通俗理解Faster R-CNN和RPN
通俗理解Faster R-CNN和RPN
最近在学习Faster R-CNN,有一些心得,希望可以给大家以启发。
我之前对比过R-CNN,SPP-Net , Fast R-CNN, Faster R-CNN 的区别和理解,有需要的朋友可以看一下:https://blog.csdn.net/XM_no_homework/article/details/88712991
下面进入正题谈一下我对Faster R-CNN的理解
叙述顺序:
启发
步骤
一、 特征提取:
二、 候选框(RPN)
- Anchor Box的获取
- RPN网络
二、 ROIPooling
ROIPooling
分类&边框回归
RPN和Fast R-CNN的合并方式(参数共享方式)
启发
- 可以认为Faster R-CNN = 提取proposal的RPN + 分类采用Fast R-CNN
- Anchor是RPN的核心, RPN是Fast R-CNN的核心;
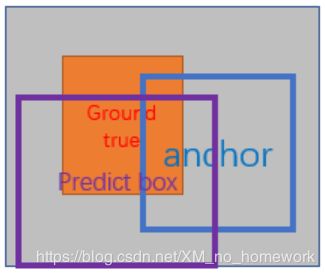
- RPN网络训练目标是让其输出的predict box(PRN推荐的框)和真实框ground true box的差距 接近Anchor box 与 ground true box的差距
RPN训练目标(Loss优化的方向):让 predict box - ground true box 接近 Anchor box - ground true box
RPN输出目标:使其可以得到提取的proposal(建议区域)(类似于Select Search所给出的proposal)
- RPN与Fast R-CNN结合方式(参数共享的方式)不止一个
步骤
我用’总-分‘的顺序理解Faster R-CNN,Faster R-CNN有四部分:
- 特征提取
- 候选框 (RPN)
- ROI Pooling
- 分类+边框回归
一、特征提取:
在数据集(ImageNet)训练CNN模型(例如VGG16,ZF-Net)作为特征提取模型(例如VGG和ZF-Net第五层卷积层以前的神经网络),此时我们把原图作为Input输入训练好的特征提取模型 此时我们得到了 特征图(Feature Map)(例如CONV5后得到的卷积结果)
下面圈出的部分就是特征提取部分,下面给出示意图(并没用,有图避免文字疲劳- - 此图摘自其他博客,这图只是RPN在Faster R-CNN的一种工作方式,只是助于理解,下面会给出解释)
二、候选框(RPN):
此时我们已经得到FeatureMap 首先总的说 RPN(Region Proposal Net)就是:
input feature map → RPN → output经过筛选要进入ROIPooling的建议框(predicted box)
Anchor Box的获取
首先说明Anchor。
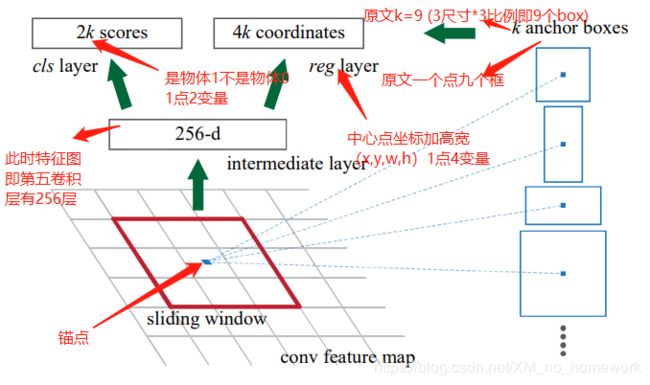
先给出下面的图吧,毕竟都是这个流程= =,就是对每个锚点进行三个尺寸三个比例的选取,即 一个锚点 9个Box(论文中3个尺度(128* 128, 256* 256, 512* 512}),3个比例( {1:1,1:2,2:1} )) 下面说明锚点哪里来的?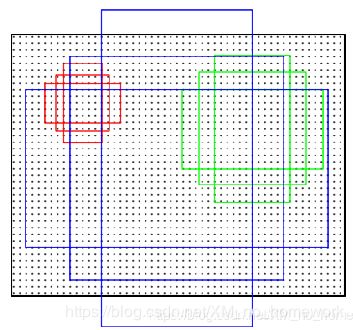
锚点是 感受域 或者 滑动窗口(原文 3* 3)其实就可以想象成 的3* 3卷积核,这个窗口滑动过程中每一个中心就是一个锚点
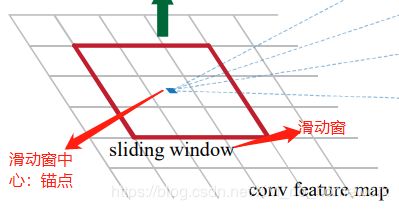
顺便说一下由于只是卷积和池化所以所有锚点是可以按比例对应到原图的,所以可以与真实的物体的框(ground true box)进行比较(即后面要提到的ROI也就是我们的box和ground true box的重合率)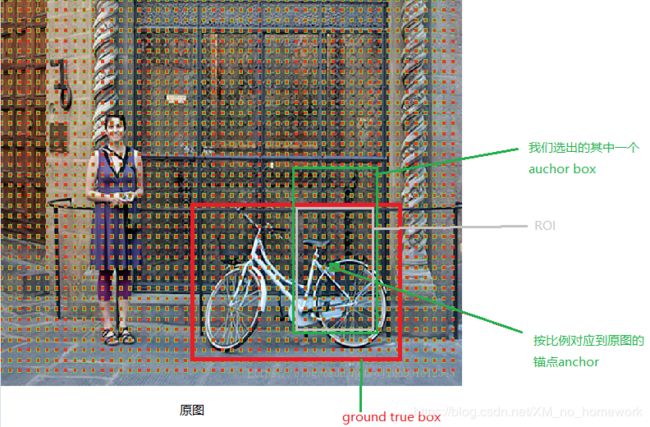
RPN网络
现在我们有了Anchor Box,接下来继续介绍RPN网络。
RPN网络很简单,RPN 是全卷积(full conv) 网络,特征图作为输入. 首先,采用 512 个3×3 kernel 的卷积层,然后是两个并行的 2k和4k 个1×1 kernel 的卷积层(这里的k就是每个锚点的Box数上面说到了,论文中k=9)
两个FC层
一个FC接二分类softmax,输出是物体概率score(是物体)和不是物体概率score(是背景);
一个FC接bounding box regressor(边框回归) 输出代表这个predict box的4个坐标位置
前面说到了RPN网络:
RPN训练目标(Loss优化的方向):让 predict box - ground true box 接近 Anchor box - ground true box
RPN输出目标:使其可以得到提取的proposal(建议区域)(类似于Select Search所给出的proposal)
我们可以根据RPN训练目标确定Loss → 训练好网络使其达到RPN输出目标
(Loss及计算过程:https://zhuanlan.zhihu.com/p/24916624)
三、ROIPooling和分类+边框回归
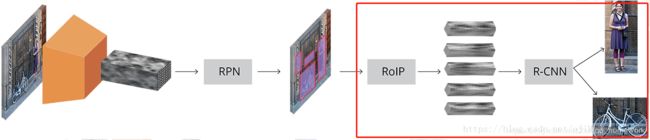
ROIPooling
RPN给出很多 proposals(建议区域)(类似于Select Search所给出的proposal)
这些给出的区域要送入接下来的分类和边框回归需要统一尺寸 (RCNN是分割变形crop&warp)这里用到了ROI Pooling 本质是一层金字塔池化(SPP)即,采用 RoI(region of interest) Pooling 对每个 proposal 提取固定尺寸的特征图
如图:
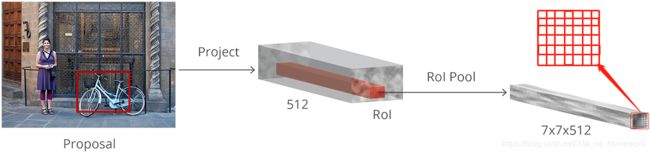
一种最简单的方法是,对每个 porposal,裁剪,并送入pre-trained base 网络,提取特征;然后,将提取特征来训练分类器. 但,这就需要对所有的 2000 个 proposals 进行计算,效率低,速度慢.
Faster R-CNN 则通过重用卷积特征图(conv feature map) 来加快计算效率. 即,采用 RoI(region of interest) Pooling 对每个 proposal 提取固定尺寸的特征图. R-CNN 是对固定尺寸的特征图分类.
分类&边框回归
这步骤基本和Fast R-CNN相同,但这里不只是一组Loss了,因为这时候要和RPN合并。模型合并后,会有两组(4个)Loss。一组2 个用于 RPN,一组2 个用于 R-CNN.、
RPN 和 R-CNN 的base基础网络可以是可训练(fine-tune)的,也可以是不能训练的.
RPN和Fast R-CNN的合并方式(参数共享方式)
如果是分别训练两种不同任务的网络模型,即使它们的结构、参数完全一致,但各自的卷积层内的卷积核也会向着不同的方向改变,导致无法共享网络权重,论文作者提出了三种可能的方式:
Alternating training:此方法其实就是一个不断迭代的训练过程
a. 先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出的proposal作为此时Fast-RCNN的输入训练Fast R-CNN。
b. 用Fast R-CNN的网络参数去初始化RPN。之后不断迭代这个过程,即循环训练RPN、Fast-RCNN。
Approximate joint training:不同与第一张,不再是串行训练RPN和Fast-RCNN,而是尝试把二者融入到一个网络内,具体融合的网络结构如下图所示,可以看到,proposals是由中间的RPN层输出的,而不是从网络外部得到。需要注意的一点,名字中的"approximate"是因为反向传播阶段RPN产生的cls score能够获得梯度用以更新参数,但是proposal的坐标预测则直接把梯度舍弃了,这个设置可以使backward时该网络层能得到一个解析解(closed results),并且相对于Alternating traing减少了25-50%的训练时间。(此处不太理解: 每次mini-batch的RPN输出的proposal box坐标信息固定,让Fast R-CNN的regressor去修正位置?)
Non-approximate training:上面的Approximate joint training把proposal的坐标预测梯度直接舍弃,所以被称作approximate,那么理论上如果不舍弃是不是能更好的提升RPN部分网络的性能呢?作者把这种训练方式称为“ Non-approximate joint training”,但是此方法在paper中只是一笔带过,表示“This is a nontrivial problem and a solution can be given by an “RoI warping” layer as developed in [15], which is beyond the scope of this paper”,
4-Step Alternating Training
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。

参考:
https://zhuanlan.zhihu.com/p/24916624
https://blog.csdn.net/zziahgf/article/details/79311275