容器云在万达的落地经验
容器生态是现在非常火热的技术生态之一,个人认为它主要囊括着四个方面的技术栈:一是容器核心技术栈(包括 Docker、rkt 及第三方公司自主研发的容器 Engine 等);二是容器基础技术栈(包括容器网络、存储、安全及服务发现等);三是容器编排技术栈(包括 Mesos/Marathon、Swarm、Kubernetes 及 OpenShift 等);四是容器应用技术栈(主要包括 CI/CD、监控、日志及微服务框架等)。而 Docker 和 Kubernetes 分别又是目前容器与容器编排界的小宠儿,所以我将带着小宠从这四方面分享一些容器云在万达的落地经验。
![]()
“经济基础决定上层建筑”,对于整个容器云平台来说,Kubernetes 平台就是我们的“经济基础”,所以在建设之初我们为了保证平台的稳定、高可用还是做了不少工作。先来看看 Kubernetes 平台的建设涉及到的几个技术点:
组件的高可用性如何保证?
组件以何种方式部署安装?
集群以何种方式快速扩缩容?
如何实现环境的批量配置及组件的批量升级?
为了较好的描述这些,我画了一张我们容器云中 Kubernetes 各组件高可用架构与部署图,请见:
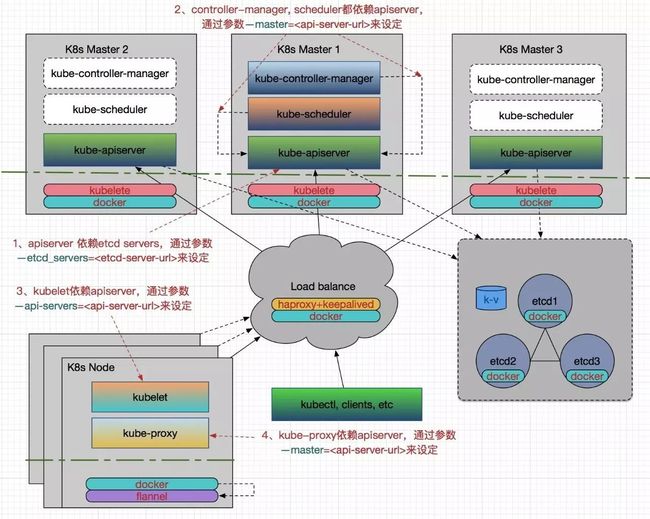
Kubernetes 所有组件都容器化了,而不采用二进制安装的方式。这样对于组件的部署、配置更新和升级等都比较容易,只需要先安装好 Docker,提前做好镜像,然后直接 docker run --restart=always --name xxx_component xxx_component_image:xxx_version就可以了,这里 --restart=always 非常重要,用来保证主机重启后或由于突发状况引起的非错误性退出后组件服务自动恢复。
注意在升级过程中,为了减少组件服务的宕机时间,需要提前下载好新制作的镜像版本,因为如果镜像挺大的话,在 docker restart 进行更新前会耗费一些时间在 docker pull 上面。
在批量部署方面,我们采用 Ansible 工具。由于 Kubernetes 集群部署的文档网上蛮多的,所以这里就简要介绍一下组件的高可用部分。我们都知道 Kubernetes 实现了应用的高可用,而针对 Kubernetes 自身的 HA,主要还是在 Etcd 和 Kubernetes Master 组件上面。
1、 Etcd 的高可用性部署
Etcd 使用的是 V3(3.0.3)的版本,比 V2 版本性能强很多。Etcd 组件作为一个高可用强一致性的服务发现存储仓库,它的 HA 体现在两方面:一方面是 Etcd 集群自身需要以集群方式部署,以实现 Etcd 数据存储的冗余、备份与高可用;另一方面是 Etcd 存储的数据需要考虑使用可靠的存储设备。


如果需要升级则只需要修改一下 etcd_version 并提前拉取新版本镜像,重新跑一下 ansible-playbook --limit=etcds -i hosts/cd-prod k8s.yaml --tags etcd 即可完成秒级升级,这样一般显得简洁易用。当然 Etcd 在升级过程中还涉及到数据的迁移备份等,这个可以参考官方文档进行。
2、Kubernetes Master 的高可用性部署
Kubernetes 的版本我们更新的不频繁,目前使用的是 V1.6.6。Master 的三个组件是以 Static Pod 的形式启动并由 kubelet 进行监控和自动重启的,而 kubelet 自身也以容器的方式运行。
对于 kube-apiserver 的 HA,我们会配置一个 VIP,通过 haproxy 和 keepalived 来实现,其中 haproxy 用于负载均衡,而 keepalived 负责对 haproxy 做监控以保证它的高可用性。后面就可以通过 VIP:Port 来访问 apiserver。
对于 kube-controller-manager 和 kube-scheduler 的 HA,由于它们会修改集群的状态,所以对于这两个组件,高可用不仅要保证有多个实例,还需要保证在多个实例间实现 leader 的选举,因此在启动参数中需要分别设置 --leader-elect=true。
![]()
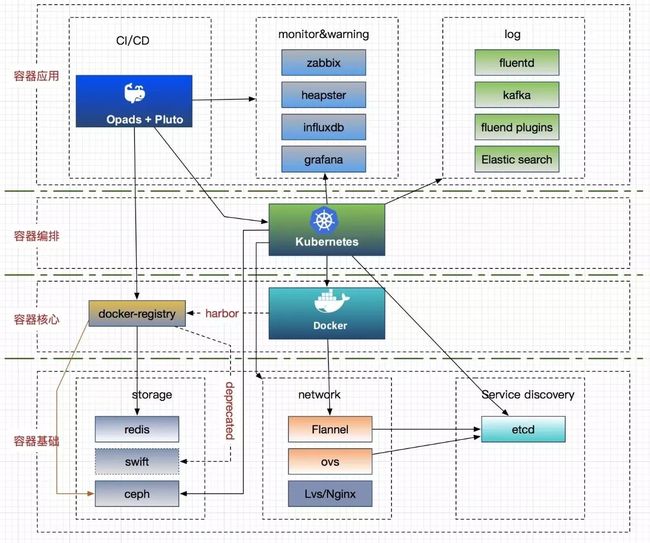
后端存储主要采用 Ceph 驱动,这里主要介绍它在有状态服务和 docker-registry 两方面的应用。

具体 ceph rbd 配置,详见:Persistent Volume Provisioning 官网(http://t.cn/R0cbWrx)。
rbd 支持动态供应,支持单节点读写,多节点读,但不支持多节点写。如果有业务需要多节点写的话,rbd 就比较受限制。目前由于只有 GlusterFS 既允许动态供应,又支持单节点和多节点读写,所以我们也正在调研其相关使用。

具体的 config.yml 配置,详见:docker-registry 官方配置(http://t.cn/R0cbrfN)。但后来为了保证 docker-registry 的高可用,我们采用 Harbor 做 HA,并以 Pod 的形式运行在 Kubernetes 集群上,镜像数据以及 Harbor-db 全部通过 Ceph 的 PV 来挂载,这样就保证在 Harbor 主机挂了或者 Pod 故障后,Harbor 也可以 HA 了,同时我们也不需要额外维护 Swift 了。
另外注意一个问题,由于 PV,StorageClass 都局限于单个 Namespace 下,所以对于想通过 Namespace 来区分多租户使用动态存储的情况目前是不满足的。
2、网络方案
底层容器网络我们最初使用的是官方推荐的 Flannel,现在部分集群已经由 Flannel 切换成了 OVS 。 Flannel 可以很容易的实现 Pod 跨主机通信,但不能实现多租户隔离,也不能很好的限制 Pod 网络流量,所以我们网络同事开发了 K8S-OVS 组件来满足这些需求。它是一个使用 Open VSwitch 为 Kubernetes 提供 SDN 功能的组件。该组件基于 OpenShift SDN 的原理进行开发。由于 OpenShift 的 SDN 网络方案和 OpenShift 自身的代码耦合在一起,无法像 Flannel 和 Calico 等网络方案以插件的方式独立的为 Kubernetes 提供服务,所以开发了 K8S-OVS 插件,它拥有 OpenShift 优秀的 SDN 功能,又可以独立为 Kubernetes 提供服务。
K8S-OVS 支持单租户模式和多租户模式,主要实现了如下功能:
单租户模式直接使用 Openvswitch+Vxlan 将 Kubernetes 的 Pod 网络组成一个大二层,所有 Pod 可以互通。
多租户模式也使用 Open vSwitch+Vxlan 来组建 Kubernetes 的 Pod 网络,但是它可以基于 Kubernetes 中的 Namespace 来分配虚拟网络从而形成一个网络独立的租户,一个 Namespace 中的 Pod 无法访问其他 Namespace 中的 Pod 和 Service。
多租户模式下可以对一些 Namespace 进行设置,使这些 Namespace 中的 Pod 可以和其他所有 Namespace 中的 Pods 和 Services 进行互访。
多租户模式下可以合并某两个 Namespace 的虚拟网络,让他们的 Pods 和 Services 可以互访。
多租户模式下也可以将上面合并的 Namespace 虚拟网络进行分离。
单租户和多租户模式下都支持 Pod 的流量限制功能,这样可以保证同一台主机上的 Pod 相对公平的分享网卡带宽,而不会出现一个 Pod 因为流量过大占满了网卡导致其他 Pod 无法正常工作的情况。
单租户和多租户模式下都支持外联负载均衡。
下面举例解释一下:
合并是指两个不同租户的网络变成一个虚拟网络从而使这两个租户中的所有 Pod 和 Service 能够互通;分离是指针对合并的两个租户,如果用户希望这两个租户不再互通了则可以将他们进行分离;全网化是指有一些特殊的服务需要能够和其他所有的租户互通,那么通过将这种特殊的租户进行全网化操作就可以实现。

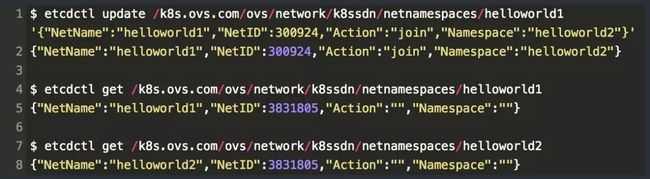
合并之后观察 helloworld1 和 helloworld2 ,发现两个租户的 NetID 变为相同的了。这样两个网络的 Pod 和 Service 就可以相互访问了。其他场景一样,通过 etcdctl update 来控制 Action 从而改变 NetID 来实现租户的隔离与互通。这里不过多演示。
在应用方面,我们实现了 LVS 的四层,Ingress(基于 Nginx+Ingress Controller) 的七层负载均衡,各 Kubernetes 集群环境中陆续弃用了 Kubernetes 自带的 kube-proxy 及 Service 方案。
3、CI/CD 方案
CI/CD(持续集成与部署)模块肩负着 DevOps 的重任,是开发与运维人员的桥梁,它实现了业务(应用)从代码到服务的自动上线,满足了开发过程中一键的持续集成与部署的需求。
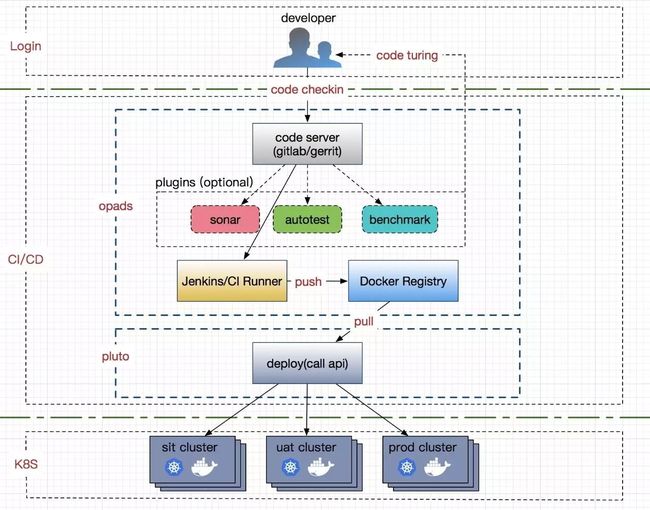
业务代码从公司内部的 GitLab/Gerrit 中拉取后,用户选择不同的分支版本(比如:sit/uat/prod)经过 Jenkins 构建后,生成相应的镜像并 Push 到相应的镜像仓库中,底层 CD 模块从相应的仓库上线到相应的 Kubernetes 集群(sit/uat/prod)中,而不需要 care 底层平台实现。
在整个 CI/CD 过程中,基础镜像的制作比较关键,我们按不同的业务分类提前制作不同的应用镜像(如:Tomcat、PHP、Java、NodeJS等)并打上所需的版本号,后面源代码既可以 mount 到相应的容器目录,也可以利用在 Dockerfile 的 ONBUILD 命令完成业务代码的加载。挂载的方式优点是比较灵活,也不需要重复构建,上线效率高;缺点是对于基础镜像环境的依赖较高,如果一个业务的基础镜像一直未改动,但代码中又有了对新组件库的调用或者依赖,则很容易失败。onbuild 的方式和 mount 方式恰好相反,它每次都进行 build,解决了环境的依赖,后面版本回滚也方便,缺点是需要每次进行镜像构建,效率低。这些看业务自己的选择。

我们还实现了服务扩缩容,弹性伸缩(HPA)、负载均衡、灰度发布等,也加入了代码质量检查(Sonar)、自动化测试及性能测试插件等,这些都是 CI/CD PaaS 平台的重要组成部分。
4、容器监控与告警方案
容器监控的对象主要包括 Kubernetes 集群(各组件)、应用服务、Pod、容器及网络等。这些对象主要表现为以下三个方面:
Kubernetes 集群自身健康状态监控(5 个基础组件、Docker、Etcd、Flannel/OVS 等);
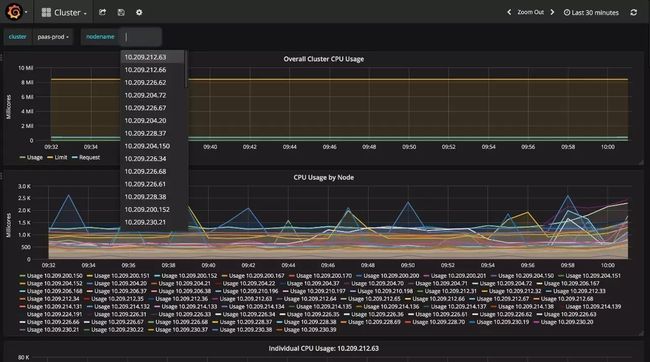
系统性能的监控,比如:CPU、内存、磁盘、网络、filesystem 及 processes 等;
业务资源状态监控,主要包括:rc/rs/deployment、Pod、Service 等。
Kubernetes 组件相关的监控,我们写了相关的 shell 脚本,通过 crond 开启后监控各组件状态。
容器相关的监控,我们采用传统的 Heapster+InfluxDB+Grafana 方案:
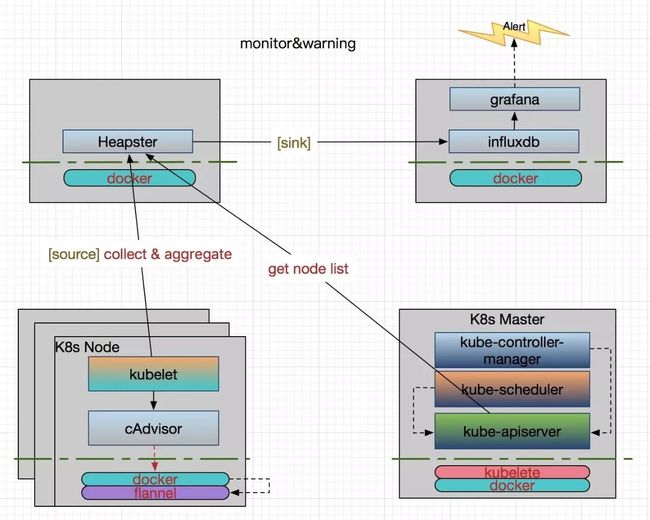
Heapster 首先从 Kubernetes Master 获取集群中所有 Node 的信息,每个 Node 通过 kubelet 调用 cAdvisor API 来采集所有容器的数据信息(资源使用率和性能特征等)。这样既拿到了 Node 级别的资源使用状况信息,又拿到了容器级别的信息,它可以通过标签来分组这些信息,之后聚合所有监控数据,一起 sink到 Heapster 配置的后端存储中(InfluxDB),通过 Grafana 来支持数据的可视化。所以需要为 Heapster 设置几个重要的启动参数,一个是 --source 用来指定 Master 的 URL 作为数据来源,一个是 --sink 用来指定使用的后端存储系统(InfluxDB),还有就是 --metric_resolution 来指定性能指标的精度,比如:30s 表示将过去 30 秒的数据进行聚合并存储。
这里说一下 Heapster 的后端存储,它有两个,一个是 metricSink,另一个是 influxdbSink。metricSink 是存放在本地内存中的 metrics 数据池,会默认创建,当集群比较大的时候,内存消耗会很大。Heapster API 获取到的数据都是从它那获取的。而 influxdbSink 接的是我们真正的数据存储后端,在新版本中支持多后端数据存储,比如可以指定多个不同的 InfluxDB。

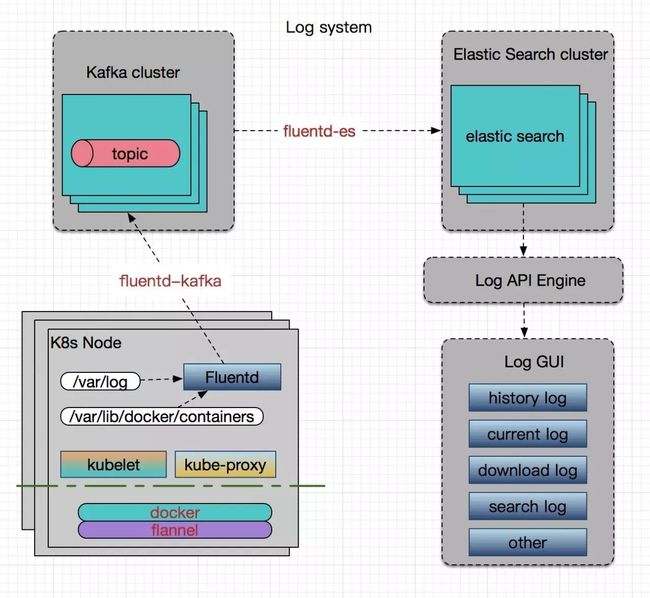
5、日志方案
容器平台的日志系统一般包括:Kubernetes 组件的日志,资源的事件日志及容器所运行的应用的日志。所以一个好的日志系统至少需要 cover 到这几块。
日志这块一直是我们头痛的地方,之前我们主要关心容器中的业务日志,所以是直接将其日志对接到公司的统一日志平台(Hippo)中。他们需要我们采用 Flume 来进行日志采集,每个业务以 Pod 的方式运行 Flume ,在 Flume 中配置好 source, channel 和 sink 参数。source 用来指定业务挂载的日志目录,然后通过 channel 进行输送,最后 sink 到后端的 Hippo 所使用的 Kafka 中。业务需要查看日志,则需要登录到 Hippo 平台中。
![]()
下面挑几个坑说一下,并分享一下解决方法。
Docker 相关
早期由于混合使用了 Deployment 和 RC,此时如果使用了同名 Pod label 则会产生冲突,RC 会删除 Deployment 后创建的 Pod,造成 Pod 的反复创建与删除,最终导致 Node 上的 Docker daemon 挂僵掉。原因是 Docker device mapper 互锁而触发 Linux kernel bug(特别是有大量的 outbound traffic 时),解决方法是升级内核到 3.10.0-327.22.2,或者添加内核补丁(http://t.cn/R0ctbEV)。
Kubernetes 相关
业务应用在升级过程中,如果 Docker 删除出错, 偶偶会导致 device mapper busy,则会显示 Pod 一直在销毁,但其实它的 Deployment 已经被删除了,这种我们没有找到很好的处理方法,现有 workaround 是先重启 docker daemon,如果不能解决,再 reboot 主机。一般的做法是先 drain 掉所有的 Pod,然后待重启解决后,再 uncordon 回来。
存储相关
当某一 Pod 挂载 Ceph rbd 的 Volume 时,如果删除 Pod,再重新创建,由于 PVC 被 lock 导致无法挂载,会出现 volume 死锁问题。由于我们的 kubelet 是容器部署,而 ceph 组件是以挂载的方式开启的,所以猜测可能是由于 kubelet 容器部署引起,但后面改用二进制方式部署并升级到 V1.6.6 版本后就可以解决。当时的版本是 V1.5.2。
在业务上线过程中,一定要进行规范化约束,比如,当时将 Flannel 升级到 K8S-OVS 网络升级过程中出现有些业务采用 Service 进行负载均衡的情况,这种依赖于 kube-dns,由于 Flannel 和 OVS 的网段不一样,Service 层又没有打通,导致以 Service 运行并通过 kube-dns 解析时会出问题,且网络不通,本可以采用新建一个以 OVS 同网段的 kube-dns 来完成不同网段的兼容,但最后面发现该业务是根本不使用 Service,而是直接利用了 Pod,这样非规范化上线的业务很容易导致升级相关的故障出现,猜测可能当时平台建设初期手动上过业务,其实这方面我们也可以加些监控。
告警相关
CPU load 是通过每个核的 running queue(待运行进程队列)计算出来的,某些情况下 running queue 会变成 -1 也就是 4294967295。由于在 cpu 过载的时候,我们设置了告警,所以会被触发,但其实这时的 CPU 负载是正常的。此时,如果通过 sar -q ,top,w,uptime 等看到的 running queue 都是有问题后的值,只有用 vmstat 查看才是真实的。解决方法是重启 Node,因为这个值只有在重启后才会重置为零,或者升级内核补丁(http://t.cn/R0ctJMM)。
![]()
Q:请问如何实现容器限速的?
A:你是说容器的网络限速吗?流量限制功能我们是通过在 Pod 的 annotations 字段设置 kubernetes.io/ingress-bandwidth (设置输入流量带宽)和 kubernetes.io/egress-bandwidth (设置输出流量带宽)来实现。Q:请问使用什么操作系统部署 Kubernetes,有什么考虑?
A:用的 CentOS 7,企业一般的用法,还有就是它稳定,不容易出问题,Kubernetes 和 Docker 的支持比较好。Q:如何把所有告警信息全部递给 Zabbix,Zabbix 自身是否也获取了监控值信息了?
A:全部推送压力大,先将 APIserver、Heapster 中相关的信息放 MySQL,中间做个数据库。Q:etcd 3 的容灾和安全做了吗?
A:etcd 非常关键,我们会在升级和定期用 etcdctl 做 backup。升级时需将 --initial-cluster-state 改为 existing ,安全方面还没有。Q:做灰度发布或 HPA 自动扩容时,实现了不影响正在提供服务的服务吗?
A:灰度发布不会影响服务,我们使用了 Ingress + Nginx 来保证 Pod 的变化不受影响。HPA 这块我们不敢上线,功能完成了,但没有经过大量测试。Q:etcd 3 在哪些方面不如 etcd 2?
A:没有去做对比,etcd 3 是通过搜集了 etcd 2 用户的反馈和实际扩展 etcd 2 的经验基础上全新设计了 API 的产品。etcd 3 在效率,可靠性和并发控制上改进比较多。etcd 2 支持多语言客户端驱动,etcd 3 由于采用 gRPC,很多需要自己实现驱动。Q:请问有状态的 Pod 迁移,使用 ceph pv 是怎么保证分到同一个 volume?
A:我们用的是 StorageClass,在 PVC 时指定和 StorageClass 名字一样就可。通过 volume.beta.kubernetes.io/storage-class 来指定该名字。Q:请问有没有对比过共有的容器云和私有的容器云的优缺点?
A:公有云比较难做,我们之前是做私有云(物理资源隔离,用户数据更安全可控;独占资源,不受干扰;自行规划灵活调整资源复用比例,成本更优),公有云(公有云弹性,自如应对业务变化;具备跨机房、跨地区的容灾能力)我们也在做,正在和 IBM 合作。Q:请教多 master 下,当某个 master down 掉,default/kubernetes endpoints 中的 IP 没更新的问题,你们是如何处理的?
A:这个主要是 Endpoints 控制器负责 Endpoints 对象的创建,更新。新 leader master 掌管后,Kubernetes 会用 checkLeftoverEndpoints 来删除 没有响应的服务的 endpoints,重启一下 kube-controller-manager 试试。Spring Cloud实战训练营
![]()
本次培训内容包括:微服务架构及概述、微服务架构项目实战目标、Spring Boot概述、Spring Cloud简介与入门、Eureka、Ribbon、Feign、Hystrix、Zuul、Spring Cloud Config、Spring Cloud Sleuth等,点击识别下方二维码加微信好友了解具体培训内容。
