(二)PyTorch神经网络模型保存与载入
1 模型保存
1.0 保存模型结构和参数
import numpy as np
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
import torch.nn.functional as F
from matplotlib.font_manager import FontProperties
from mpl_toolkits.mplot3d import Axes3D
# Ubuntu system font path
font = FontProperties(fname='/usr/share/fonts/truetype/arphic/ukai.ttc')
PI = np.pi
class DynamicNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(DynamicNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.input_linear(x).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
# N, D_in, H, D_out = 64, 1000, 100, 10
N, D_in, H, D_out = 100, 1, 100, 1
x = torch.unsqueeze(torch.linspace(-PI, PI, 100), dim=1)
y = torch.sin(x) + 0.2 * torch.rand(x.size())
print("x size: {}".format(x.size()))
print("y size: {}".format(y.size))
model = DynamicNet(D_in, H, D_out)
criterion = torch.nn.MSELoss(reduction="sum")
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
print("model inside: {}".format(model))
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
# # torch.save(model, "./pytorch_models/pytorch_model.pt")
losses = []
for t in range(501):
y_pred = model(x)
loss = criterion(y_pred, y)
# print("第{}轮训练, 损失值:{}".format(t, loss.item()))
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 100 == 0:
print("第{}轮训练, 损失值:{}".format(t, loss.item()))
torch.save(model, "./pytorch_models/pre_sin.pt")
1.2 保存模型参数
import numpy as np
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
import torch.nn.functional as F
from matplotlib.font_manager import FontProperties
from mpl_toolkits.mplot3d import Axes3D
# Ubuntu system font path
font = FontProperties(fname='/usr/share/fonts/truetype/arphic/ukai.ttc')
PI = np.pi
class DynamicNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(DynamicNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.input_linear(x).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
# N, D_in, H, D_out = 64, 1000, 100, 10
N, D_in, H, D_out = 100, 1, 100, 1
x = torch.unsqueeze(torch.linspace(-PI, PI, 100), dim=1)
y = torch.sin(x) + 0.2 * torch.rand(x.size())
print("x size: {}".format(x.size()))
print("y size: {}".format(y.size))
model = DynamicNet(D_in, H, D_out)
criterion = torch.nn.MSELoss(reduction="sum")
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
print("model inside: {}".format(model))
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
losses = []
for t in range(501):
y_pred = model(x)
loss = criterion(y_pred, y)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 100 == 0:
print("第{}轮训练, 损失值:{}".format(t, loss.item()))
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"loss": loss
}, "./pytorch_models/pre_sin_state_dict.pth")
2 模型载入
2.1 载入模型结构与参数
import torch
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from mpl_toolkits.mplot3d import Axes3D
# Ubuntu system font path
font = FontProperties(fname='/usr/share/fonts/truetype/arphic/ukai.ttc')
'''Load entire model.'''
checkpoint = torch.load("./pytorch_models/pre_sin.pt")
'''Input data.'''
x = torch.unsqueeze(torch.linspace(-PI, PI, 100), dim=1)
'''Real output datas.'''
y = torch.sin(x) + 0.2 * torch.rand(x.size())
'''Use model to predict outputs based on inputs.'''
y_pred = checkpoint(x)
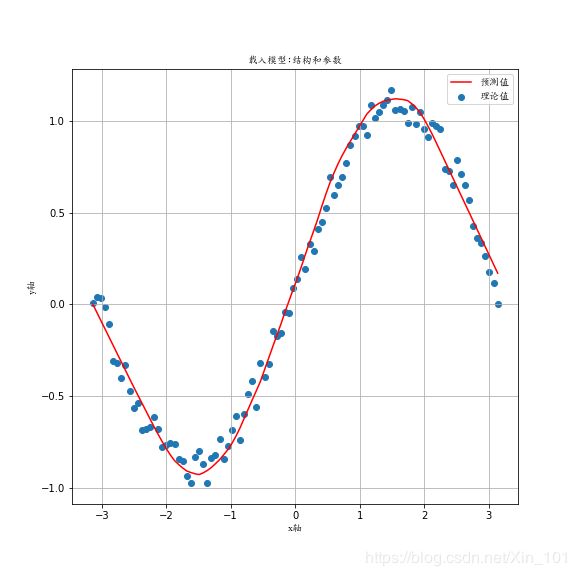
plt.figure(figsize=(8, 8))
plt.scatter(x.numpy(), y.numpy(), label="理论值")
plt.plot(x.numpy(), y_pred.detach().numpy(), "r-", label="预测值")
plt.legend(prop=font)
plt.xlabel("x轴", fontproperties=font)
plt.ylabel("y轴", fontproperties=font)
plt.title("载入模型:结构和参数", fontproperties=font)
plt.grid()
plt.savefig("./images/load_entire_model.png", format="png")
plt.show()
2.2 载入模型参数
import torch
N, D_in, H, D_out = 100, 1, 100, 1
x = torch.unsqueeze(torch.linspace(-PI, PI, 100), dim=1)
y = torch.sin(x) + 0.2 * torch.rand(x.size())
class DynamicNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(DynamicNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.input_linear(x).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
model = DynamicNet(D_in, H, D_out)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
checkpoint = torch.load("./pytorch_models/pre_sin_state_dict.pth")
model.load_state_dict(checkpoint["model_state_dict"])
print("model structure: {}".format(model.modules()))
print("model dict: {}".format(model.state_dict()))
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
y_pred = model(x)
plt.figure(figsize=(8, 8))
plt.scatter(x.numpy(), y.numpy(), label="理论值")
plt.plot(x.numpy(), y_pred.detach().numpy(), "r-", label="预测值")
plt.legend(prop=font)
plt.xlabel("x轴", fontproperties=font)
plt.ylabel("y轴", fontproperties=font)
plt.title("载入模型: 参数", fontproperties=font)
plt.grid()
plt.savefig("./images/load_state_model.png", format="png")
plt.show()
3 结果
4 总结
(1) PyTorch模型保存有两种模式,即保存模型结构和参数与保存模型参数,官网推荐使用保存模型参数(state_dict)模式。
(2) Pytorch模型格式有*.pt和*.pth两种格式。
(3) 载入state_dict模型时,需要重新定义模型结构,因为该方法仅使用了模型训练的参数。
[参考文献]
[1]https://pytorch.org/docs/stable/nn.html
[2]https://pytorch.org/docs/stable/optim.html
[3]https://pytorch.org/tutorials/beginner/saving_loading_models.html