = "SELECT * FROM blog WHERE id=?";
return dynamicQuery.nativeQuerySingleResult(Blog.class,nativeSql,new Object[]{id});
}
分布式限流
Nginx
如何使用Nginx实现基本的限流,比如单个IP限制每秒访问50次。通过Nginx限流模块,我们可以设置一旦并发连接数超过我们的设置,将返回503错误给客户端。
配置nginx.conf
#统一在http域中进行配置
#限制请求
limit_req_zone $binary_remote_addr $uri zone=api_read:20m rate=50r/s;
#按ip配置一个连接 zone
limit_conn_zone $binary_remote_addr zone=perip_conn:10m;
#按server配置一个连接 zone
limit_conn_zone $server_name zone=perserver_conn:100m;
server {
listen 80;
server_name blog.52itstyle.top;
index index.jsp;
location / {
#请求限流排队通过 burst默认是0
limit_req zone=api_read burst=5;
#连接数限制,每个IP并发请求为2
limit_conn perip_conn 2;
#服务所限制的连接数(即限制了该server并发连接数量)
limit_conn perserver_conn 1000;
#连接限速
limit_rate 100k;
proxy_pass http://seckill;
}
}
upstream seckill {
fair;
server 172.16.1.120:8080 weight=1 max_fails=2 fail_timeout=30s;
server 172.16.1.130:8080 weight=1 max_fails=2 fail_timeout=30s;
}配置说明
imit_conn_zone
是针对每个IP定义一个存储session状态的容器。这个示例中定义了一个100m的容器,按照32bytes/session,可以处理3200000个session。
limit_rate 300k;
对每个连接限速300k. 注意,这里是对连接限速,而不是对IP限速。如果一个IP允许两个并发连接,那么这个IP就是限速limit_rate×2。
burst=5;
这相当于桶的大小,如果某个请求超过了系统处理速度,会被放入桶中,等待被处理。如果桶满了,那么抱歉,请求直接返回503,客户端得到一个服务器忙的响应。如果系统处理请求的速度比较慢,桶里的请求也不能一直待在里面,如果超过一定时间,也是会被直接退回,返回服务器忙的响应。
OpenResty
这里我们使用 OpenResty 开源的限流方案,测试案例使用OpenResty1.15.8.1最新版本,自带lua-resty-limit-traffic模块以及案例 ,实现起来更为方便。
限制接口总并发数/请求数
热点博文,由于突发流量暴增,有可能会影响整个系统的稳定性从而造成崩溃,这时候我们就要限制热点博文的总并发数/请求数。
这里我们采用 lua-resty-limit-traffic中的resty.limit.count模块实现:
-- 限制接口总并发数/请求数
local limit_count = require "resty.limit.count"
-- 这里我们使用AB测试,-n访问10000次, -c并发1200个
-- ab -n 10000 -c 1200 http://121.42.155.213/ ,第一次测试数据:1000个请求会有差不多8801请求失败,符合以下配置说明
-- 限制 一分钟内只能调用 1200 次 接口(允许在时间段开始的时候一次性放过1200个请求)
local lim, err = limit_count.new("my_limit_count_store", 1200, 60)
if not lim then
ngx.log(ngx.ERR, "failed to instantiate a resty.limit.count object: ", err)
return ngx.exit(500)
end
-- use the Authorization header as the limiting key
local key = ngx.req.get_headers()["Authorization"] or "public"
local delay, err = lim:incoming(key, true)
if not delay then
if err == "rejected" then
ngx.header["X-RateLimit-Limit"] = "5000"
ngx.header["X-RateLimit-Remaining"] = 0
return ngx.exit(503)
end
ngx.log(ngx.ERR, "failed to limit count: ", err)
return ngx.exit(500)
end
-- the 2nd return value holds the current remaining number
-- of requests for the specified key.
local remaining = err
ngx.header["X-RateLimit-Limit"] = "5000"
ngx.header["X-RateLimit-Remaining"] = remaining限制接口时间窗请求数
现在网络爬虫泛滥,有时候并不是人为的去点击,亦或是存在恶意攻击的情况。此时我们就要对客户端单位时间内的请求数进行限制,以至于黑客不是那么猖獗。当然了道高一尺魔高一丈,攻击者总是会有办法绕开你的防线,从另一方面讲也促进了技术的进步。
这里我们采用 lua-resty-limit-traffic中的resty.limit.conn模块实现:
-- well, we could put the require() and new() calls in our own Lua
-- modules to save overhead. here we put them below just for
-- convenience.
local limit_conn = require "resty.limit.conn"
-- 这里我们使用AB测试,-n访问1000次, -c并发100个
-- ab -n 1000 -c 100 http://121.42.155.213/ ,这里1000个请求将会有700个失败
-- 相同IP段的人将不能被访问,不影响其它IP
-- 限制 IP 总请求数
-- 限制单个 ip 客户端最大 200 req/sec 并且允许100 req/sec的突发请求
-- 就是说我们会把200以上300一下的请求请求给延迟, 超过300的请求将会被拒绝
-- 最后一个参数其实是你要预估这些并发(或者说单个请求)要处理多久,可以通过的log_by_lua中的leaving()调用进行动态调整
local lim, err = limit_conn.new("my_limit_conn_store", 200, 100, 0.5)
if not lim then
ngx.log(ngx.ERR,
"failed to instantiate a resty.limit.conn object: ", err)
return ngx.exit(500)
end
-- the following call must be per-request.
-- here we use the remote (IP) address as the limiting key
-- commit 为true 代表要更新shared dict中key的值,
-- false 代表只是查看当前请求要处理的延时情况和前面还未被处理的请求数
local key = ngx.var.binary_remote_addr
local delay, err = lim:incoming(key, true)
if not delay then
if err == "rejected" then
return ngx.exit(503)
end
ngx.log(ngx.ERR, "failed to limit req: ", err)
return ngx.exit(500)
end
if lim:is_committed() then
local ctx = ngx.ctx
ctx.limit_conn = lim
ctx.limit_conn_key = key
ctx.limit_conn_delay = delay
end
-- the 2nd return value holds the current concurrency level
-- for the specified key.
local conn = err
if delay >= 0.001 then
-- 其实这里的 delay 肯定是上面说的并发处理时间的整数倍,
-- 举个例子,每秒处理100并发,桶容量200个,当时同时来500个并发,则200个拒掉
-- 100个在被处理,然后200个进入桶中暂存,被暂存的这200个连接中,0-100个连接其实应该延后0.5秒处理,
-- 101-200个则应该延后0.5*2=1秒处理(0.5是上面预估的并发处理时间)
-- the request exceeding the 200 connections ratio but below
-- 300 connections, so
-- we intentionally delay it here a bit to conform to the
-- 200 connection limit.
-- ngx.log(ngx.WARN, "delaying")
ngx.sleep(delay)
end
平滑限制接口请求数
之前的限流方式允许突发流量,也就是说瞬时流量都会被允许。突然流量如果不加以限制会影响整个系统的稳定性,因此在秒杀场景中需要对请求整形为平均速率处理,即20r/s。
这里我们采用 lua-resty-limit-traffic 中的resty.limit.req 模块实现漏桶限流和令牌桶限流。
其实漏桶和令牌桶根本的区别就是,如何处理超过请求速率的请求。漏桶会把请求放入队列中去等待均速处理,队列满则拒绝服务;令牌桶在桶容量允许的情况下直接处理这些突发请求。
漏桶
桶容量大于零,并且是延迟模式。如果桶没满,则进入请求队列以固定速率等待处理,否则请求被拒绝。
令牌桶
桶容量大于零,并且是非延迟模式。如果桶中存在令牌,则允许突发流量,否则请求被拒绝。
压测
为了测试以上配置效果,我们采用AB压测,Linux下执行以下命令即可:
# 安装
yum -y install httpd-tools
# 查看ab版本
ab -v
# 查看帮助
ab --help测试命令:
ab -n 1000 -c 100 http://127.0.0.1/测试结果:
Server Software: openresty/1.15.8.1 #服务器软件
Server Hostname: 127.0.0.1 #IP
Server Port: 80 #请求端口号
Document Path: / #文件路径
Document Length: 12 bytes #页面字节数
Concurrency Level: 100 #请求的并发数
Time taken for tests: 4.999 seconds #总访问时间
Complete requests: 1000 #总请求树
Failed requests: 0 #请求失败数量
Write errors: 0
Total transferred: 140000 bytes #请求总数据大小
HTML transferred: 12000 bytes #html页面实际总字节数
Requests per second: 200.06 [#/sec] (mean) #每秒多少请求,这个是非常重要的参数数值,服务器的吞吐量
Time per request: 499.857 [ms] (mean) #用户平均请求等待时间
Time per request: 4.999 [ms] (mean, across all concurrent requests) # 服务器平均处理时间,也就是服务器吞吐量的倒数
Transfer rate: 27.35 [Kbytes/sec] received #每秒获取的数据长度
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.8 0 4
Processing: 5 474 89.1 500 501
Waiting: 2 474 89.2 500 501
Total: 9 475 88.4 500 501
Percentage of the requests served within a certain time (ms)
50% 500
66% 500
75% 500
80% 500
90% 501
95% 501
98% 501
99% 501
100% 501 (longest request)源码
SpringBoot开发案例之打造十万博文Web篇
总结
以上限流方案,只是针对此次十万博文做一个简单的小结,大家也不要刻意区分那种方案的好坏,只要适合业务场景就是最好的。