PyTorch学习系列(一)——加载数据并生成batch数据
开始学习PyTorch,在此记录学习过程。准备按顺序写以下系列:
- 加载数据并生成batch数据
- 数据预处理
- 构建神经网络
- Tensor和Variable
- 定义loss
- 自动求导
- 优化器更新参数
- 训练神经网络
- 参数_定义
- 参数_初始化
- 如何在训练时固定一些层?
- 绘制loss和accuracy曲线
- torch.nn.Container和torch.nn.Module
- 各层参数及激活值的可视化
- 保存训练好的模型
- 如何加载预训练模型
- 如何使用cuda进行训练
读取数据生成并构建Dataset子类
假设现在已经实现从数据文件中读取输入images和标记labels(列表),那么怎么根据images和labels定义自己的数据集类?答案是作为torch.utils.data.Dataset的子类。
torchvision.datasets中有几个已经定义好的数据集类,这些类都是torch.utils.data.Dataset抽象类的子类:
- torchvision.datasets.MNIST类:标签是一维的,不是one-hot稀疏标签。
- torchvision.datasets.CIFAR10
- torchvision.datasets.ImageFolder
…
在定义torch.utils.data.Dataset的子类时,必须重载的两个函数是__len__和__getitem__。__len__返回数据集的大小,__getitem__实现数据集的下标索引,返回对应的图像和标记(不一定非得返回图像和标记,返回元组的长度可以是任意长,这由网络需要的数据决定)。
在创建DataLoader时会判断__getitem__返回值的数据类型,然后用不同的if/else分支把数据转换成tensor,所以,_getitem_返回值的数据类型可选择范围很多,一种可以选择的数据类型是:图像为numpy.array,标记为int数据类型。
示例:
from __future__ import print_function
import torch.utils.data as data
import torch
class MyDataset(data.Dataset):
def __init__(self, images, labels):
self.images = images
self.labels = labels
def __getitem__(self, index):#返回的是tensor
img, target = self.images[index], self.labels[index]
return img, target
def __len__(self):
return len(self.images)
dataset = MyDataset(images, labels)生成batch数据
现在有了由数据文件生成的结构数据MyDataset,那么怎么在训练时提供batch数据呢?PyTorch提供了生成batch数据的类。
PyTorch用类torch.utils.data.DataLoader加载数据,并对数据进行采样,生成batch迭代器。
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=
参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
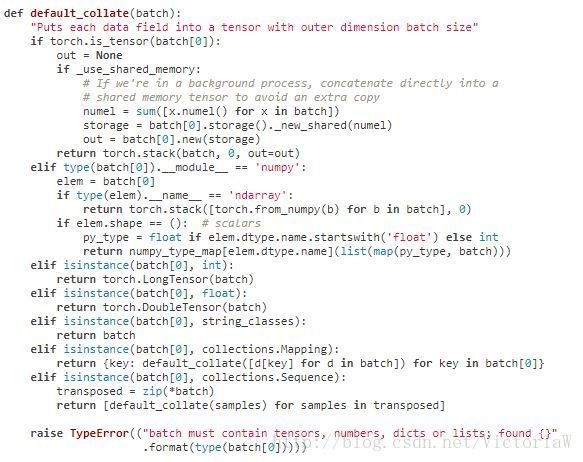
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
示例:
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
train_loader = torch.utils.data.DataLoader(
MyDataset(images, labels), batch_size=args.batch_size, shuffle=True, **kwargs)其他用法:
len(train_loader) :返回的是len(dataset)/batch_size