高考填志愿的上亿流量高峰,看 MongoDB 如何应对
随着用户规模的增长,数据库的压力也在成倍增加。面对大流量、高并发,UCloud MongoDB 做到了高效,并展现出了更好的性能体验。
—— 优志愿 CTO 张海鹏
背景
每年 6 月下旬到 8 月下旬期间是高考填志愿的高峰期,也是优志愿后端面临大流量高并发请求的业务高峰期。优志愿 APP 旨在为 3000 万高中生提供专业的自主招生、志愿填报、留学、游学等升学规划服务,通过四年技术的不断创新和研发,凭借 “省控线差值法” 等专利级核心算法,目前已累计服务 400 多万考生,实现录取成功率高达 99.2%,最大浪费分仅 6 分的成绩。而要为如此多考生提供服务,面对上亿条检索依然稳定,并不是简单的事。

面临的痛点
优志愿原先基于物理机自建的 MSSQL(Microsoft SQL Sever)数据库,面对大流量高并发的业务高峰,暴露了以下问题:
1. 跟不上业务弹性扩容的节奏
自建 MSSQL 在做读写分离、AlwaysOn 配置、给每台 windows 客户端配置域名帐户等操作时十分繁琐,且随着业务流量的增长需要不定时的增加服务器及应用配置,从硬件采购、机器部署到应用配置整个周期也较长。
2. 性能遭遇瓶颈,DBA 耗时耗力
另外,由于优志愿的业务场景主要是以查询、索引操作为主,读写比例大概 7:3,之前自建的 MSSQL 在数据达到千万条时检索速度大幅下降,需要及时更新索引目录,不仅影响考生的用户体验,且耗费大量的 DBA 人力成本。
经过一番调研对比后,优志愿选择了使用 UCloud MongoDB 产品来解决以上问题。
为什么选择 UCloud MongoDB?
UCloud MongoDB 是基于成熟云计算技术的高可用、高性能的数据库服务,无缝兼容开源的 MongoDB 版本;除了底层采用高可用主从架构外,还提供满足数据分片场景的配置节点和路由节点功能;同时提供灾备、备份、监控等全套解决方案。

(图:在 UCloud 控制台 UDB 产品界面可选择创建 MongoDB 实例)
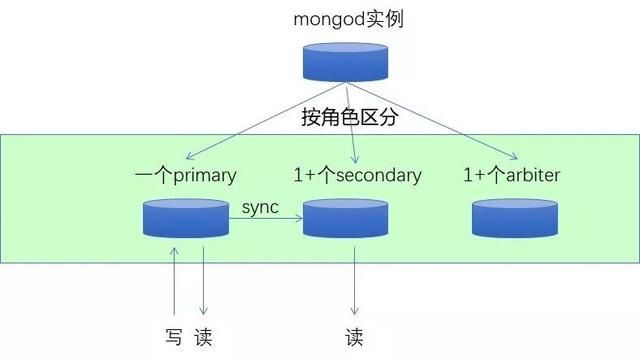
●一键创建副本集实现读写分离
UCloud MongoDB 默认构建三节点的副本集:Primary 节点 + 一个 Secondary 节点 + 一个 Arbiter 节点构成。通过副本集中创建节点操作可支持扩展更多节点的副本集(例如:五节点、七节点或者更多个节点)。对于优志愿读多写少的场景及其业务高峰期,用户可以按需增删 Secondary 节点,更好地实现读取性能的扩展。利用 UCloud MongoDB 副本集读写分离解决了大部分读取的请求,即使数据到达上亿条时检索速度依然很快。副本集架构如图所示:
●灵活高可用集群架构
为了解决随着数据量增多而导致的性能瓶颈,MongoDB 还支持分片集群,即多个分片可以组成一个集群对外提供服务。分片集群(MongoDB3.4 及以上版本),由 Config Server 三副本 + N 个 Mongos +N 个 shard 数据分片构成,MongoDB 集群设置好分片规则,通过 mongos 操作数据库就能自动把对应的数据操作请求转发到对应的分片机器上。MongoDB 采用 “分片” 能够快速搭建一个高可用可扩展的的分布式集群,具有大数据量、高扩展性、高性能、灵活数据模型、高可用性等特性。分片集群架构如图:

●弹性扩缩容更省成本
用户依据业务实际流量可以弹性扩展 MongoDB 资源,满足不同业务阶段数据库性能和存储空间的需求。在业务高峰期可即时开通所需数据库资源,无需在业务初期采购高成本硬件,从而有效减少硬件成本投入。在业务低峰期可随时删除释放,避免数据库资源的闲置浪费。正如优志愿 CTO 张海鹏所说:“使用 UCloud MongoDB 数据库后,运维成本节省了 80%,硬件采购成本减少 55%。”
查询索引优化,打破性能瓶颈
卡顿现象
在今年高考前夕,优志愿新版业务上线后业务出现小高峰的第一天,用户反馈他们的 APP 登陆界面非常卡顿,经运维排查发现瓶颈出现在数据库层,并邀请了 UCloud 云数据库团队介入解决相关性能问题。
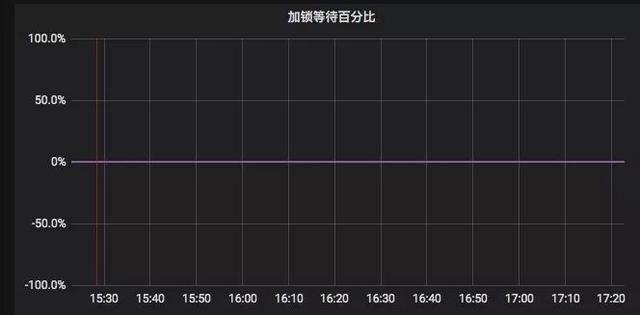
团队首先查看了一些常见的会引起 MongoDB 出现卡顿的性能指标,发现大多数指标正常。随着排查深入进行,发现实例全局写锁的加锁比例异常高。如下图所示。


图中加锁百分比达到 100%,意味着所有全局写操作全部卡住,大量的请求在排队等待加锁,性能急剧下降。
语句优化
UCloud 云数据库团队针对当时用户所有慢查询的总体情况,以及相关慢查询的查询计划,并结合用户的索引情况进行了详细分析。经过分析后,团队首先发现用户的相关表当中一些索引可以优化,从而提升查询的效率,因此为用户添加了相关的索引。在添加了索引之后,团队结合监控指标,发现情况有所改善,但是依旧没有从根本上解决问题。
然后,团队仔细分析了用户耗时最长的典型查询语句,并模拟执行查看执行计划。在执行过程中,团队发现虽然相关集合已经加上了索引,但是用户的查询语句的执行计划中并没有使用最优的索引。进一步分析后,团队发现用户的最慢的语句基本都是 aggregate 操作,结合加锁异常的性能指标,团队仔细查看了用户的具体 aggregate 的语句内容。最后发现耗时长的这些 aggregate 操作当中没有用到分组功能 ($group)。这样的话其实也可以通过 MongoDB 最普通的 find 操作来达到同样的效果。例如原语句:
db.this_collection.aggregate([ {$match: { UserId: 12345}}, {$match: { $or: [{FieldA: 1}, {FieldB: 2}]}}, {$sort: {_id: -1}}, {$skip: 0}, {$limit: 1}])
这条语句做的事情,其实是在 this_collection 这个集合中,查找 UserId = 12345 并且 还满足 FieldA = 1 或者 FieldB = 2 的文档记录。查找到记录之后,对所有结果的_id 进行倒序排列,并且拿出第一条结果。团队用下面的 find 语句达到同样的效果。改造后语句:
db.this_collection.find( { UserId: 12345, {$or: [{FieldA: 1}, {FieldB: 2}]} }).sort({_id: -1}).skip(0).limit(1)
MongoDB 的 find () 进行了更加高程度的查询优化,并且使用 find () 操作还有一个额外的好处,就是用户可以在 find () 最后接上 hint () 操作,可以强制指定使用的索引,使查询性能大幅提升。比如上面的例子中,如果在 this_collection 这个集合中,对 UserId 有索引,我们可以直接强制查询使用这个索引。具体语句可以变成:
db.this_collection.find( { UserId: 12345, {$or: [{FieldA: 1}, {FieldB: 2}]} }).sort({_id: -1}).skip(0).limit(1).hint({UserId: 1})
团队尝试改造其中的一条典型耗时语句,并且在模拟环境中执行并查看改造后的执行计划。结果惊喜地发现,即使在没有使用 hint 操作的情况下,find () 操作已经能够使用我们认为的最优索引了,经过改造后的查询性能有了大幅的提升。
当天晚上,UCloud 云数据库团队立即帮助用户改造了他们最慢的查询中所有可以被改造的查询语句,并且把改造建议同步给用户。用户的研发当晚收到改造建议后,紧急修改代码并发布。
瓶颈解除
发布后的第二天,用户通过监控界面,可以看到慢查询显著减少,并且加锁队列显著降低,数据库的负载也明显降低,整个系统能更高效的提供服务,改造后的监控图如下:
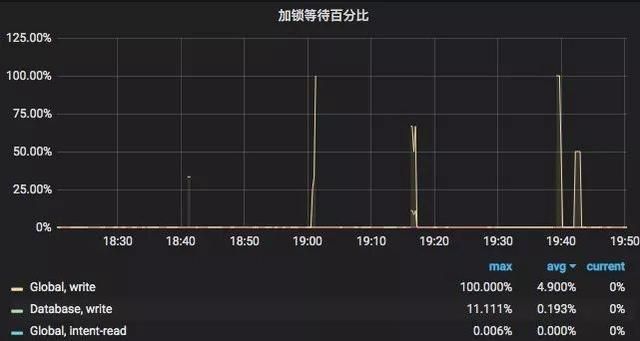
可以看到,在改造之后,全局写锁的加锁等待百分比大大减少,慢查询也大大减少。改造取得了非常好的效果,用户的 APP 后期再也没有出现过 DB 层面的性能瓶颈。
Prometheus 全方位实时监控及告警
为了帮助用户提供更实时的大盘监控,UCloud 在后台搭建了一套 Prometheus 监控系统,将所有数据库实例的关键性能指标全列出来,相比普通的监控平台,借助 Prometheus 可以更清晰的看到所有数据库实例当前的情况,掌握数据库当前的状态,也可以更好的发现数据库的运行趋势。
例如连接数情况:

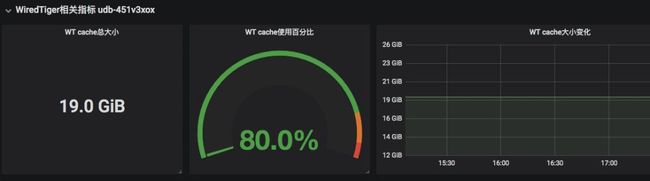
对于每一个实例,提供更详细的监控。例如 WTcache 的状态:
加锁的状态:
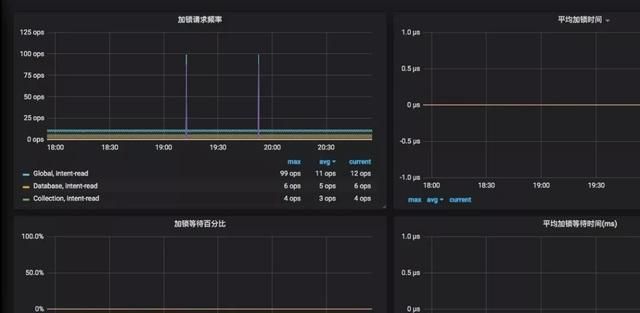
监控系统和告警系统相结合,可以在大于阀值时,直接告警出来,有利于问题的提前发现。借助 UCloud 搭建的 Prometheus ,用户无需自行搭建监控系统,也无需关心底层数据存储、数据展示、系统运维等问题。
写在最后
UCloud 云数据库 UDB 自 2013 年正式商用后,一直紧跟开源社区的步伐,目前已经广泛支持业内主流的数据库类型,除了 MongoDB, 还支持例如 MySQL、PostgreSQL 以及 SQLServer。在开源的基础上,UCloud 数据库团队还自研了分布式架构、读写分离、存储计算分离等特性。同时,为了更贴近用户的使用场景,UCloud 数据库团队近期将推出 Cloud DBA 新产品,在控制台提供 Prometheus 监控入口、界面管理巡检和 SQL 分析等功能,以更加智能的方式提高 DBA 运维效率。
![]()
