金融信贷风控(二)——数据预处理和特征衍生
文章目录
- 申请评分卡中的数据预处理和特征衍生
- 构建信用风险类型的特征
- 数据预处理
- 特征的分箱
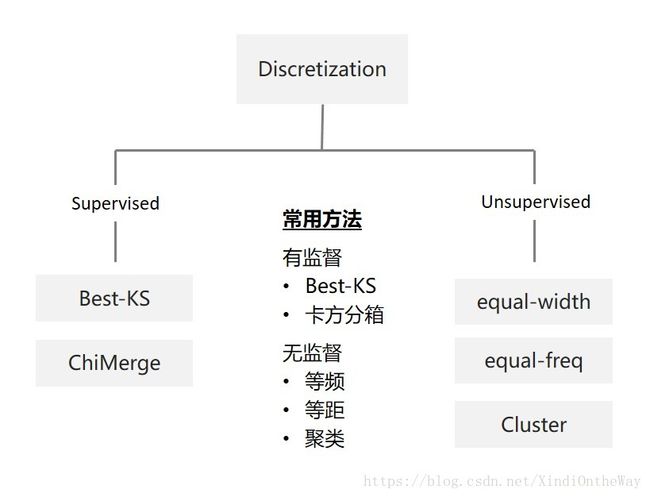
- Best-KS
- ChiMerge 卡方分箱法
- WOE编码
- WOE编码的意义
- 变量筛选
- 特征信息度
- 单变量分析和多变量分析
- 单变量分析
- 多变量分析
申请评分卡中的数据预处理和特征衍生
构建信用风险类型的特征
数据预处理
1、数据预处理
包括格式、缺失值的处理等。
缺失值包括如下几种情况:
1、完全随机缺失
2、随机缺失
3、完全非随机缺失:与变量本身有关,比如富裕家庭不愿意填收入
处理缺失值的方法:
1、补缺(平均值,众数、中位数等)
2、作为一种状态(一般为完全非随机缺失)
3、删除记录或者变量。
2. 特征构建:人工构建特征或者学习特征
常用的特征衍生:
计数:过去一年贷款的次数
求和:过去一年内网店的消费总额
比例:贷款申请额度和年收入的占比
时间差:第一次开户距今时长
波动率:过去3年内每份工作的时间的标准差
3. 特征选择:相关性、差异性、显著性
4. 模型参数估计
特征的分箱
阅读资料:
特征工程之分箱
Python数据分箱,计算woe,iv
| 分箱的定义 |
|
| 分箱的意义 |
|
| 分箱的限制 |
|
Best-KS
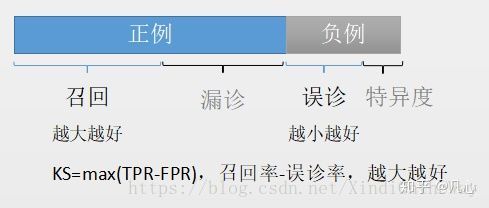
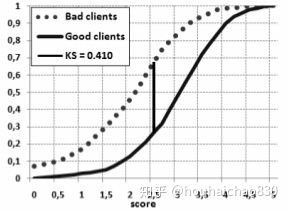
如何向门外汉讲解KS值
评分卡模型的评价标准
K S = m a x ( T P R − F P R ) KS=max(TPR-FPR) KS=max(TPR−FPR)


ChiMerge 卡方分箱法
卡方检验用于判别两个变量之间是否有显著的关联关系,原假设为两变量相互独立,可参看卡方检验.
阅读资料:
最优分箱–卡方分箱Chi-Merge


卡方统计量衡量了区间内样本的频数分布与整体样本的频数分布的差异性。




#卡方分箱
import pandas as pd
import numpy as np
from scipy.stats import chi
WOE编码
评分卡的建立方法——分箱、WOE、IV、分值分配
数据挖掘模型中的IV和WOE详解
用WOE来对分箱后的组进行编码,主要考虑:提升模型的预测效果,提高模型的可理解性。

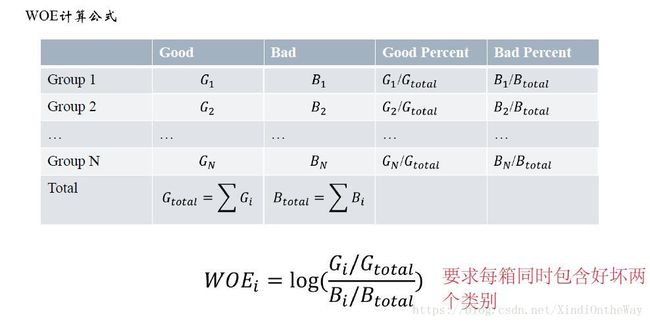
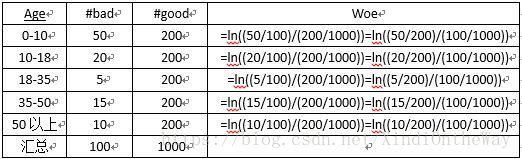
WOE表示的实际上是“当前分组中响应客户占所有响应客户的比例”和“当前分组中没有响应的客户占所有没有响应的客户的比例”的差异。可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响。
将上述公式做一些变换:
W O E i = l o g ( G i / B i G t o t a l / B t o t a l ) WOE_i=log(\frac{G_i/B_i}{G_{total}/B_{total}}) WOEi=log(Gtotal/BtotalGi/Bi)
WOE也可以这么理解,他表示的是当前这个组中响应的客户和未响应客户的比值,和所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。
WOE编码的意义
1、符号与好坏样本的比例有关
2、要求回归系数为负(当好样本占比在分子上,坏样本占比在分母上时)
变量筛选
变量筛选的方法有:
- 带约束:LASSO
- 特征重要性:随机森林
- 特征信息度:information value
- 模型拟合优度和复杂度:基于AIC的逐步回归
特征信息度
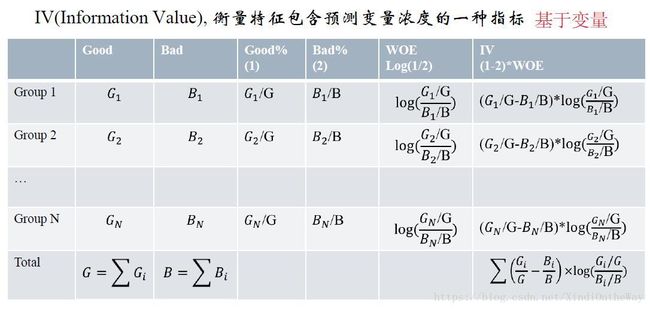
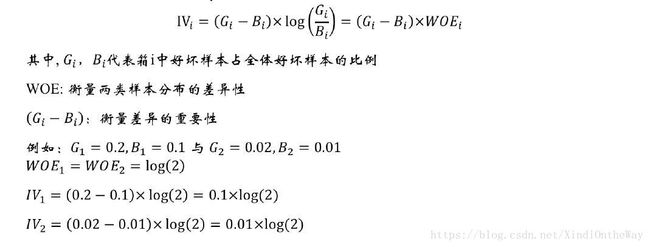
我们可以看到IV值其实是woe值加权求和。这个加权主要是消除掉各分组中数量差异带来的误差。

def CalcWOE(df, col, target):
'''
:param df: 包含需要计算WOE的变量和目标变量
:param col: 需要计算WOE、IV的变量,必须是分箱后的变量,或者不需要分箱的类别型变量
:param target: 目标变量,0、1表示好、坏
:return: 返回WOE和IV
'''
total = df.groupby([col])[target].count()
total = pd.DataFrame({'total': total})
bad = df.groupby([col])[target].sum()
bad = pd.DataFrame({'bad': bad})
regroup = total.merge(bad, left_index=True, right_index=True, how='left')
regroup.reset_index(level=0, inplace=True)
N = sum(regroup['total'])
B = sum(regroup['bad'])
regroup['good'] = regroup['total'] - regroup['bad']
G = N - B
regroup['bad_pcnt'] = regroup['bad'].map(lambda x: x*1.0/B)
regroup['good_pcnt'] = regroup['good'].map(lambda x: x * 1.0 / G)
regroup['WOE'] = regroup.apply(lambda x: np.log(x.good_pcnt*1.0/x.bad_pcnt),axis = 1)
WOE_dict = regroup[[col,'WOE']].set_index(col).to_dict(orient='index')
for k, v in WOE_dict.items():
WOE_dict[k] = v['WOE']
IV = regroup.apply(lambda x: (x.good_pcnt-x.bad_pcnt)*np.log(x.good_pcnt*1.0/x.bad_pcnt),axis = 1)
IV = sum(IV)
return {"WOE": WOE_dict, 'IV':IV}
单变量分析和多变量分析
单变量分析

多变量分析
多重共线性
