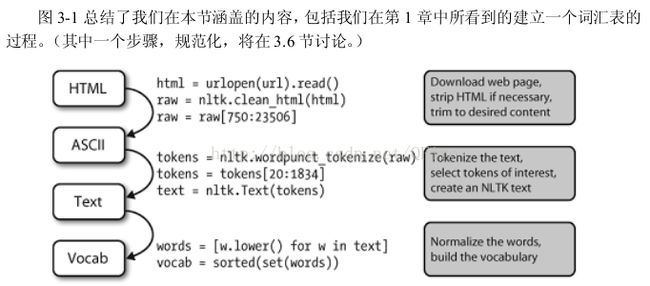
Python自然语言处理 3 处理原始文本
本章的目的是要回答下列问题:
(1) 怎样才能编写程序访问本地和网络上的文件,从而获得无限的语言材料?
(2)如何把文档分割成单独的单词和标点符号,并进行文本语料上分析?
(3)怎样编写程序产生格式化的输出,并把结果保存在文件中?
为了解决这些问题,本章将介绍NLP的重要概念,包括分词和词干提取.在过程中,巩固Python知识并且学习关于字符串,文件和正则表达式的知识.网络上的文本都是HTML格式的,我们将学习如何使用HTML
一,从网络和硬盘访问文本
#处理电子书 txt
古腾堡项目http://www.gutenberg.org/catalog/有25000本免费在线书籍的目录
编号2554的文本是<罪与罚>
from urllib import urlopen
url = "http://www.gutenberg.org/files/2554/2554-0.txt"
raw = urlopen(url).read()
type(raw)
str
len(raw)
1201733
raw = raw.replace('\xef\xbb\xbf','')
raw[:75]
'The Project Gutenberg EBook of Crime and Punishment, by Fyodor Dostoevsky\r\n\'分词
import nltk
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
tokens = nltk.word_tokenize(raw)
type(tokens)
listlen(tokens)
244761tokens[:15]
['\xef', '\xbb', '\xbfThe', 'Project', 'Gutenberg'
在链表中创建NLTK文本
text = nltk.Text(tokens)
type(text)
text[1020:1060]
text.collocations()
raw.find("PART I")
5381raw.rfind("End of Project Gutenberg’s Crime")
1182515raw = raw[5381:1182515]
raw.find("PART I")
0
#处理HTML
url = "http://news.bbc.co.uk/2/hi/health/2284783.stm"
html = urlopen(url).read()
html[:60]
' #raw = nltk.clean_html(html)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
raw = soup.get_text()tokens = nltk.word_tokenize(raw)
tokens
[u'BBC', u'NEWS', u'|', u'Health', u'|',#处理搜索引擎的结果
网络可以被看做未经标注的巨大语料库
#处理RSS订阅
http://feedparser.org
#读取本地文件
import sys
#从PDF,MS word及其他二进制格式中提取文本
使用pypdf和pywin32
#捕获用户输入
s = raw_input("Enter some text: ")
#NLP的流程
二, 字符串: 最底层的文本处理
#链表与字符串的差异
字符串和链表都是一种序列.可以通过索引抽取它们中的一部分,可以给它们切片,也可以使用连接将它们合并在一起,但是,字符串和链表之间不能连接
query = 'Who knows?'
beatles = ['John', 'Paul', 'George', 'Ringo']
query[0] = 'F' #不可变
beatles[0] = 'F' #可变的
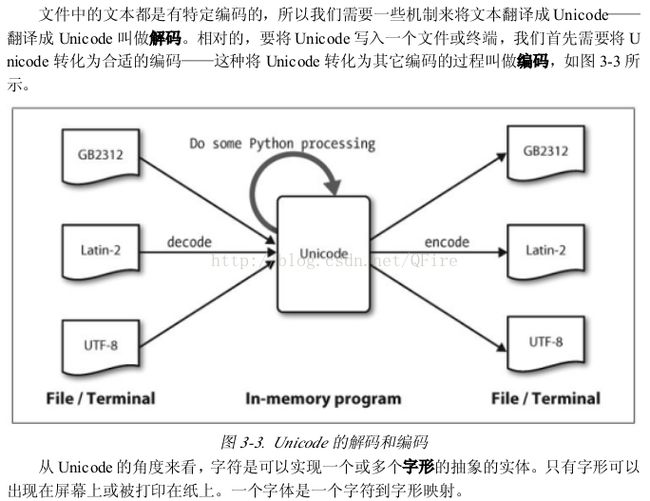
三, 使用Unicode进行文字处理
#从文件中提取已编码文本
import codecs
f = codecs.open(path, encoding='utf8')
四 使用正则表达式检测词组搭配
五 正则表达式的有益应用
#提取字符块
找出文本中两个或两个以上的元音序列,并确定它们的相对频率
import re wsj = sorted(set(nltk.corpus.treebank.words())) fd = nltk.FreqDist(vs for word in wsj for vs in re.findall(r'[aeiou]{2,}', word)) fd.items()#在字符块上做更多事情
#查找词干
查询"laptops"会找到含有"laptop"的文档
def stem(word):
for suffix in ['ing','ly','ed','ious','ies','ive','es','s','ment']:
if word.endswith(suffix):
return word[:-len(suffix)]
return word使用正则表达式
#搜索已分词文本
这种自动和人工处理相结合的方式是最常见的建造新语料库的方式
六 规范化文本
raw = """DENNIS:Listen, strange women lying in ponds distributing swords is no basis for a system of government. Supreme executive power derives from a mandate from the masses, not from some farcical aquatic ceremony."""
tokens = nltk.word_tokenize(raw)
#词干提取器
porter = nltk.PorterStemmer() lancaster = nltk.LancasterStemmer() [porter.stem(t) for t in tokens] [u'denni', ':', 'listen', ',', u'strang',
#词形归并wnl = nltk.WordNetLemmatizer() [wnl.lemmatize(t) for t in tokens] ['DENNIS', ':', 'Listen', ',', 'strange', u'woman', 'lying',七 用正则表达式为文本分词
#分词的简单方法
re.split(r" ', raw) #在空格符处分割原始文本
re.split(r'[ \t\n]+', raw) #同时需要匹配任何数量的空格符\制表符或换行符
八 分割
#断句
sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle') text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt') sents = sent_tokenizer.tokenize(text) pprint.pprint(sents[171:181])#分词
九 格式化:从链表到字符串
#从链表到字符串
silly = ['We','called','him','Tortoise','because','he','taught','us','.'] ' '.join(silly) 'We called him Tortoise because he taught us .' ';'.join(silly) 'We;called;him;Tortoise;because;he;taught;us;.' ''.join(silly) 'WecalledhimTortoisebecausehetaughtus.'
十 深入阅读