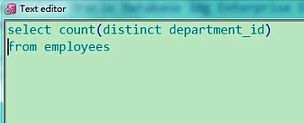
1. 查询 employees 表中有多少个部门
select count(distinct department_id)
from employees
查询employees表中有多少部门,这个我们已经讲到了,我们就直接来看一看,我们来回忆一下,有多少个
部门我们当然要用到count,分组函数了,我们加了一个叫distinct,如果我们要是不加的话,就这样写,
他实际上就会列出个数很多了,我们看一下
select count(department_id) from employees

106个,不可能有这么多部门,你这里面每一条记录每一个员工,全是这个有值的,都算是一条记录,
一共有106个人都有部门,就一个人没有部门,所以没有部门那个人就剔除出去了,只有106个,这显然是不对的,
我们部门就10多个部门,所以要求加上distinct,这样他就能够去重,把重复的都给去掉,只选择不一样的id
select count(distinct department_id) from employees

11个部门,这是这个题,希望大家注意,distinct啥意思,那这个题目就这样了
2. 查询全公司奖金基数的平均值(没有奖金的人按 0 计算)
select avg(nvl(commission_pct, 0))
from employees
查询全公司奖金基数的平均值,没有奖金的按0来计算,这个题目练什么的,就是说我们的组函数,他在进行运算的
时候,不去算空值在内的,所以想求出全公司的奖金值,那就得把为null的全都给算进去,按0来计算,用到nvl这样
一个通用函数,所以需要大家注意
3. 查询各个部门的平均工资
--错误: avg(salary) 返回公司平均工资, 只有一个值; 而 department_id 有多个值, 无法匹配返回
select department_id, avg(salary)
from employees
**在 SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中
--正确: 按 department_id 进行分组
select department_id, avg(salary)
from employees
group by department_id
查询各个部门的平均工资,这是我们说错误的做法,当你查询当中使用组函数,当你使用到组函数的时候,而且还存在着
非组函数列的时候,要求这些列必须都得放在group by当中,否则的话会报错
4. Toronto 这个城市的员工的平均工资
SELECT avg(salary)
FROM employees e JOIN departments d
ON e.department_id = d.department_id
JOIN locations l
ON d.location_id = l.location_id
WHERE city = 'Toronto'
查询Toronto这个城市的平均工资,我们来写一下这个题目,查询这个城市员工的平均工资,select查询平均工资,
avg(salary),查询平均工资,这个工资我们知道,是在employees表中的,那Toronto这个是在哪个表,我带大家看看这个,
这个希望你对这个表结构要熟悉,Toronto是表示一个城市,是在locations这个表里面,现在我们要查询Toronto这个城市的
平均工资,是不是相当于我要把这个表连起来,要想连接employees表和locations表,中间我还得用到departments这个表,
那我们这个相当于多表连接,是我们上一节讲的内容,我们这儿就直接来用了,这里写的时候我们也讲了两种方式,一种是
通用的方式,一种是涉及到SQL99的方式,两种方式都行,我们现在就写其中一种了,from employees,叫e,departments d,
locations l,这三个表然后得写连接条件,三个表至少得有两个连接条件,不写连接条件就会出现笛卡尔积的错误了,
e.department_id等于d.department_id,and d.location_id等于l.location_id,这连接条件也写完了,然后呢我们看,
只让你输出Toronto这个城市,所以我们再加上一个连接条件,and l.city = 'Toronto',如果城市大写小写或者首字母大写,
你要是不保险的话就加一个lower,当你这个city全部改成小写以后,就长这样
select avg(salary) from employees e,departments d,locations l where e.department_id=d.department_id
and d.location_id=l.location_id and lower(l.city) = 'toronto'
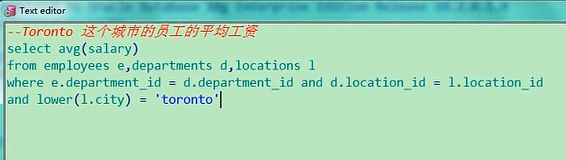

这是Toronto城市的平均工资,有的人说我想把Toronto给显示出来,那在这加个city吧,这样运行你说
有没有问题,别忘了,知识点得灵活运用,这里写city,又没有加载group by当中,就挂了
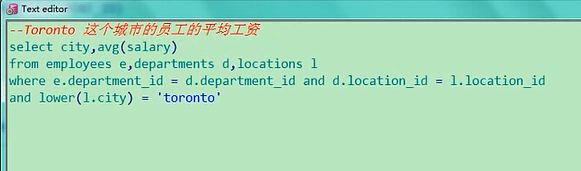

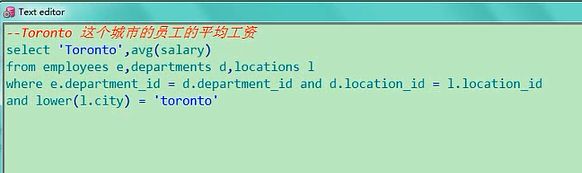
你要是就像显示一个Toronto怎么办,你就直接这样呗
select 'Toronto',avg(salary) from employees e,departments d,locations l where
e.department_id=d.department_id and d.location_id=l.location_id
and lower(l.city)='toronto'

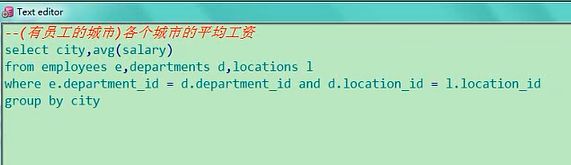
5. (有员工的城市)各个城市的平均工资
SELECT city, avg(salary)
FROM employees e JOIN departments d
ON e.department_id = d.department_id
JOIN locations l
ON d.location_id = l.location_id
GROUP BY city
有员工的城市,各个城市的工资,刚才我们写的是一个城市的平均工资,现在是各个城市的平均工资,
在上一个题目的基础之上我们做一个修改,有员工的各个城市,前面就是city,加个l点也行,不加也没事,
city,avg,然后呢,group by city,要求必须出现在group by当中,那这个题目写完没有,有的人说写完了,
前面有一个有员工条件的限制呢,这个怎么表达,大家回忆一下我们讲的多表查询的时候说,我们这样实现
的连接,没有使用外连接的话,没有哪个表有的,不存在的,那样的话我们才使用外连接,内连接是他们都有
数据的时候,有些城市可能没有员工,也就没有工资,那就在适当的位置加加号,这个题目是这样
select city,avg(salary) from employees e,departments d,locations l where
e.department_id=d.department_id and d.location_id=l.location_id
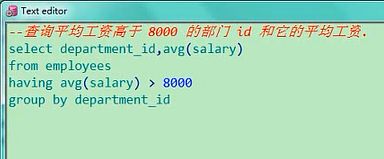
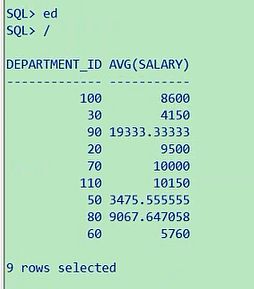
6. 查询平均工资高于 8000 的部门 id 和它的平均工资.
SELECT department_id, avg(salary)
FROM employees e
GROUP BY department_id
HAVING avg(salary) > 8000
39. 查询平均工资高于 6000 的 job_title 有哪些
SELECT job_title, avg(salary)
FROM employees e join jobs j
ON e.job_id = j.job_id
GROUP BY job_title
HAVING avg(salary) > 6000
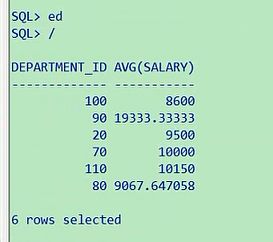
查询平均工资高于8000的部门id和他的平均工资,平均工资高于8000的部门id和平均工资,不难吧,
department_id,平均工资avg(salary),from employees,平均工资大家注意了,这是不是一个过滤条件,
如果过滤条件使用组函数,要求他的avg(salary)大于8000,平均工资大于8000的,部门id以及他的平均工资,
select department_id,avg(salary) from employees having avg(salary)>8000 group by
department_id
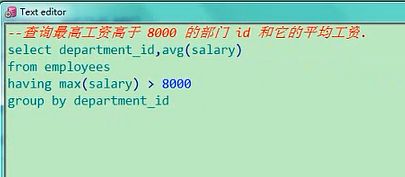
如果要是最高工资,大于8000的,那你就把这里改成max,最高工资大于8000的部门id和他的平均工资,
select department_id,avg(salary) from employees having max(salary)>8000 group by
department_id
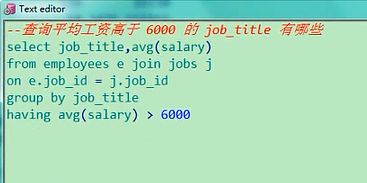
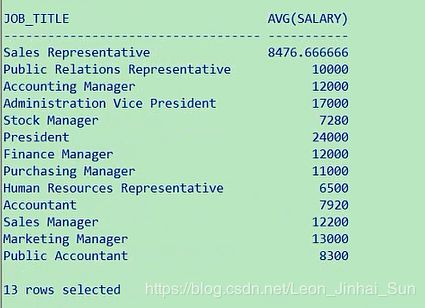
7. 查询平均工资高于 6000 的 job_title 有哪些
SELECT job_title, avg(salary)
FROM employees e join jobs j
ON e.job_id = j.job_id
GROUP BY job_title
HAVING avg(salary) > 6000
查询平均工资高于6000的job_title有哪些,job_title可能大家没怎么接触过,我们看job_title,job_title在这,
job_title有哪些,又涉及到和平均工资挂钩了,跟job两个表做连接,这两个表做连接,那我们就来呗,平均工资高于
6000的job_tile,select job_title,然后我也给你列一下你的平均工资,from employees,我换一种方式,join jobs
表,然后呢on,我们加上一个别名e,你看他们的连接条件是job_id,e.job_id=j.job_id,这个写完以后,你就得group by了,
group by job_title,同时有一个having过滤条件,avg(salary)要求大于6000
select job_title,avg(salary) from employees e join jobs j on e.job_id=j.job_id group by job_title
having avg(salary)>6000
为什么要讲SQL的语言,后面我们要讲JDBC,我们通过JAVA嵌套这些SQL语句,来实现JAVA应用程序对数据库的一个
调用,就想你访问京东的网站,京东后台都改成JAVA来写了,你的用户的信息,你的购物车的信息,相当于我们利用JAVA
应用程序在前台,我们给他往后台去调用的时候,需要嵌套SQL语句来实现,有这样的一个操作的
1. 组函数处理多行返回一行吗?
是
组函数处理多行返回一行,对,所以因为这样他才叫组函数,你要是处理一行返回一行叫单行函数,那有没有多行返回
多行的,没有,函数因变量,最后输出只有一个,要不然不叫函数了
2. 组函数不计算空值吗?
是
组函数不计算空值吗,对,因为它不计算空值,所以我们才用到nvl,
3. where子句可否使用组函数进行过滤?
不可以,用having替代
这个我们要严格注意,不可以的,用什么,用having替代,如果你要是没有组函数的话,就可以用where过滤
4. 查询公司员工工资的最大值,最小值,平均值,总和
a) select max(salary),min(salary),avg(salary),sum(salary)
b) from employees
查询公司员工工资的最大值,最小值,平均值,总和,这个不难,select max(salary),min(salary),
平均avg,总和sum,这是整个公司的,没有涉及到其他的,所以就这样写呗
select max(salary),min(salary),avg(salary),sum(salary) from employees


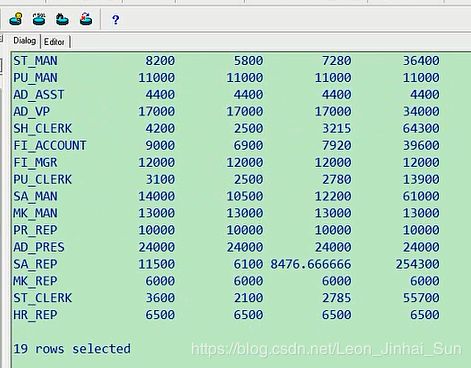
5. 查询各job_id的员工工资的最大值,最小值,平均值,总和
a) select job_id,max(salary),min(salary),avg(salary),sum(salary)
b) from employees
c) group by job_id
查询各job_id员工的最大值,最小值,平均值,总和,这可以用一下group by,不同job_id的,
max(salary),min(salary),然后avg(salary),sum(salary) from employees,大家需要注意一下,
得用group by,这里就是按不同的job_id来进行区分,最大最小平均求总和
select job_id,max(salary),min(salary),avg(salary),sum(salary) from employees
group by job_id

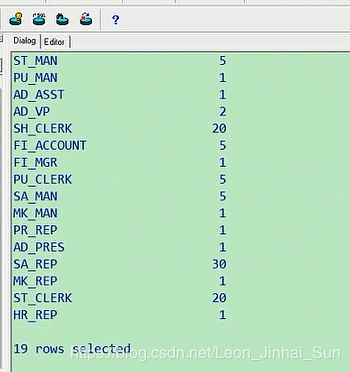
6. 选择具有各个job_id的员工人数
a) select job_id,count(employee_id)
b) from employees
c) group by job_id
选择具有各个job_id的员工人数,查询一下各个job_id的员工人数,select job_id,人数count,
count按什么来写,*也行,也可以写上一个employee_id也行,from employees,group by
job_id
select job_id,count(employee_id) from employees group by job_id
7. 查询员工最高工资和最低工资的差距(DIFFERENCE)
a) select max(salary),min(salary),max(salary)-min(salary) "DIFFERENCE"
b) from employees
查询员工最高工资和最低工资的差距,最低工资min(salary),他们之间的差距,不就是最高的减去最低的,
然后起了一个别名叫DIFFERENCE,from employees
select max(salary),min(salary),max(salary)-min(salary) "DIFFERENCE" from employees


8. 查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
a) select manager_id,min(salary)
b) from employees
c) where manager_id is not null
d) group by manager_id
e) having min(salary) >= 6000
查询各个管理者首先员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内,这都是一些条件
限制,或者叫过滤条件,前边是我们真正要查的,他让查询各个管理者,manager_id,这个就是各个管理者的id,你看看
他手下的工资,按照管理者进行一个分组,比如101号,这是一个管理者,他10个人里面谁是最低的,最低工资min(salary),
from employees,先把他写出来,不同管理者手下的,最低工资,然后看后边的要求,其中最低工资不能够低于6000,没有
管理者的员工不计算在内,没有管理者的员工就是where,manager_id is not null,having,最低工资min,要求不能低于那就
是大于等于6000
select manager_id,min(salary) from employees where manager_id is not null group by manager_id
having min(salary)>=6000

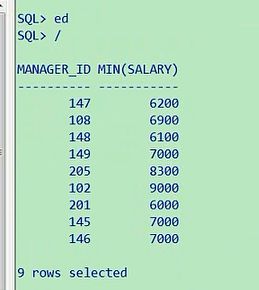
这是不同的manager_id,这是他手下的工资,少于6000的就给过滤掉,有些人可能会有这个疑问,
我这而既用了where又用了having,那我能不能把这个给他注掉,能不能写在一起,都写在having,
having不是表示过滤吗
select manager_id,min(salary) from employees group by manager_id having min(salary)>=6000
and manager_id is not null

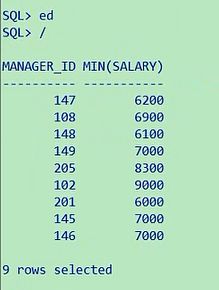
是不是也行啊,两种方式都可以,我们看一下第九题
9. 查询所有部门的名字,location_id,员工数量和工资平均值
a) select department_name,location_id,count(employee_id),avg(salary)
b) from employees e right outer join departments d
c) on e.department_id = d.department_id
d) group by department_name,location_id
查询所有部门的名字,location_id,员工的数量和工资的平均值,所有部门的名字,名字在departments表里,
然后location_id,location_id也是他这个表里的,员工数量和工资平均值,select department_name,location_id,
员工数量count(*),工资的平均值avg(salary),from employees e,join departments d,on d.department_id=
d.department_id,这是有连接条件了,然后呢,是不是要把它放在group by当中了,group by department_id,
所有部门的,有的部门没有人,他要所有的那怎么办,相当于departments这个表的数据多,employees这个表的
少一点,这边得整个加号,相当于是右外连接,right outer join,假设我们要不加的话,我先给你删掉
select department_name,location_id,count(*),avg(salary) from employees e join departments d
on e.department_id=d.department_id group by department_name,location_id
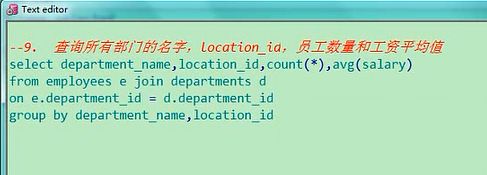
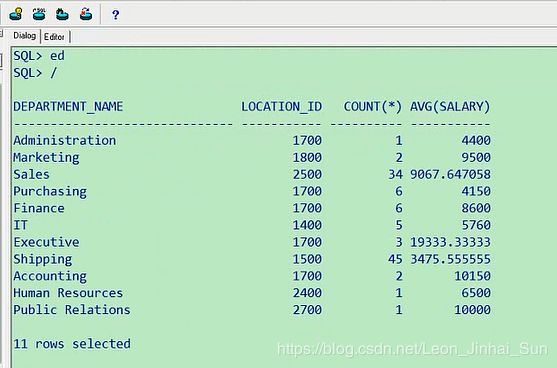
有11个部门,都对应的有值,加上right outer join
select department_name,location_id,count(*),avg(salary) from employees e right outer join
departments d on e.department_id=d.department_id group by department_name,location_id


这里的count(*)显示的是1,这个要怎么去理解啊,我们看一下我们刚才写到这,我们这写一个count(*),他只要
显示的是1,我们前面放的是department_name,相当于部门往这里放,所以这里显示的是1,那这里我们不写*了,
我就写employee_id,这样就看到,假设你这个部门里边,没有员工的话,相当于都是null,现在我们看一下这个结果,
这个时候就对了
select department_name,location_id,count(employee_id) from employees e right outer join departments d
on e.department_id=d.department_id group by department_name,location_id
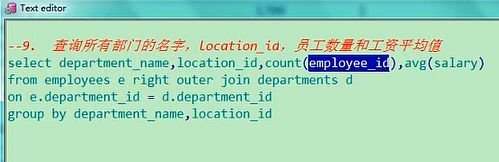
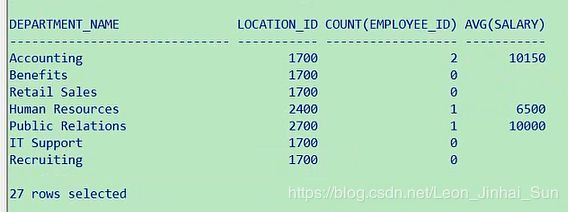

这个题有一个表格,这个题第10题有点难度,要结合我们讲的条件表达式了,当然这个写法也不唯一,
各种各样的,你选择一个你好理解的,当然尽量的简洁,查询公司在95年和98年之间,每年雇佣的人数,
结果类似于下面的格式,95年到98年,这是总共有20个人,这是各年分别的人数,那么这个怎么来写,
这个年之间的所有人数,肯定是用到组函数了,这个题目我们先给他分解一下,当然这是需要我们一次性查出来的,
不能说我查这些年之间的,我再查一次95年的,再查一次96年的,它是让你通过一次查询,把这个表格一次的给他列出来,
那我们先分着来,大家能不能通过一个查询操作把这个给搞定了,查询一下95年,到98年这个之间,总人数一共有多少,
总人数有多少,怎么写啊,select,肯定是count了,查询一下,count(*),然后起一个别名,total,from employees,
这样你要是写的话,是不是106,107了,他说只让找95年到98年之间的,那就相当于是一个过滤条件,那我就用where来写了,
where要求你的hire_date,hire_date只要你在95年到98年,95,98我用字符的话,我要给他转成字符,我用的to_char,
然后转成我只要年就可以了,yyyy,当你转成这个格式以后,这个现在是一个char类型的,这个年我只让你in,哪几个啊,
1995,1996,1997,1998,是这个意思吧,只让在这之间的,我们先看一下这个结果是多少
select count(*) "total" from employees where to_char(hire_date,'yyyy') in ('1995','1996','1997','1998')


65个人,也就是在95年到98年之间,一共是有65个人来了,现在他想让你在一个里面去写,怎么来处理啊,
正常一个表中出现,是不是刚才是一列,是不是再要整一列,然后这里面是95年参与运算的,然后再来一个,
96年参与运算的,然后再接着往后,实际上95年,96年你只要搞定一个,我们先写一个95年的,先这样写吧,
当你进来一条数据的时候,肯定这边要走一下,95年到98年的数据,都往这里走的话,每一条都算一下,
当你每一条数据都往95年走的话,我让仅仅95的加一个1,其他的三年都不加,怎么就能让他不加,我们讲的
只要=他不是空的就不加,相当于我们进来一条数据,看看你是不是95年的,是不是得进行一个判断,如果你是
95年的,我就让你加1,不是的话,就不加1,我们使用判断,decode吧,decode谁,decode(hire_date),判断是不是95年,
这又是一个字符串,还得使用一个to_char,hire_date还是转成只要年的这种格式,大家一定要特别小心这个小括号,
我这儿得补一个小括号,当这个时候变成字符以后,我这里加个逗号吧,字符它是1995年的,如果是这一年的话,后面定义
这一年的值,我给你一个值,一个1,给一个值叫做1,如果不是95年的呢,我直接让你else就完了呗,给你一个null,这个时候
非常巧妙,当你这些年过来这些数据的时候,我到这儿判断的时候,看看你这个hire_date是不是95,如果是95,给值是1,
其他的都作为else,变成null,这样你在count的时候,我再给他取一个别名,别名1995,再加上一个逗号,然后96是不是也是这样做,
太长了我给他拉到下一行,这是95年的,我们先看一眼,我们先看一眼对不对
select count(*) "total",
count(decode(to_char(hire_date,'yyyy')),1,null) "1995"
from employees
where to_char(hire_date,'yyyy') in ('1995','1996','1997','1998')
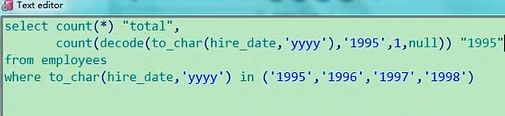
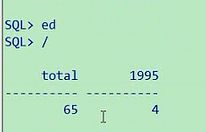
好了,95年的出来了,这个题目就基本上迎刃而解了,我要算96年的话,我只要补一个96的,97的,98的,
改一下,把这个逗号去了,这是不是就行了
select count(*) "total",
count(decode(to_char(hire_date,'yyyy'),'1995',1,null)) "1995",
count(decode(to_char(hire_date,'yyyy'),'1996',1,null)) "1996",
count(decode(to_char(hire_date,'yyyy'),'1997',1,null)) "1997",
count(decode(to_char(hire_date,'yyyy'),'1998',1,null)) "1998"
from employees
where to_char(hire_date,'yyyy') in ('1995','1996','1997','1998')
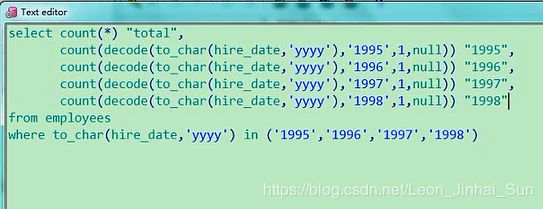

这就是我们这个题目,就是这样来解决的,你算一下这四个数加起来,是不是65