GreenDao详解
- 简介
- Dao代码生成
- 会话(Sessions)
- GreenDao操作
- 数据库升级
简介

GreenDao是为android设计的对象关系映射(ORM)工具。它提供了对象到关系型数据库SQLite的相应接口。
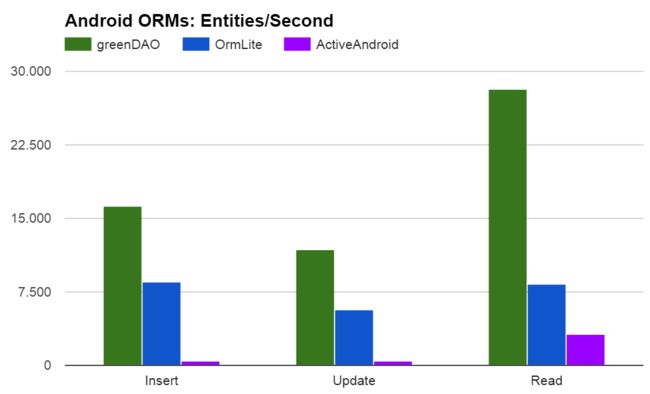
它不仅使用方便,性能也很出众,当前主流ORM框架性能比较如下:
Dao代码生成
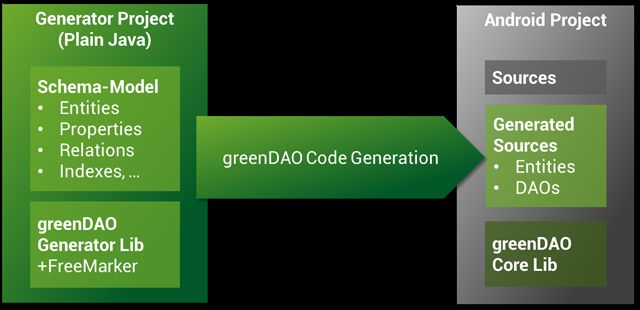
“生成器”工程
为了在Android工程中使用greenDao,需要创建另一个“生成器”工程,它的任务是在你的工程域里生成具体的代码。
这个“生成器”工程是一个正常的Java工程。“生成器”工程中需要在classpath中引入greenDAO-generator.jar和freemarker.jar两个jar包。
生成的核心类文件

DaoMaster:使用greenDao的入口,DaoMaster持有数据库对象(SQLiteDatabase)并为特定的模式管理Dao类。其中有创建和销毁表的静态方法。它的内部类OpenHelper 和DevOpenHelper是SQLiteOpenHelper 的实现,用来在SQLite数据库中创建模式。
DaoSession:为具体的模式管理所有可获得的Dao对象,该对象可以通过其中的get方法获得。DaoSession一些基础的方法,比如对实体的插入,加载,更新,刷新和删除等。DaoSession对象也保持了身份范围的追踪。
DAOs:数据访问对象(DAOs)用来操作实体。对于每一个实体,greenDao生成一个Dao。它比DaoSession有更多操作数据库的方法。
Entities:持久化对象。通常,实体被生成,实体对象相当于数据库的一行。
构建实体
使用greenDao的第一步就是在工程中创建代表应用程序中使用的数据的实体模型。这个模型用Java代码,在“生成器”工程中定义。
下图描画了元数据模型:
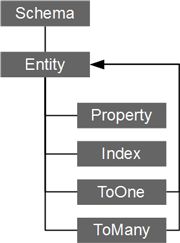
使用图中的类来描述你所需要的具体的模型。
模式
实体属于一个模式。模式是你定义的第一个对象。
Schema schema = new Schema(1, "de.greenrobot.daoexample");模式的构造函数,需要两个参数:
- 模式版本号:
- 默认的Java包名:这个默认包名在greenDao生成实体,DAOs和执行JUnit测试时使用。
如果想将DAO和用于测试的类生成在两个分隔的包中,可以通过一下方法设置:
schema.setDefaultJavaPackageTest("de.greenrobot.daoexample.test");
schema.setDefaultJavaPackageDao("de.greenrobot.daoexample.dao");对实体模式还有两个默认的标志,它们可以被覆写。这些标志说明实体是否是激活的和是否保持章节字段可用。
schema2.enableKeepSectionsByDefault();
schema2.enableActiveEntitiesByDefault();实体
当有了模式对象,就可以向其中添加实体了。
Entity user = schema.addEntity("User");实体可以更改少数的几项设置,更重要的是可以在其中添加属性。
user.addIdProperty();
user.addStringProperty("name");
user.addStringProperty("password");
user.addIntProperty("yearOfBirth");每一个属性对应生成对象中的一个字段,同时对应着数据库中的一列。
属性和主码
实体的addXXXProperty方法返回一个PropertyBuilder对象,它可以被用来配置属性,例如用它来更改默认的列名。为了访问属性对象(不是基本变量)需要在PropertyBuilder对象上使用getProperty()方法创建索引和关系。
私有key的限制:现在,实体必须有一个long或Long的属性作为私有key。这是被Android和SQLite推荐的实践(也可以使用唯一的字段作为“key”属性,只是不被推荐)。
默认
greenDao尽量使其能工作在默认情况下。例如数据库表名和列名是源于实体和属性名的。默认的数据库名是大写并使用下划线来分隔单词。例如,一个属性为“creationDate”将变成一个名为“CREATION_DATE”的数据库列名。
关系
数据库表间有1:1,1:n或m:n的关系。
在greenDao中,实体关系使用to-one或者to-many关系。如果你想在greenDao中做一个1:n关系的模型,则你要有一个to-one和一个to-many关系。注意to-one和to-many关系相互之间是没有联系的,所以你需要两个同时升级。
关系名称和复合关系(Relation Names and multiple Relations)
每一个关系都有名字,它被用来在生成的实体中保持这种关系。它的默认名字是目标实体的名字。这个名字可以使用setName()方法覆写。记住如果还有一个实体对这个相同的实体有复合关系,则这个默认关系名字必须唯一。这种情况下,你必须明确定义对象名字。
构建To-One关系模型(Modelling To-One Relations)
在greenDao生成器模型中,必须将一个属性作为外码值,使用这个属性,通过Entity.addToOne方法可以添加一个to-one关系。
// The variables "user" and "picture" are just regular entities
Property pictureIdProperty = user.addLongProperty("pictureId").getProperty();
user.addToOne(picture, pictureIdProperty); 这个关系是,User实体中有一个Picture属性(getPicture/setPicture),可以直接和该Picture对象进行交互。
注意外码属性(”pictureId”)和实体对象属性(”picture”)是绑定在一起的。如果改变了pictureId,则接下来调用getPictur()方法会得到更新ID后的新Picture实体。如果设置了新的Picture实体,则pictureId属性也会更新。
to-one关系的获取方法第一次访问目标实体时,需要现加载实体,所以比较缓慢,但随后的访问将直接返回之前加载的实体。
greenDao也支持预加载to-one关系。它将用一条单独的数据库查询解决一个实体与所有实体的to-one关系。目前,你可以使用生成的DAO的loadDeep和queryDeep去使用这些特征。
关系名称和复合关系(Relation Names and multiple Relations)
现在扩展前面的例子,让用户也有一张缩略图。因为原图和缩略图都会关联到关联到一个相同的Picture实体,所以这会有一个命名冲突。因此,重命名第二个关系名称为“thumbnail”。
Property pictureIdProperty = user.addLongProperty("pictureId").getProperty();
Property thumbnailIdProperty = user.addLongProperty("thumbnailId").getProperty();
user.addToOne(picture, pictureIdProperty);
user.addToOne(picture, thumbnailIdProperty, "thumbnail");构建To-Many关系模型(Modelling To-Many Relations)
To-Many关系的模型创建同to-one关系的很像,只是外码被放置在一张目的表中。下面让我们看一个cusomer/order的例子。一个customer能放置多个order,这就是一个to-many关系。在数据库中,通过增加一个customer ID列到order表中来创建1:N的关系。这样,可以使用customer ID查询一个customer的所有order。
做To-Many关系模型,首先,你需要在目的实体中增加一个属性去引用to-many关系的源实体。然后需要使用添加到目的实体中的属性来向源实体增加一个to-many关系。
假设我们有一个customer和一个order实体,我们想将orders和一个customer联系起来。下面的代码向customer实体中添加了to-many关系。
Property customerId = order.addLongProperty("customerId").notNull().getProperty();
ToMany customerToOrders = customer.addToMany(order, customerId);
customerToOrders.setName("orders"); // Optional
customerToOrders.orderAsc(orderDate); // Optional 这样,可以使用Customer类的getOrders()方法去获取所有的orders。
List orders = customer.getOrders();解决和更新To-Many关系(Resolving and Updating To-Many Relations)
第一次查询时,To-Many关系是被解决缓慢的。这之后,相关的实体会被缓存在一个List列表中。随后的访问,不再查询数据库。
注意更新to-many关系需要更多的工作。因为to-many list列表已被缓存,当相关实体被添加到数据库中时,它们不会被更新。下面的代码说明了这个行为:
List orders1 = customer.getOrders();
int size1 = orders1.size();
Order order = new Order();
order.setCustomerId(customer.getId());
daoSession.insert(order);
Listorders2 = customer.getOrders();
// size1 == orders2.size(); // NOT updated
// orders1 == orders2; // SAME list object因为缓存,你应该向源实体(order)的to-many List列表中添加新的关联实体。下面给出了怎样插入新的实体:
- 获取to-many Java List列表。
- 创建一个新的实体对象。
- 向目标实体中设置新的实体的外码属性。
- 插入新对象。
- 向to-many Java List列表中增加新的对象。
示例代码:
List orders = customer.getOrders();
newOrder.setCustomerId(customer.getId());
daoSession.insert(newOrder);
orders.add(newOrder); 注意getOrders()方法在插入之前调用以确保list列表被缓存。如果getOrders()方法在插入之后被调用,且orders之前没有被缓存,则newOrder将出现在list列表中两次。
同样的,你能删除关联实体:
List orders = customer.getOrders();
daoSession.delete(newOrder);
orders.remove(newOrder); 有时,在关联实体被添加或删除后更新所有的to-many关系,是累赘的甚至是不可能的。为了确保安全,greenDao提供了reset方法去清理缓存list列表。
customer.resetOrders();
List orders2 = customer.getOrders();解决和更新To-Many关系(Bi-Directional 1:N Relations)
有时你想要在双向上导航1:N关系。在greenDao中,你不得不添加一个to-one和一个to-many关系来实现它。下面拓展了上面的示例,增加了双向关系:
Entity customer = schema.addEntity("Customer");
customer.addIdProperty();
customer.addStringProperty("name").notNull();
Entity order = schema.addEntity("Order");
order.setTableName("ORDERS"); // "ORDER" is a reserved keyword
order.addIdProperty();
Property orderDate = order.addDateProperty("date").getProperty();
Property customerId = order.addLongProperty("customerId").notNull().getProperty();
order.addToOne(customer, customerId);
ToMany customerToOrders = customer.addToMany(order, customerId);
customerToOrders.setName("orders");
customerToOrders.orderAsc(orderDate);使用双向关系,能够像下面一样,获取customer和customer的所有orders:
List allOrdersOfCustomer = order.getCustomer().getOrders();Many-to-Many关系 (n:m)
数据库中,可以使用一张连接表来构建n:m关系模型。当前greenDao不直接支持n:m关系,但可以构建一张连接表作为分隔的实体。
构建Tree关系(Modelling Tree Relations)
可以通过构建一个同时有to-one和to-many关系的实体来构建Tree关系。
Entity treeEntity = schema.addEntity("TreeEntity");
treeEntity.addIdProperty();
Property parentIdProperty = treeEntity.addLongProperty("parentId").getProperty();
treeEntity.addToOne(treeEntity, parentIdProperty).setName("parent");
treeEntity.addToMany(treeEntity, parentIdProperty).setName("children");获取它的父和子的方法如下:
TreeEntity parent = child.getParent();
List grandChildren = child.getChildren();继承,接口和序列化
实体可以从另一个不是实体的类继承。超类使用setSuperclass(String)方法定义。注意,当前,让另一个实体作为超类是不可能的。
myEntity.setSuperclass("MyCommonBehavior");通常使用接口作为实体属性和行为的基础是很棒的。例如实体A和B共享一部分相同的属性集,那么这些属性可以被定义在接口C中。
entityA.implementsInterface("C");
entityB.implementsInterface("C");可以设置一个实体实现序列化。
entityB.implementsSerializable();JavaDoc和注解
实体模型允许增加JavaDocs和Java注释到实体和属性。
myEntity.setJavaDoc("This is an hell of an entity.\nIt represents foos and bars.");
myEntity.setCodeBeforeClass("@Awesome");myEntity.addIntProperty("counter")
.codeBeforeField("@SerializedName(\"the-number-of-things\")")
.javaDocGetterAndSetter("The total count"); 上面使用的方法在PropertyBuilder中提供,这些方法有:codeBeforeField, codeBeforeGetter, codeBeforeGetterAndSetter, codeBeforeSetter, javaDocField, javaDocGetter, javaDocGetterAndSetter, and javaDocSetter。
触发代码生成
你需要的实体模式完成后,就可以触发代码生成进程。
DaoGenerator daoGenerator = new DaoGenerator();
daoGenerator.generateAll(schema, "../MyProject/src-gen");生成代码时,需要一个模式对象和一个生成路径,如果需要将用于测试的类生成到另外的路径,可以使用第三个参数定义。
Keep章节
实体类在每一次代码生成时会被覆写。为了防止每次代码生成时,覆写掉自定义的代码,greenDao提供了“keep”章节。处于该章节中的代码不会被覆写。
// KEEP INCLUDES - put your custom includes here
// KEEP INCLUDES END
...
// KEEP FIELDS - put your custom fields here
// KEEP FIELDS END
...
// KEEP METHODS - put your custom methods here
// KEEP METHODS END注意不要对上面生成的代码进行编辑。
会话(Sessions)
生成的DaoSession是greenDao的核心操作接口之一。DaoSession提供了访问实体的基础操作,DAOs则有更完全的的操作集。Sessions也管理着实体的标识范围。
DaoMaster and DaoSession
前面说过,获取DaoSession需要创建一个DaoMaster:
daoMaster = new DaoMaster(db);
daoSession = daoMaster.newSession();
noteDao = daoSession.getNoteDao();注意数据库连接属于DaoMaster,所以多数的会话(Sessions)使用相同的数据库连接。这样新的会话能够被更快速的创建。但每一个会话为实体分配一个单独的会话缓存。
标识范围和会话缓存(Identity scope and session “cache”)
如果你有两个要返回相同数据库对象的查询,那么会生成多少个Java对象,一个还是两个?这依赖于标识范围。在greenDao中默认的(这个行为可以配置)是多次查询返回同一个Java对象。例如,用ID 42在USER表中加载User对象,则每次查询返回同一个Java对象。
这种行为是由于实体缓存的影响。如果一个实体仍在内存中(greenDao使用弱引用),则这个实体不会再用数据库中的值重新构造。例如,如果你用同一个ID加载一个以前加过的实体,则greenDao不需要再查询数据库。所以它能很快的从会话缓存中返回对象。
数据库操作
对数据库进行操作时,可以构建SQL语句进行操作,也可以使用greenDao的API进行操作。对于使用SQL语句进行操作,我们不在这里讲解,如果不熟悉可查阅相关资料进行学习。下面我们重点对greenDao的操作API进行讲解。
插入(insert)
long insert(Bean entity)
向数据库表中插入Bean对象,返回插入表中的行ID。void insertInTx(Iterableentities)
Tx后缀表示该操作使用数据库事务,使用事务对于大数量的操作更高效。该方法表示,使用数据库事务,向数据库中插入一些对象。void insertInTx(Bean... entities)long insertOrReplace(Bean entity)
数据库中没有待插入对象,则插入该对象,有则用该对象完全替换数据库中数据。返回插入表中的行ID。void insertOrReplaceInTx(Iterableentities) void insertOrReplaceInTx(Bean... entities)
刷新(refresh)
void refresh(Bean entity)
从数据库中加载一份新的数据到Bean缓存中,即对该Bean缓存缓存进行刷新。
更新(update)
void update(Bean entity)
数据库字段更新,数据库中的字段完全更新为entity中的数据,包括null。所以当有些字段不想更新时,具体逻辑需要进行控制。void updateInTx(Iterableentities)
删除(delete)
void delete(Bean entity)
从数据库中删除对象,该对象必须有唯一标识。void deleteInTx(Iterableentities) void deleteInTx(Bean... entities)void deleteByKey(long key)
通过key从数据库中删除该条数据。void deleteByKeyInTx(Iterablekeys)
-void deleteByKeyInTx(long... keys)
查询删除
有些时候,我们需要对数据库一些满足删除条件的数据执行批量删除。这是可以使用查询删除的方法。为了执行批量删除,需要创建一个QueryBuilder并在其上调用buildDelete()方法,这回返回一个DeleteQuery对象。注意,目前这种批量删除不会影响标识范围内的实体,比如如果被删除的实体之前通过他们的ID范围并缓存过,则可以恢复它们。如果你使用这种方式引发了问题,则考虑清理标识范围。
查询(query)
查询支持懒加载(不使用缓存,每次查询从数据库读取),这可以在操作大数据集时,节省内存,提升性能。
QueryBuilder
QueryBuilder提供了greenDao查询数据库的API。下面给出一个它的基础使用示例。
查询描述:获取出生在1970年10月之后的,first name为“joe”的用户,并将结果按Last name降序排列。
QueryBuilder qb = userDao.queryBuilder();
qb.where(Properties.FirstName.eq("Joe"),
qb.or(Properties.YearOfBirth.gt(1970),
qb.and(Properties.YearOfBirth.eq(1970), Properties.MonthOfBirth.ge(10)))).orderAsc(Properties.LastName);
List youngJoes = qb.list();Limit和Offset
有时,我们仅需要一个查询结果的子集,例如尽查询结果的前10项需要展示在UI。当要查询的结果有大量数据时,限制查询的数量是非常有用的,可以明显的提升查询效率和性能。QueryBuilder中定义了限制和偏移的方法。
limit(int):限制查询返回结果的数量offset(int):该方法需要和limit(int)方法结合使用,而不能单独使用。它用来设置返回结果获取时的偏移。它和limit(int)一起使用时,首先进行结果集的偏移,然后在返回限制的结果数量。
unique
greenDao提供返回唯一的结果(0个或1个结果)或结果列表。如果你使用unique()方法希望获取一个唯一的结果,则当存在查询结果时,将返回给你一个单独的结果,但当不存在查询结果时,将返回一个null。如果你想避免返回一个null结果,则调用uniqueOrThrow()方法来保证返回的是不为null的实体,但当不存在查询结果时,将会抛出DaoException的异常。
list
当需要一个查询结果集时,可以使用list方法:
list():所有的实体被加载进内存。返回结果类型是ArrayList。listLazy():实体按需求被加载进内存。一个元素一旦被访问过一次,则其将被缓存起来以便之后直接使用。必须被关闭。listLazyUncached():一个“虚拟的”实体列表。任何对该结果列表的访问,都需要从数据库中加载数据。必须被关闭。listIterator():让你可以遍历按需加载出来的结果。数据不会被缓存。必须被关闭。
方法listLazy(),listLazyUncached()和listIterator()都使用了greenDao的LazyList类。为了按需加载数据,它持有数据库cursor的引用。这是为什么必须保证关闭lazy list和iterators的原因(通常在 try/finally块中关闭)。如果所有的结果都被访问或遍历了,则listLazy()方法缓存的lazy list和listIterator()方法的lazy iterator会自动的关闭cursor。但如果你想过早地停止list的访问,则你需要调动close()方法来主动关闭cursor。
多次执行查询
Query类代表了一个可以被多次执行的查询。当你使用QueryBuilder中的方法获取查询结果时(比如list()方法),QueryBuilder在内部使用了Query类。如果你想多次使用一个相同的查询,则你可以在QueryBuilder上调用build()方法来创建没有执行的Query。
复用一个Query比每次创建新的Query对象更有效率。如果再次查询参数不需要改变,则你仅仅需要再次调用list/unique方法。如果查询参数改变了,则你需要调用setParameter方法重新设置参数。目前,参数需要使用以0开始的索引寻址。这个索引基于你传递到QueryBuilder中参数的顺序。
下面的示例,先使用Query对象获取了出生在1970年,first name为Joe的用户:
Query query = userDao.queryBuilder().where(
Properties.FirstName.eq("Joe"), Properties.YearOfBirth.eq(1970))
.build();
List joesOf1970 = query.list();接下来,使用相同的Query对象,查询出生在1977年,first name为Marias的用户:
query.setParameter(0, "Maria");
query.setParameter(1, 1977);
List mariasOf1977 = query.list();多线程执行查询
如果在多线程中使用查询,则需要在query上通过调用forCurrentThread()方法来获取一个当前线程的Query实例。Query对象实例在创建查询时被绑定到创建它的线程。这样就可以安全的设置参数,而不会受其他线程的影响。如果其他线程尝试在该query上设置参数或将该query绑定到其它线程,则会抛出异常。这样,你就不需要自己进行同步。实际上应该避免加锁,因为在并发处理时使用相同的查询对象,容易导致死锁。
为了避免死锁,greenDao提供了forCurrentThread()方法。这个方法返回一个当前线程的Query实例,在当前线程中使用它是绝对安全的。每次调用forCurrentThread()方法,参数都会被设置回query被创建时的初始参数。
原始SQL查询
某些情况下,QueryBuilder并不能满足你的需求,则可以使用原始SQL查询解决。有两种执行SQL语句的方法。最常用的方式是使用QueryBuilder和WhereCondition.StringCondition。这种方式,你可以向query builder的where语句传递任意的SQL语句片段。下面示例展示了这种方式的使用方法:
Query query = userDao.queryBuilder().where(
new StringCondition("_ID IN " +
"(SELECT USER_ID FROM USER_MESSAGE WHERE READ_FLAG = 0)").build();另一种不使用QueryBuilder的方式是,在DAOs上使用queryRaw或queryRawCreate方法。你可以向它们传入一个原始SQL语句,它会被添加到SELECT和实体字段后。用这种方式可以编写任何WHERE和ORDER BY语句去查询需要的实体集。实体表可以使用别名“T”来引用。使用示例如下:
Query query = userDao.queryRawCreate(
", GROUP G WHERE G.NAME=? AND T.GROUP_ID=G._ID", "admin");注意:可以使用生成的常量来表示表名和字段名。这是推荐的做法,可以避免编写错误。在一个实体的DAO中,TABLENAME表示数据库的表名,其内部类Properties则有所有属性的常量。
分析故障
如果没有返回你期望的查询结果,则可以打开QueryBuilder中的两个关于打印SQL和执行参数的Log标识。
QueryBuilder.LOG_SQL = true;
QueryBuilder.LOG_VALUES = true;连接查询
复杂的查询通常需要获取多个实体(表)的数据。使用SQL语言,可用方便地使用连接条件将两个或更多表连接起来。
让我们考虑这样一种情况,一个User实体,它和Address实体有1:n的关系,现在让我们查询住在“Sesame Street”的用户。首先,我们必须使用User ID将User实体和Address实体连接,然后在Address实体上定义WHERE条件:
QueryBuilder queryBuilder = userDao.queryBuilder();
queryBuilder.join(Properties.addressId, Address.class)
.where(AddressDao.Properties.Street.eq("Sesame Street"));
List users = queryBuilder.list(); 连接需要目标实体class和每个实体中的一个连接属性作为参数。在上面的例子中,没有显示地给出Address实体的连接属性参数,这是因为,Address实体中仅有一个连接属性(address id)被定义,且该属性为主码(PK),所以其被默认地使用。
QueryBuilder中的连接API
publicJoin destinationEntityClass, Property destinationProperty)
该方法中,主实体的主码会被用来匹配给定的目标属性(destinationEntityClass)。publicJoin destinationEntityClass)
该方法中,给出的源属性(sourceProperty)是被用来匹配给出的目标实体(destinationEntityClass)的主码。publicJoin destinationEntityClass, Property destinationProperty)
该方法中,给出的源属性(sourceProperty)是被用来匹配给出的目标实体(destinationProperty)的目标属性(destinationProperty)。
链式连接
greenDao允许链式连接多个实体。即你可以使用一个连接和一个目标实体定义另一个连接。这种情况下,第一个连接的目标实体,变成了第二个连接的开始实体。
链式连接的API如下:
public
下面给出一个三个实体连接的示例:City,Country和Continent。查询在欧洲人口数超过100万的所有城市:
QueryBuilder qb = cityDao.queryBuilder().where(Properties.Population.ge(1000000));
Join country = qb.join(Properties.CountryId, Country.class);
Join continent = qb.join(country, CountryDao.Properties.ContinentId, Continent.class, ContinentDao.Properties.Id);
continent.where(ContinentDao.Properties.Name.eq("Europe"));
List bigEuropeanCities = qb.list(); 自连接(可构成树形结构)
连接也可以用来连接多个相同实体。例如,假设我们有一个Person实体,其具有一个指向同类Person实体的fatherId属性,现在我们想要找到所有祖父的名字是“Lincoln”的人。
QueryBuilder qb = personDao.queryBuilder();
Join father = qb.join(Person.class, Properties.FatherId);
Join grandfather = qb.join(father, Properties.FatherId, Person.class, Properties.Id);
grandfather.where(Properties.Name.eq("Lincoln"));
List lincolnDescendants = qb.list(); 数据库升级
greenDao数据库升级,首先需要提升“生成器”中的public Schema(int version, String defaultJavaPackage)方法中的数据库版本字段。修改后,需要重新生成一遍代码。接下来需要自定义一个继承自DaoMaster.OpenHelper的类:
public class TestDevOpenHelper extends DaoMaster.OpenHelper {
public TestDevOpenHelper(Context context, String name, SQLiteDatabase.CursorFactory factory) {
super(context, name, factory);
}
@Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
//数据库升级
}
}自定义的TestDevOpenHelper类,在获取DaoMaster时使用:
DaoMaster.OpenHelper helper = new TestDevOpenHelper(context, DATABASE_NAME, null);
DaoMaster daoMaster = new DaoMaster(helper.getWritableDatabase());源码地址