0410--做出题更新blog
题目描述:calculator [web]
点开一个链接 是这样的

1、使用requests库:自动爬取 HTML 页面,自动网络请求提交,是网络数据爬取和网页解析的基本库,常用于网络爬虫与信息提取。
详:https://www.cnblogs.com/mzc1997/p/7813801.html
那么,从网站中爬取算式中的四个参数,计算完再提交回去就可以了。
2、代码:

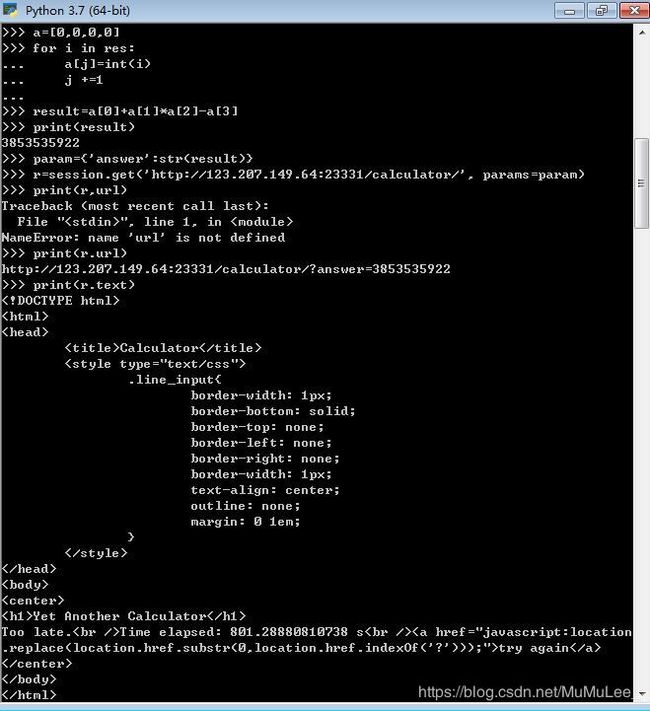
3、出问题的点:总是TooLate。
因为页面要求提交时间在1.5s以内
在cmd中运行计算的是从get(url)到提交param的时间
4、拟解决的办法:使用Pycharm,不用cmd。
4-1:之前在cmd中pip的:不能用了
原因:https://blog.csdn.net/sinat_23619409/article/details/79962518
4-2:另一种方法:
https://blog.csdn.net/kouyi5627/article/details/80531442 (里边写的方案一
File>>Settings>>Project Interpreter>>"+">>Install Package
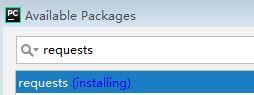
成功了会提示Successful
4-3:需要导入的包有两个:
requests和BeautifulSoup4(用于解析爬取网页中的参数)
导入后直接import就可以了
此处注意:BeautifulSoup版本4的包是在bs4中引入的
则import的时候要from bs4
看:https://www.cnblogs.com/zhangxinqi/p/9218395.html
4-4:再运行以上代码就不会timeout了
另外:Pycharm的循环语句自动缩进。
![]()
好评。