GPT-2解读(论文 + TensorFlow实现)
GPT-2是对GPT的一个升级,并且更着重于将思路放在为何pretrain是有用的上面,认为LM本身是一个Multi-task Learner,并且大力用ZSL实验来佐证这个思路。
文章目录
- 一. 前言
- 二. GPT-2原理
- 1. 数据集
- 2. 输入表征
- 3. 模型
- 三. 实验
- 四. TensorFlow实现
- 1. 模型结构
- 2. 文本续写
- 五. 总结
- 优势
- 不足
- 传送门
一. 前言
GPT-2相比于GPT,笔者感觉主要有三点改进:1)大数据;2)大模型;3)很好的一个insight观点。还不熟悉GPT的读者可以戳这里。
前两点就不用说了,最后一点其实在GPT-2的论文题目中就已经体现出来了,也是贯彻全文的一个重要观点:《Language Models are Unsupervised Multitask Learners》,不像是之前的讲Pretrain+Finetune的论文,都只是套用了这个思路,然后实验说:哦这样很好,而没有一个理论层面的升华。
这篇GPT-2,笔者看下来,感觉对NLP领域中pretrain+finetune这一套流程为啥有用,又有了些不一样的认识。
笔者自己对于这个观点的理解就是:一般之前对于pretrain为何有用的解释都是猜测说,找到了一个很好的初始化点。这里是认为LM在学习的过程中,自然能学到那些有监督任务所需要的信息,即LM本身就是一个无监督的多任务学习者,也就能证明为何pretrain对后面的任务是有用的,即为何能找到一个很好的初始化点。更具体一些,论文中提到有监督的任务其实都只是语言模型序列中的一个子集,这里笔者脑补了一些例子,比如对于“The translation of apple in Chinese is 苹果”这个序列进行LM建模,自然能学到翻译的知识;对于“姚明的身高是2.26米”这个序列进行建模,自然能学到问答相关的知识,诸如此类。。
二. GPT-2原理
理解了上面的思路之后,就可以来看GPT-2的原理了,虽然原理上没有太多的创新。这里主要讲相比于GPT的改进点。
1. 数据集
作者从网上爬了一大堆语料,用来进行LM的pretrain,他们最后的数据集叫WebText,有800万左右的文档,40G的文本,并且还移除了Wikipedia的数据,因为后面要ZSL的任务里面有很多都是基于Wikipedia的语料的,这里其实就是保证了ZSL任务的前提。
PS:ZSL就是Zero-shot Learning。
2. 输入表征
对于输入的text不做任何的预处理(比如大小写转换啊,切分啊这种的),直接弄成bpe扔进去。
3. 模型
基本还是与GPT一致,但将LayerNorm移到了每层的输入,并且在最后一层attention后面加上了LayerNorm。同时在residual层初始化的时候,将其乘了 1 / N 1/\sqrt{N} 1/N,这里的N是residual的层数(这里没看懂?有大神看懂可以解答一下,residual不就是一个相加?哪里有参数?)。词表扩大到了50257。上下文长度从512扩展到1024;batchsize扩大到512。
三. 实验
作者用了几种不同size的模型,见下图:
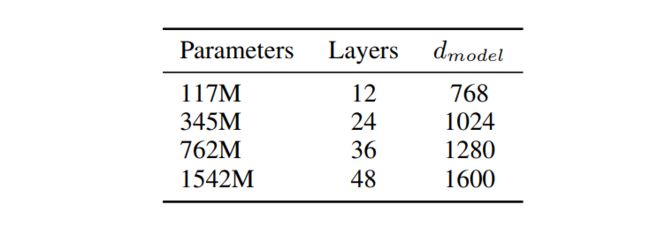
作者指出的是,最小的模型就是GPT,第二小的与大BERT是一个量级,最大的模型称为GPT-2。**所有的model,在LM训练的时候,都处于欠拟合的状态。**说明他们爬的这个大数据还是很好的!
作者直接将这个pretrain的模型,不用finetune的跑了各个下游的NLP任务,即ZSL设定,结果如下:
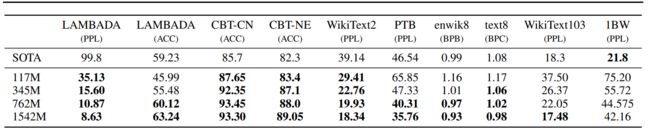
这里的WikiText2、PTB、enwiki8、text8、WikiText103、1BW是几个测试语言模型的数据集;LAMBADA是测试建模长句子能力的数据集,用于预测一句话的最后一个词;CBT是用于检验在不同类型的词上LM的表现,主要是Cloze任务。
作者还测试了一些其他的任务,比如推理的任务Winograd Schema Challange,结果如下:

还有阅读理解CoQA、摘要、翻译、QA等任务,比如摘要的结果:

最后,作者还给出了一个说明训练难度的表格,用于说明这些任务的训练集与测试集的文本重合度比较高,所以SoTA的效果要打一些折扣,而GPT-2这里用到的训练数据则与测试集重合度较低,所以就更能说明GPT-2的提升效果啦!

四. TensorFlow实现
看源码的意思,好像与GPT一样,也是没有放出pretrain的训练代码,而且在例子上也只是给出了文本续写的部分。但依然不影响笔者想一探究竟,那么这里就从pretrain的模型结构和文本续写的generate来讲吧。其实,按照GPT-2本身论文的侧重点,是想证明pretrain的LM就可以用ZSL完成其他的任务,因此,这里给出的这两部分源码其实对于实际应用来说也足够了!
1. 模型结构
在模型结构上,主体还是与GPT很像,都是transformer的decoder形式,只不过在规模上扩大了,其具体代码如下:
def model(hparams, X, past=None, scope='model', reuse=False):
with tf.variable_scope(scope, reuse=reuse):
results = {}
batch, sequence = shape_list(X)
# Embedding
wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.01))
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.02))
past_length = 0 if past is None else tf.shape(past)[-2]
h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length))
# Transformer
presents = []
pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer
assert len(pasts) == hparams.n_layer
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams)
presents.append(present)
results['present'] = tf.stack(presents, axis=1)
h = norm(h, 'ln_f')
# Language model loss. Do tokens
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])
logits = tf.matmul(h_flat, wte, transpose_b=True)
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab])
results['logits'] = logits
return results
代码整体还是很清晰的,一共分为三步:
- embedding层:这里的
wpe和wte分别代表的是position embedding和token embeeding。 - Transformer层:这里的核心仍然是
block这个函数,后面会细说。注意这里仍是没有传入长度的mask部分,这与之前GPT中的处理方式一样,还是很粗糙。 - 输出层:在得到了每个timestep的表示之后,就是熟悉的softmax层,这里仍然用了tie的策略,在映射到词表的时候,仍然使用的是之前token embedding的参数。
至于block部分,就是transformer的decoder部分,其实现方式如下:
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams)
x = x + a
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams)
x = x + m
return x, present
与GPT的主要不同就在于norm的地方不一样,GPT是在residual之后进行norm。
这里的两个细节实现attn和mlp如下:
def attn(x, scope, n_state, *, past, hparams):
assert x.shape.ndims == 3 # Should be [batch, sequence, features]
assert n_state % hparams.n_head == 0
if past is not None:
assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v]
def split_heads(x):
# From [batch, sequence, features] to [batch, heads, sequence, features]
return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3])
def merge_heads(x):
# Reverse of split_heads
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
def mask_attn_weights(w):
# w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst.
_, _, nd, ns = shape_list(w)
b = attention_mask(nd, ns, dtype=w.dtype)
b = tf.reshape(b, [1, 1, nd, ns])
w = w*b - tf.cast(1e10, w.dtype)*(1-b)
return w
def multihead_attn(q, k, v):
# q, k, v have shape [batch, heads, sequence, features]
w = tf.matmul(q, k, transpose_b=True)
w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype))
w = mask_attn_weights(w)
w = softmax(w)g
a = tf.matmul(w, v)
return a
with tf.variable_scope(scope):
c = conv1d(x, 'c_attn', n_state*3)
qg, k, v = map(split_heads, tf.split(c, 3, axis=2))
present = tf.stack([k, v], axis=1)
if past is not None:
pk, pv = tf.unstack(past, axis=1)
k = tf.concat([pk, k], axis=-2)
v = tf.concat([pv, v], axis=-2)
a = multihead_attn(q, k, v)
a = merge_heads(a)
a = conv1d(a, 'c_proj', n_state)
return a, present
def mlp(x, scope, n_state, *, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
h = gelu(conv1d(x, 'c_fc', n_state))
h2 = conv1d(h, 'c_proj', nx)
return h2
这里在feed forward里面仍然使用的是gelu激活函数。
2. 文本续写
这里其实主要是用的LM的自动生成下一个功能,主体的part就在于下面这个函数:
def body(past, prev, output):
next_outputs = step(hparams, prev[:, tf.newaxis], past=past)
logits = next_outputs['logits'][:, -1, :] / tf.to_float(temperature)
logits = top_k_logits(logits, k=top_k)
samples = tf.multinomial(logits, num_samples=1, output_dtype=tf.int32)
return [
tf.concat([past, next_outputs['presents']], axis=-2),
tf.squeeze(samples, axis=[1]),
tf.concat([output, samples], axis=1),
]
def step(hparams, tokens, past=None):
lm_output = model.model(hparams=hparams, X=tokens, past=past, reuse=tf.AUTO_REUSE)
logits = lm_output['logits'][:, :, :hparams.n_vocab]
presents = lm_output['present']
presents.set_shape(model.past_shape(hparams=hparams, batch_size=batch_size))
return {
'logits': logits,
'presents': presents,
}
可见其流程是:1. 根据当前的上下文生成下一个输出(step函数);2. 选择出Top-k的输出;3. 根据当前的概率分布采样一个作为下一个续写的输出。
五. 总结
优势
- 收集了一个大语料库WebText,即使像GPT-2这样的大模型,也依然处于欠拟合的状态
- 最大的GPT-2模型,有1.5B的参数量,用ZSL在很多任务上进行测试,发现有7/8的任务上都达到了SoTA。
- 给出了预训练好的参数,虽然只有TensorFlow的,但转成别的应该也不难
不足
- 没有放出pretrain的训练代码,并且finetune的部分也只列举了续写的部分
- 只给出了一个小的117M的预训练参数,可能是怕用于不正当用途吧,也可以理解
传送门
论文:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
源码:https://github.com/openai/gpt-2 (TensorFlow)
https://github.com/huggingface/pytorch-pretrained-BERT (PyTorch,虽然名字是BERT,里面也有GPT-2的实现)
官方blog:https://openai.com/blog/better-language-models/