SVM的一些学习心得及案例(Python代码)实现
1、基本概念
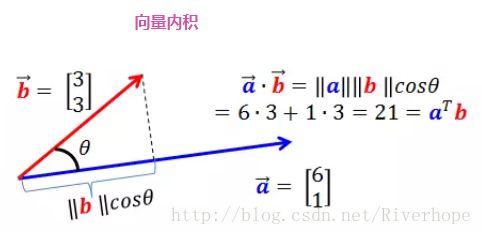
向量的内积即一个向量在另一个向量上的投影乘上被投影向量的模,上图不管是a投影在b上,还是b投影在a上,其结果是一样的,原理参照 B站上 3Blue1Brown
a∙b = (a1e1 + a2e2)∙(b1e1 + b2e2)
= a1b1e1e1 + a1b2e1e2
+ a2b1e2e1 + a2b2e2e2
= a1b1 + a2b2
=aTb
对于一个超平面,其方程为 wTx + b = 0 (二维的超平面就是线,而线的方程为ax + by + c = 0 ),
假设A、B两点在wTx + b = 0上
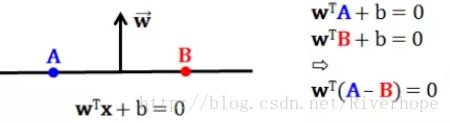
那么向量 w 垂直于这个超平面。
2、线性可分支持向量机

假设对于如图所示的训练集,我们怎么去寻找它的超平面呢?
无数条直线可以表示为wTx(i)+ b,我们要做的就是在这么多条的直线中找到一条比较好的超平面
因此首先需要求出所有样本点到直线的距离d=|wTx(i)+ b| / ||w||,而如果我们定义实心点为正例+1,空心点为负例-1
由于 g(x(i)) = sign(wTx(i) + b),那么当
-
wTx(i) + b > 0,将其分为正例,y(i) = 1
-
wTx(i) + b < 0,将其分为反例,y(i) = -1
-
根据上面两种情况,关系式 y(i)(wTx(i) + b) > 0 永远成立
d可写为d=y(i)(wTx(i)+ b) / ||w|| 即可以把绝对值去掉。
1)需所有的样本点到直线的距离最短 min y(i)(wTx(i)+ b) / ||w|| (保证 直线中找到一条比较好的超平面)
2) 在1)的前提下,选出一条最大值max min y(i)(wTx(i)+ b) / ||w|| (保证间隔最大)
目标函数为
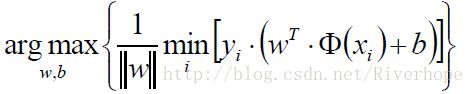
现在有个问题,当 w 和 b 变成它们原来 0.01 倍或者 1000 倍时, wTx + b = 0 代表的是同样的超平面,展示如下:
wTx + b = 0
0.01wTx + 0.01b = 0
1000wTx + 1000b = 0
即我们在后面解出唯一的解时,可以缩放权重w和偏差b的比例.
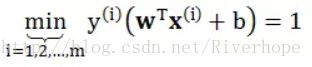
证:

最终目标函数变为:
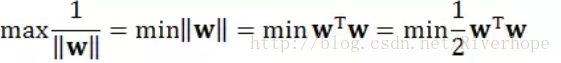
上面连等式第一步是因为最大化一个正函数就是最小化它的倒数;第二步是用了 ||w|| 的定义;第三步纯粹是为了之后求导数容易,而且最小化一个函数跟最小化它的一半是完全等价的。
在 SVM 问题中,我们不但希望要最大化 margin,还希望每个点都有分类正确,因为我们要解决下面优化问题
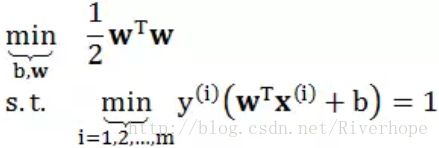
到此问题已经非常简单了,目标函数是个二次凸函数,非常适合做优化;但是限制条件里面有 min 出现,给优化问题造成了难度。因此我们将这一个带 min 的限制条件转换成 m 个“更松”的限制条件,如下
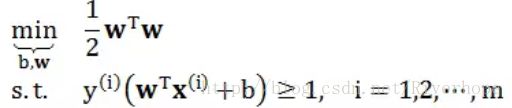
由限制条件可知,该问题是找一个超平面,线性分割所有点并使它们完全分类正确,
这种超平面称为线性硬分隔支撑向量机 (hard-margin SVM)
简单的例子
二维问题来求解上面的原始问题
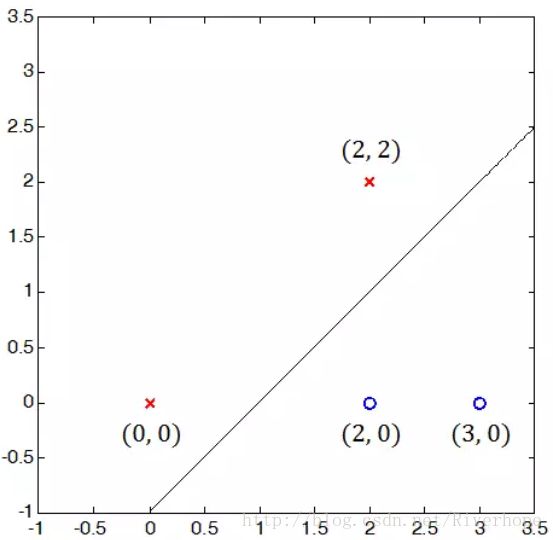
根据这个四个点展开限制条件得到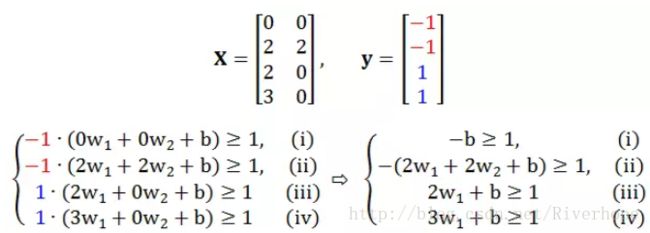
根据 (i) 和 (iii) 解得 w1 ≥ 1,根据 (ii) 和 (iii) 解得 w2 ≤ -1,这意味着目标函数

最小值在 w1 = 1 和 w2 = -1 时得到,很容易解得 b = -1。最优分割超平面在下图展示:
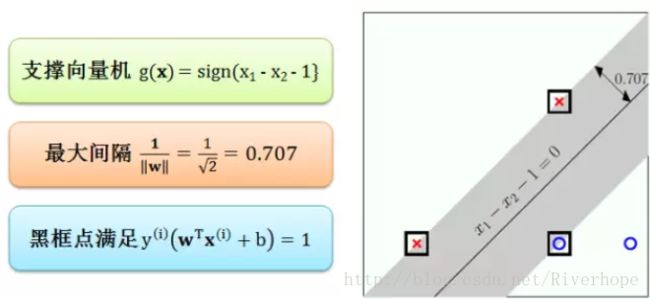
对那些刚好满足限制条件的点,他们到超平面的距离都等于 1/||w||。这些点也都在灰色缓冲带的边界上,称为支撑向量 (support vector),顾名思义,这些向量支撑着缓冲带,防止它继续向外展开。
软间隔 SVM 原始问题
硬间隔 SVM 要求所有得数据都要分类正确,在此前提下再最小化 wTw,但是现实中这种事情很少发生 (即没有这样一个完美的数据让你所有分类正确)。那么你要放弃这个问题,还是要试试另外一种方法,即软间隔 SVM?
软间隔 SVM 就是为了缓解“找不到完美分类数据”的问题,它会容忍一些错误的发生,将发生错误的情况加入到目标函数之中,希望能得到一个错分类情况越少越好的结果。为了能一目了然发现硬间隔和软间隔 SVM 原始问题之间的相似和不同之处 (红色标示),将它们的类比形式展示在下表:

由上发现硬间隔和软间隔 SVM 的区别就是后者多了 ξ 和 C,参数ξ是衡量数据犯了多大的错误,而不是数据犯了几个错误。为了简化令 ui = y(i)(wTx(i) + b):
-
当 ξi = 0 时,该点没有违规而且分类正确,因为 ui ≥ 1,该点离分隔线距离大于等于 margin
-
当 0 < ξi ≤ 1 时,该点违规了但还是分类正确,因为 ui 大于“一个小于1”的正数,该点离分隔线距离小于 margin
-
当 ξi > 1 时,该点违规了并分类错误,因为 ui 大于一个负数 (ui 可能小于0),我们知道只有 ui > 0 是分类正确
上述讨论情况在下图中展示
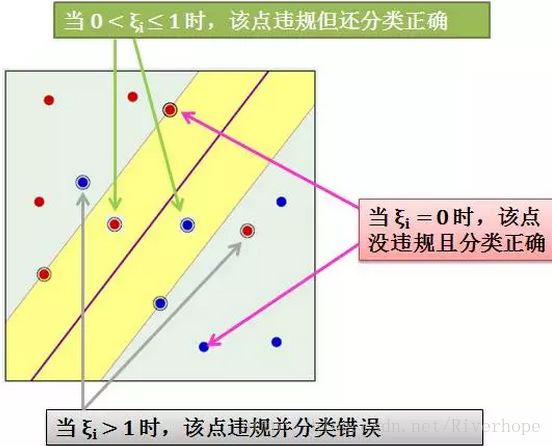
总结来说,用 松弛变量ξ 来记录违规数据距离边界的距离,并将这个距离纳入到最佳化的标准里面。但是我们不希望 ξ 太大,因为这意味着有某个数据分类错的太离谱,因此需要用 C 来惩罚太大的ξ。参数 C 控制“到底要多大的边界”还是“更加在意违反边界的情形越少越好”。(调参会用到)
-
越大的 C 代表,宁可边界窄一点,也要违规 (甚至出错) 数据少点
-
越小的 C 代表,宁可边界宽一点,即便牺牲分类精度也无所谓
部分数据

代码:
import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt from sklearn import svm from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score if __name__ == "__main__": iris_feature = '花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度' path = 'E:\\machine learning\\code\\11.RandomForest\\iris.data' # 数据文件路径 data = pd.read_csv(path, header=None) x, y = data[[0, 1]], pd.Categorical(data[4]).codes #即x为iris.data里的第一二列,y为iris.data里的第5列;pd.Categorical对花的类别进行编码 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6) # 分类器 # clf = svm.SVC(C=0.1, kernel='linear', decision_function_shape='ovr') #ovr one vs rest clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr') clf.fit(x_train, y_train.ravel())
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
kernel='linear'时,为线性核,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
kernel='rbf'时(default),为高斯核,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
decision_function_shape='ovr'时,为one v rest,即一个类别与其他类别进行划分,
decision_function_shape='ovo'时,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
# 准确率 print(clf.score(x_train, y_train)) # 精度 print('训练集准确率:', accuracy_score(y_train, clf.predict(x_train))) print(clf.score(x_test, y_test)) print('测试集准确率:', accuracy_score(y_test, clf.predict(x_test)))如果想查看决策函数,可以通过decision_function()实现
# decision_function print(x_train[:5]) print('decision_function:\n', clf.decision_function(x_train)) print('\npredict:\n', clf.predict(x_train))
绘制图像
1.确定坐标轴范围,x,y轴分别表示两个特征
# 画图 x1_min, x2_min = x.min() x1_max, x2_max = x.max() x1, x2 = np.mgrid[x1_min:x1_max:500j, x2_min:x2_max:500j] # 生成网格采样点 grid_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点 grid_hat = clf.predict(grid_test) # 预测分类值 grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同2.指定默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] = False3.绘制
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF']) cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) plt.figure(facecolor='w') plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light) plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本 plt.xlabel(iris_feature[0], fontsize=13) plt.ylabel(iris_feature[1], fontsize=13) plt.xlim(x1_min, x1_max) plt.ylim(x2_min, x2_max) plt.title('鸢尾花SVM二特征分类', fontsize=16) plt.grid(b=True, ls=':') plt.tight_layout(pad=1.5) plt.show()
pcolormesh(x,y,z,cmap)这里参数代入x1,x2,grid_hat,cmap=cm_light绘制的是背景。
scatter中edgecolors是指描绘点的边缘色彩,s指描绘点的大小,cmap指点的颜色。
xlim指图的边界。
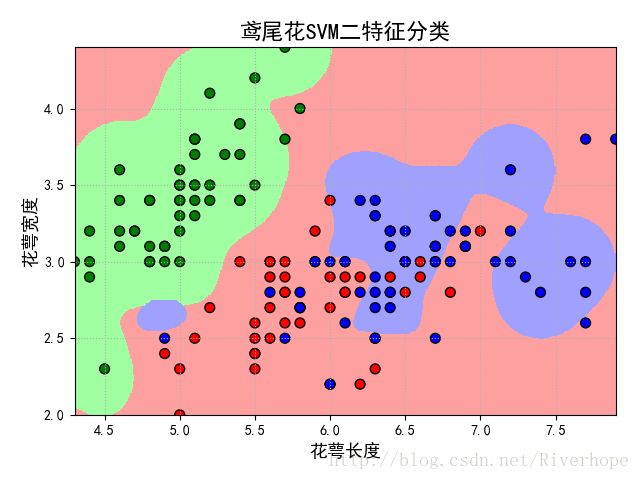
结果为:0.866666666667
训练集准确率: 0.8666e=
6666667
0.65
测试集准确率: 0.65
decision_function:
[[ 2.45540648 0.80337522 -0.2587817 ]
[-0.4368348 2.31950945 1.11732536]
[-0.43793789 1.00917055 2.42876733]
[ 2.45555373 0.80242493 -0.25797866]
[ 2.46185007 0.80020899 -0.26205906]
[-0.4275673 0.97215049 2.4554168 ]
[ 2.4554096 0.80344613 -0.25885573]
[-0.42578192 2.23549613 1.19028579]
[-0.33298947 0.85928729 2.47370219]
predict:
[0 1 2 0 0 2 0 1 2 2 1 2 1 0 1 2 2 1 2 1 0 0 0 2 0 1 2 1 0 0 1 0 2 1 2 2 1
2 2 1 0 1 0 1 1 0 1 0 0 2 1 2 0 0 1 0 1 0 2 1 0 2 0 1 0 1 1 0 0 1 0 1 1 0
2 1 1 1 1 0 0 1 1 2 1 2 2 1 2 0]
============================================
本文是阅读邹博机器学习升级版SVM与微信公众号——【王的机器】SVM之后,结合两文写出的一些心得,
但并未完全弄懂,相应知识点以后查缺补漏后再行补充。