深度学习:词嵌入(Word Embedding)以及Keras实现
深度学习:词嵌入(Word Embedding)以及Keras实现
1.文本数据需要预处理成张量的形式,才能输入到神经网络。
2.文本划分成单元的过程叫做分词过程(tokenization),分成的单元叫做标记(token)。
3.文本可以划分为,单词、字符(abcdefg…)、n-gram等等。
4.一般用one-hot编码或者word-embedding将单词处理为数值张量。
5.one-hot编码简单,但是没有结构,任何两个单词之间的距离为 2 \sqrt2 2。
6.word-embedding空间维度较小,空间中具有结构,相似的单词距离近,不相关的单词距离远。
7.embedding层的作用实际上可以看作是一个矩阵,将高维空间中的点映射到低维空间中。
----------------------------------分割线---------------------------------
正文:
神经网络无法对原始的文本数据训练,我们需要先将文本数据处理成数值张量,这一过程又叫文本向量化(vectorize)
文本向量化有多种策略:
1.将文本分割为单词,每个单词转换为一个向量
2.将文本分割为字符,每个字符转化为一个向量
3.提取单词或者字符的n-gram,将n-gram转换为一个向量
将文本分解成的单元叫做标记(token),将文本分解成标记的过程叫做分词(tokenization)
简单的讲,我们要讲文本数据输入到神经网络,让它去训练,但是神经网络并不能直接处理文本数据,我们需要讲文本数据预处理成神经网络能够理解的格式,也就是以下过程:
文本 → \rightarrow → 分词 → \rightarrow → 向量化
词向量化的方法主要有两种:
1.one-hot编码
2.word embedding
----------------------------------分割线---------------------------------
one-hot encoding(独热编码)
为什么叫做one-hot呢?每一个单词经过one-hot编码后,只有一个位置的元素为1,其他位置全为0。
比如说“the boy is crying”这句话(假设世界上额英文单词就这四个),经过one-hot编码后,
the 对应(1,0,0,0)
boy 对应(0,1,0,0)
is 对应(0,0,1,0)
crying 对应(0,0,0,1)
每一个单词对应向量中的一个位置,这个位置就表示这个单词。
但是这样表示 的话就需要非常高的维度,因为假设所有的词汇表有100000个单词,那么每一个单词就需要用一个长度为100000的向量表示。
the 对应(1,0,0,0,…,0)(长度为100000)
boy 对应(0,1,0,0,…,0)
is 对应(0,0,1,0,…,0)
crying 对应(0,0,0,1,…,0)
得到高维度稀疏的张量。
----------------------------------分割线---------------------------------
Word Embedding(词嵌入)
与此相对的,词嵌入是将单词嵌入到一个低维的稠密的空间中。
例如同样的“the boy is crying”这句话(同样假设全世界的英文单词就这4个),经过编码以后可能变成了:
the 对应(0.1)
boy 对应(0.14)
is 对应(0)
crying 对应(0.82)
我们假设嵌入的空间为256维(一般是256,512或者1024维,词汇表越大,对应的空间维度越高)
那么
the 对应(0.1,0.2,0.4,0,…)(向量长度为256)
boy 对应(0.23,0.14,0,0,…)
is 对应(0,0,0.41,0.9,…)
crying 对应(0,0.82,0,0.14,…)
one-hot编码非常简单,但是空间维度很高。
而且对于one-hot编码来说,任何两个单词之间的距离都是 2 \sqrt2 2,但是在实际情况中,单词(boy)到单词(man)的距离应该很接近(因为它们联系紧密),而单词(cat)到单词(stone)的距离应该很远(因为它们基本上不相关)
Embedding空间维度低,且可以让空间拥有结构。
例如可以从向量之间的距离体现性别,年龄等等(这需要训练,没有经过训练的embedding层没有任何结构),例如:
男人-女人=男孩-女孩
男人-爸爸=女人-妈妈
在keras中,Embedding层需要两个参数,一个是标记(token)中单词的个数,另一个是嵌入的维度
from keras.layers import Embedding
embedding_layer = Embedding(1000,64)
1000:代表token的长度为1000(可以认为是词汇表中所有单词的个数)
64:代表嵌入64维空间(可以认为有64个属性,如想象成人的眼睛形状,鼻子形状,嘴巴形状,身高,体重,年龄,等等,合起来就是一个人(单词),64维向量表示一个单词,一千个这样的单词表示词汇表中所有的单词)
embedding层输入:一个二维张量,形状为(samples,sequential_length)
samples:代表不同的句子。
sequential_length:代表句子中的单词的个数,每个单词对应一个数字,一共sequential_length个单词。
embedding层输出:一个三维张量,形状为(samples,sequential_length,dimensionality)
samples:代表不同的句子。
sequential_length:代表句子中的单词的个数
dimensionality:代表通道数,同一samples,同一sequential_length上的所有通道上的值组成的向量表示一个单词,如(0,0,:)代表一个单词。
可以将embedding层看成是一个矩阵,假设输入是(100,20),100个长度为20的序列,词汇表长度为10000,Embedding(10000,8),输出为(100,20,8)
因为每一个序列经过one-hot编码后可以看作是(20,10000),和(10000,8)的矩阵做矩阵乘法,得到(20,8)的矩阵,所以100个这样的序列经过embedding层后就变成了(100,20,8)
embedding层如何训练可以参考:Word2Vec
----------------------------------分割线---------------------------------
keras数值实验
实例化一个Embedding层:
from keras.models import Sequential
from keras.layers import Flatten,Dense,Embedding
model = Sequential()
model.add(Embedding(10000,8,input_length=maxlen))
model.add(Flatten())
model.add(Dense(1,activation='sigmoid'))
model.summary()
输出结果为:
可以看到在embedding层中,我们需要训练8乘以10000=80000个参数。训练好的embedding层中每一行都代表了一个单词的向量。
在IMDB数据上使用Embedding层和分类器
在keras内置的imdb数据集,有已经分类好的正负评价和已经向量化了的评价内容,我们用Embedding层和分类器来训练一个神经网络,看看表现如何。
from keras.datasets import imdb
from keras import preprocessing
from keras.models import Sequential
from keras.layers import Flatten,Dense,Embedding
max_features = 10000
maxlen = 20
#只读取最常用的10000字的评论(此处的评论已经处理为数值向量)
(x_train,y_train),(x_test,y_test) = imdb.load_data(num_words=max_features)
#将训练数据和测试数据处理成数值张量
x_train = preprocessing.sequence.pad_sequences(x_train,maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test,maxlen=maxlen)
#建立模型
model = Sequential()
#嵌入空间
model.add(Embedding(10000,8,input_length=maxlen))
model.add(Flatten())
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
history = model.fit(x_train,y_train,epochs=10,batch_size=32,validation_split=0.2)
结果如下:
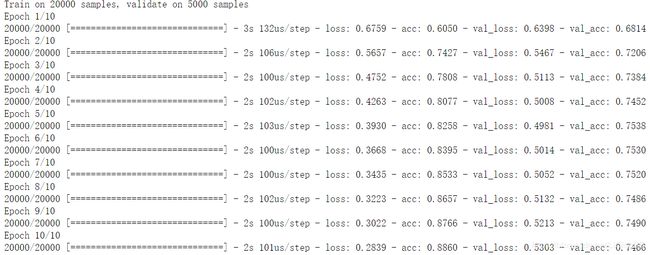
画个图仔细观察一波:
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label='acc')
plt.plot(epochs,val_acc,'b',label='val_acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'bo',label='loss')
plt.plot(epochs,val_loss,'b',label='val_loss')
plt.legend()
plt.show()
输出结果:


可以看到验证精度大概在75%左右。