Python实用: 爬虫爬取学校教务个人课表
情境
用Python爬虫爬取学校教务网站上的个人课表, 并解析出课表内容进行初步显示
思路
-
爬取
-
登录教务网站
-
进入课表页获得改页源码
-
解析
需要用到的库有:
-
requests: 处理网络请求, 下载, 获得源码等 -
BeautifulSoup网页解析 -
Image: 打开显示验证码 (处理验证码的方法很多, 我这里用的是人工识别, 手工输入) -
re正则匹配
实现
爬取部分
登录到个人首页
-
查看学校网站源码获得几个必要的网址, 以及提交请求时需要哪些数据
-
登录页, 右键选择检查, 选择 network项, 勾选 preserve log 项.

-
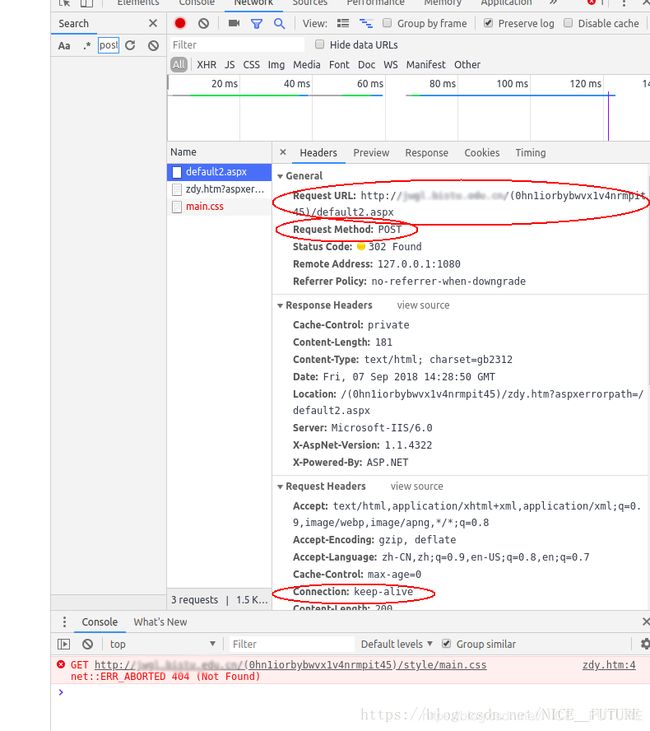
在浏览器尝试登录, 找到其中发出 post 请求的项. 查看并且分析其中的信息:
这里包括后面都是具体情况具体分析, 毕竟没有一劳永逸的爬虫 -
记下接受请求的网址
Request URL
--------这是网址 -
在request headers 中, 记下
Connection这个键值对, 记下Uset-Agent, 注意Referer的值
--------这是提交请求的heades部分 -
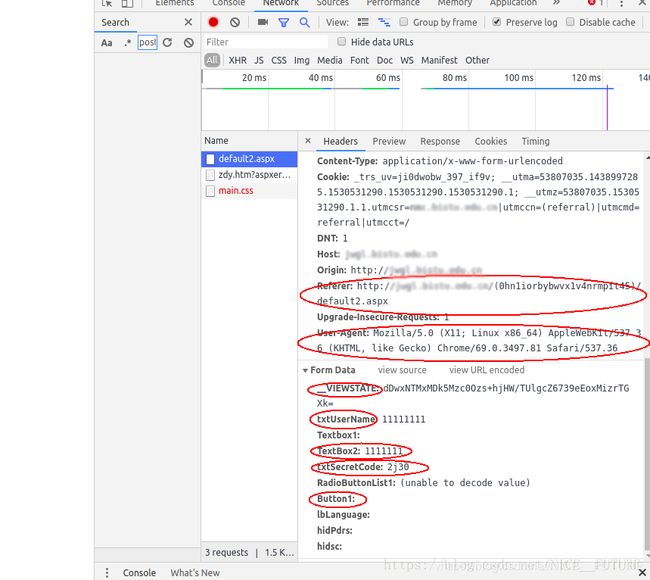
继续往下, 在
Form Data中, 有__VIEWSTATE这个长字符串能在登录页的源码中找到,txtUserName是用户名, 自己设定,TextBox2是密码, 自己设定,txtSecretCode是验证码, 后面手工输入,Button1对应的是登录按钮, 此处置空但不能少.
---------这是提交请求的data部分

-
回到登录页, 邮右键 查看网页源代码:
- 可以找到__VIEWSTATE的值, 解析源码即可获得
- 可以看到验证码的相对网址,requests请求下载保存到本地即可, 然后用Image库打开图片

-
用
BeautifulSoup解析登录页源码, 从用户处获得验证码, 将要提交的数据headers和data包装好, 发出 post 请求就正常登录了. 登录后拿到的源码就是个人教务首页的源码了
进入课表页
- 观察首页, 可以看到课表页需要另外跳转
![]()
- 类似上面步骤, 打开检查, 勾选
preserve log跳转到 点击跳转到课表页, 寻找拿到了课表信息的那一条请求 - 点击
doc进行筛选, 选中那一条请求, 点击response查看请求得到的代码, 发现是课程信息, 可以确定这条请求就是要找的请求

-
点击
headers, 查看请求详细信息 -
可以发现用的方法是 get , 记下
Request URL, 记下 Request Headers 中的Referer网址

-
用上面的信息, 发一次 get 请求就能拿到课表页的源码了
代码
class Crawling:
#public data
originURL = 'http://...' #作省略处理,实际即上文分析的 Request URL 的值
originHeaders = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
'Connection': 'keep-alive'} #记录headers, 伪装成浏览器访问. 'referer'的值要依据网页添加
checkcodePath = './code.png' #验证码保存路径
checkcodeURL = originURL+'CheckCode.aspx' #验证码网址
session = None #一个会话, 让cookie得以保存传递. 后面都使用这个session进行post和get.
#personal data
__originData = {'Button1':''} #登录时要提交的数据: 用户名, 密码, '__VIEWSTATE'的值要从登录页源码中提取, 'txtSecretCode'(验证码)的值要手工输入
def __init__(self, userName, passward):
self.__originData['txtUserName'] = userName
self.__originData['TextBox2'] = passward
self.session = requests.session()
def setData(self, pageSoup, headers):
data = self.__originData
data['__VIEWSTATE'] = pageSoup.findAll('input')[0].get('value') #解析得到'__VIEWSTATE'的值, 将'__VIEWDATE'的值加入字典
checkcode = self.session.get(self.checkcodeURL, headers=headers) #获得验证码网页
with open(self.checkcodePath, 'wb') as fp: #保存验证码图片
fp.write(checkcode.content)
checkcodeImg = Image.open(self.checkcodePath)
checkcodeImg.show() #展示验证码
data['txtSecretCode'] = input("请输入图片中的验证码: ") #获得手工输入的验证码, 将验证码加入数据字典中. 数据准备完毕
return data
def setHeaders(self, refererURL):
headers = self.originHeaders
headers['Referer'] = refererURL
return headers
def login(self):
loginPageURL = self.originURL+'default2.aspx' #登录的网址(post请求网址, 同时也是referer网址)
loginPageCode = self.session.get(loginPageURL, headers=self.originHeaders).text #进入登录页, 保存登录页源码
loginPageSoup = BeautifulSoup(loginPageCode, 'lxml') #登录页源码传入解析器解析
loginData = self.setData(loginPageSoup, self.originHeaders) #得到post需要的data
loginHeaders = self.setHeaders(loginPageURL) #得到post需要的headers
homePage = self.session.post(loginPageURL, data=loginData, headers=loginHeaders) #发出post请求(登录), 进入个人教务系统主页
return homePage
def switchToSchedule(self, homePage):
homePageURL = self.originURL+'xs_main.aspx?xh='+self.__originData['txtUserName'] #主页网址(referer网址)
homePageSoup = BeautifulSoup(homePage.text, 'lxml') #解析主页源码
targetURL = homePageSoup.findAll('a')[18].get('href') #得到课表页网址, 其中有中文待处理
name = re.search(r'[\u4e00-\u9fa5]{2,}', targetURL).group() #正则匹配到中文
nameInURL = str(name.encode('gb2312')).replace('\\x', '%').upper()[2:-1] #将中文转换为地址
classPageURL = self.originURL+'xskbcx.aspx?xh='+self.__originData['txtUserName']+'&xm='+nameInURL+'&gnmkdm=N121603' #得到课表页数据来源网址(get请求网址)
classPageHeaders = self.setHeaders(homePageURL) #得到get需要的headers
classPage = self.session.get(classPageURL, headers=classPageHeaders) #发出get请求,得到课表页数据
return classPage
解析部分
- 用
BeautifulSoup和 正则表达式 解析网页, 拿到课程的信息
代码:
class ResolvePage:
soup = None
schedule = [] #存放课表
scheduleTime = [] #存放当前学年学期, 索引0为学年, 索引1为学期
def __init__(self, pageCode): #pageCode可以是爬取的源码也可以是源码的文件句柄
self.soup = BeautifulSoup(pageCode, 'lxml')
def getSchedule(self):
return self.schedule
def getScheduleYear(self):
return self.scheduleTime[0]
def getScheduleSemester(self):
return self.scheduleTime[1]
def resolveScheduleTime(self): #获得课表所在学年与学期
for option in self.soup.findAll('option'):
if option.get('selected') == 'selected':
self.scheduleTime.append(option.get('value'))
def resolveScheduleContent(self):
classes = []
#取下包含了课表内容的源码
rows = self.soup.findAll('tr')[4:17]
for row in rows:
columns = row.findAll('td')
for column in columns:
if column.get('align') == 'Center' and column.text != '\xa0':
classes.append(str(column))
#去除无用部分,留下<\br>用来分隔各项
for i in range(len(classes)):
index = classes[i].find('>')+1
classes[i] = classes[i][index:-5]
#合为一个字符串
classes = '
'.join(classes)
#按分隔符拆开为列表
classes =re.split(r'
|
', classes) #按正则表达式分割, | 为或, 遵循短路原则, 所以 | 两边顺序不可变换
#按科目拆开
subject = []
for i in range(len(classes)):
subject.append(classes[i])
if (i+1)%5 == 0:
self.schedule.append(subject)
subject = []
效果
效果图没有输用户名密码的步骤, 因为录gif图的时候暂时将信息写进了代码里

更新补充
第二天增加了对个人成绩的爬取, 调整了代码结构, 使用了第三方库 prettytable 让爬取的课表和成绩打印的很漂亮
如图:
[成绩截图省略]
