Python+opencv 人脸识别
python+opencv人脸检测+识别示例及原理解析
- 一.开发环境搭建
- 二.图片人脸检测
- 2.1 文件准备与编程
- 2.2 注意事项
- 三.视频人脸识别
- 3.1文件准备与编程
- 3.2 注意事项
- 四.人脸检测
- 4.1 产生人脸识别图片
- 4.2 训练人脸识别系统
- 4.4 人脸识别
- 五.人脸识别原理
- 5.1 计算机识别原理
- 5.2 特征提取与图形处理
- 5.3 Haar级联分类器
一.开发环境搭建
我们使用Python自带的IDLE进行编程,我使用的电脑是Windows系统,代码在win7 64位,win10 64位这两种电脑上验证过。Python版本为3.xx,需要使用的库有opencv,numpy,pillow。这三个库分别使用pip按照即可,指令分别为;
1)opencv;pip install opencv-python
2)numpy;pip install numpy
3)pillow;pip install pillow
二.图片人脸检测
2.1 文件准备与编程
在桌面新建一个face_identity的文件夹,然后在Python的安装目录,按照这个路径依次打开文件夹Lib→site-packages→cv2→data,复制文件“haarcascade_frontalface_default.xml”,“haarcascade_frontalcatface.xml”到face_identity文件夹,这两个是分类器,用于进行人脸检测。接着在网上随便找一张有人脸的图片,命名为pic.jpg,然后新建一个名为pic_identity.py的文件,输入如下代码,运行后得到一张绘制出人脸的新图片。我选择的是女神刘亦菲,所以画了矩形的图片名字是liuyifei.jpg。
'''
在一张图片上识别出人脸,并在脸周围绘制一个矩形,最后把绘制矩形的图片保存到一张新图片
'''
import cv2
import os
#os.path.join函数会根据系统返回一个路径字符串
filename=os.path.join('.','pic.jpg')
savefilename=os.path.join('.','liuyifei.jpg')
def detect(filename):
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
#声明cascadeclassifie对象face_cascade,用于检测人脸
face_cascade=cv2.CascadeClassifier(face_xml_location)
img=cv2.imread(filename)
#openCV识别灰度图片,也就是黑白图片,所以要进行转换
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces=face_cascade.detectMultiScale(gray,1.3,5)
#在人脸周围绘制矩形
for (x,y,w,h) in faces:
img=cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),0)
cv2.namedWindow('liuyifeidetected')
cv2.imshow('liuyifeidetected',img)
cv2.imwrite(savefilename,img)
cv2.waitKey(0)
#图片人脸检测程序,识别图片pic.jpg
detect(filename)
2.2 注意事项
在这里需要注意的有如下几点;
1)文件路径;如果你不是使用os.path.join()函数得到文件路径,而是直接手打的话,需要注意在Windows系统里路径使用的是反斜杠分隔,而在macOS,Linux中文件路径是用正斜杠分隔,同时因为在Python中反斜杠还是转义字符,所以需要用两个反斜杠才能正常引用。
2)图片;这个方法检测只能检测正立的脸,所以不要用哪种横着的,歪斜得很厉害的图片来检测
三.视频人脸识别
3.1文件准备与编程
在计算机眼里,视频其实就是不断变化的图片,只要图片切换的时间间隔小于人眼的视觉暂留时间0.1s,你的眼睛就会感觉画面上的是视频而不是图片。所以这里我们只要把刚才的图片检测程序稍微修改一下,把从摄像头抓取的图片作为检测源,然后实时显示出产生的画了人脸矩形的图片就可以让我们感觉摄像头在实时检测视频中的人脸了。在刚才的face_identity文件夹里新建一个live_identity.py的文件,写入如下代码;
import cv2
import os
def live_detect():
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
#声明cascadeclassifie对象face_cascade,用于检测人脸
face_cascade=cv2.CascadeClassifier(face_xml_location)
#打开设置摄像头对象,摄像头编号默认为0
camera=cv2.VideoCapture(0)
#循环检测人脸并在人脸周围绘制矩形
while(True):
ret,frame=camera.read()
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
faces=face_cascade.detectMultiScale(gray,1.3,5)
for(x,y,w,h) in faces:
img=cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),0)
#实时显示识别结果,按q,跳出while循环,停止识别
cv2.imshow("camera",frame)
if cv2.waitKey(50) & 0xff==ord("q"):
break
#释放摄像头,关闭窗口
camera.release()
cv2.destroyAllWindows()
#调用人脸检测函数
live_detect()
3.2 注意事项
1)摄像头;一般来说电脑只有1个摄像头,默认编号为0,如果有两个,想要打开第二个摄像头就把cv2.VideoCapture(0)函数的参数0替换为1。
2)刷新频率;前面说过只有两张图片时间间隔大于0.1秒才会看起来是比较流畅的视频,我们这个程序两张图片的间隔时间由cv2.waiKey()函数决定,括号里的数就是两张图片间的时间间隔,单位为毫秒, 注意一定,一定不要填小数 。
四.人脸检测
4.1 产生人脸识别图片
在face_identity文件夹里再新建两个文件夹face_pic,用来保存训练人脸识别系统的图片;train_data用来保存训练数据。然后新建一个face_creat.py的文件来产生人脸识别训练图片,代码如下;
'''
本程序用于产生50张灰度图片素材用于后续训练人脸识别系统
'''
import cv2
import os
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
detector = cv2.CascadeClassifier(face_xml_location)
camera = cv2.VideoCapture(0)
pic_num = 0
ID = input('enter your id: ')
while True:
ret, img = camera.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray,1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
pic_num = pic_num + 1
pic_save_location=os.path.join('.','face_pic','user%s.%s.jpg')
cv2.imwrite(pic_save_location%(ID,pic_num), gray[y:y + h, x:x + w])
cv2.imshow('frame', img)
# 设置相片取样间隔
if cv2.waitKey(100) & 0xFF == ord('q'):
break
# 设置采样相片数
elif pic_num > 50:
break
camera.release()
cv2.destroyAllWindows()
4.2 训练人脸识别系统
import cv2
import os
import numpy as np
from PIL import Image
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
detector = cv2.CascadeClassifier(face_xml_location)
recognizer = cv2.face.LBPHFaceRecognizer_create()
def get_images_and_labels(path):
image_paths = [os.path.join(path, f) for f in os.listdir(path)]
face_samples = []
ids = []
for image_path in image_paths:
image = Image.open(image_path).convert('L')
image_np = np.array(image, 'uint8')
if os.path.split(image_path)[-1].split(".")[-1] != 'jpg':
continue
image_id = int(os.path.split(image_path)[-1].split(".")[1])
faces = detector.detectMultiScale(image_np)
for (x, y, w, h) in faces:
face_samples.append(image_np[y:y + h, x:x + w])
ids.append(image_id)
return face_samples, ids
tain_data_location=os.path.join('.','train_data','train.yml')
face_data_location=os.path.join('.','face_pic')
faces, Ids = get_images_and_labels(face_data_location)
recognizer.train(faces, np.array(Ids))
recognizer.save(tain_data_location)
4.4 人脸识别
import cv2
import numpy as np
import os
recognizer = cv2.face.LBPHFaceRecognizer_create()
train_data_location=os.path.join('.','train_data','train.yml')
recognizer.read(train_data_location)
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
face_cascade = cv2.CascadeClassifier(face_xml_location)
camera = cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
while True:
ret, im = camera.read()
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.2, 5)
for (x, y, w, h) in faces:
cv2.rectangle(im, (x - 50, y - 50), (x + w + 50, y + h + 50), (225, 0, 0), 2)
img_id, conf = recognizer.predict(gray[y:y + h, x:x + w])
if conf > 50:
if img_id == 1:
img_id = 'rico'
else:
img_id = "Unknown"
cv2.putText(im, str(img_id), (x, y + h), font, 0.55, (0, 255, 0), 1)
cv2.imshow('im', im)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
五.人脸识别原理
5.1 计算机识别原理
不论是图像识别,还是声纹识别,字迹识别,这些都有一个统一的流程,如下图所示。

在这个流程中要弄明白两个东西,特征提取和分类器。就像我们看到一张动物图片,图片上它高30厘米,长50厘米,有四只脚,身上有短毛,脚上有肉垫,一根尾巴,我们根据这些特征判断这个动物是一只猫。它的这些数据就是我们提取的特征,后面我们判断它是一只猫,就是我们根据经验对它进行了分类,分类为猫,我们大脑就是个分类器,根据特征进行了分类。
那么在人脸检测与识别过程中哪些环节是特征提取,哪些环节是分类器分类环节呢?
5.2 特征提取与图形处理
在一张图片中除了我们想要检测的人之外,还会有一些环境物体,比如有一棵枝繁叶茂的树,有各种各样的家具。计算机是怎么知道要提取谁的特征呢?其实计算机会先对图像进行一些基本的处理找到图片中的目标区域。
1)傅里叶变换
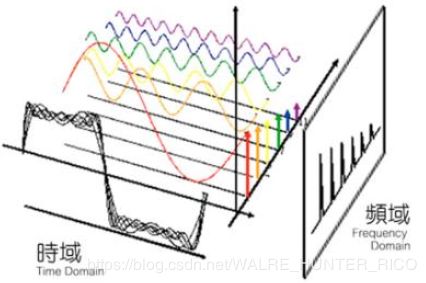
上面这张图中最前面的灰色杂乱的曲线,可以由后面六个简单的正弦曲线合成。我们平时看的图像是时域的图像,你可以理解为从图片中写了时域的这个方向向图像看去。而傅里叶变换则是让我们得到从侧面(频域)去看这个图像的曲线,从侧面看的话这个在时域中很复杂的曲线就变成了六个固定高度的线段。如果我们把这六个线段中的任意一个去掉,这样会导致从正面看的图像发生一定变化。
在前面开篇我们说过,图像其实可以看成是数学上的数组组成,图像上的代表物体的图形其实可以理解为以数组为单位的曲线。那么这也就意味着,如果我们从这些代表物体的曲线侧面看,是不是也可以把这张图分成几个简单的小竖线?我们可以这样来理解,不过组成图像中图形的小竖线是一些特殊的图像。和前面坐标系中的小竖线同理,我们通过提取这些特殊图像中的一部分就可以从一张图像中得到不同类型的信息。根据这个原理我们可以从假借频域,把图像分离出频域,从频域中选取特定的小竖线,合成到时域上,从而在图像中提取我们想要的那些元素。
2)高通滤波器(HPF)与低通滤波器(LPF)
高通滤波器器,如果有一个像素比周围的像素更亮,那么高通滤波器会进一步提高它的亮度,让这个像素更突出。
低通滤波器,如果有一个像素比周围图像都亮一些,那么低通滤波器会把它周围的像素都变亮一些,让这个像素不那么突出。
从上面的描述你可以很容易发现,高通滤波器可以让突出的更突出,这种可以用来检测图像中物体的边缘和轮廓,而低通滤波就就像一个平均主义者,可以把图像中的一些噪点模糊掉,避免对特征识别造成影响。
5.3 Haar级联分类器
在我们的人脸检测程序里引用了一个haarcascade_frontalface_default.xml文件来进行人脸检测。