ICML 2019 | 微软提出极低资源下语音合成与识别新方法,小语种也不怕没数据了!...
编者按:目前,人类使用的语言种类有近7000种,然而由于缺乏足够的语音-文本监督数据,绝大多数语言并没有对应的语音合成与识别功能。为此,微软亚洲研究院机器学习组联合微软(亚洲)互联网工程院语音团队在ICML 2019上提出了极低资源下的语音合成与识别新方法,帮助所有人都可以享受到最新语音技术带来的便捷。
基于文本的语音合成(Text-to-Speech, TTS)和自动语音识别(Automatic Speech Recognition, ASR)是语音处理中的两个典型任务。得益于深度学习的发展和大量配对的语音-文本监督数据,TTS和ASR在特定的语言上都达到了非常优秀的性能,甚至超越了人类的表现。然而,由于世界上大部分语言都缺乏大量配对的语音-文本数据,并且收集这样的监督数据需要耗费大量的资源,这使得在这些语言上开发TTS和ASR系统变得非常困难。为了解决这个问题,微软亚洲研究院机器学习组联合微软(亚洲)互联网工程院语音团队提出了一种极低资源下的语音合成和识别的新模型方法,仅利用20分钟语音-文本监督数据以及额外的无监督数据,就能生成高可懂度的语音。
TTS将文本转成语音,而ASR将语音转成文字,这两个任务具有对偶性质。受到这个启发,我们借鉴无监督机器翻译的相关思路,利用少量的配对语音-文本数据以及额外的不配对数据,提出了一种接近无监督的TTS和ASR方法。
首先,我们利用自我监督学习的概念,让模型分别建立对语言以及语音的理解建模能力。具体来说,我们基于不成对的语音和文本数据,利用去噪自动编码器(Denoising Auto-Encoder, DAE)在编码器-解码器框架中重建人为加有噪声的语音和文本。
其次,我们使用对偶转换(Dual Transformation, DT),来分别训练模型将文本转为语音和将语音转为文本的能力:(a)TTS模型将文本X转换为语音Y,然后ASR模型利用转换得到语音-文本数据(Y,X)进行训练; (b)ASR模型将语音Y转换为文本X,然后TTS模型利用文本-语音数据(X,Y)进行训练。对偶转换在TTS和ASR之间不断迭代,逐步提高两个任务的准确性。
考虑到语音序列通常比其它序列学习任务(如机器翻译)的序列更长,它们将更多地受到错误传播的影响(在自回归模型生成序列时,序列中上一个错误生成的元素将会对下一个元素的生成产生影响)。因此,生成序列的右侧部分通常比左侧部分差,然后通过训练迭代导致模型生成的序列始终表现为右侧差。在低资源的场景下,这种现象更为严重。因此,我们进一步利用文本和语音的双向序列建模(Bidirectional Sequence Modeling, BSM)来缓解错误传播问题。这样,一个文本或语音序列可以从左到右生成,也可以从右到左生成,能防止模型始终生成某一侧较差的序列。
最后,我们设计了一个基于Transformer的统一模型架构,可以将语音或文本作为输入或输出,以便将上述DAE、DT、BSM模块整合在一起以实现TTS和ASR的功能。
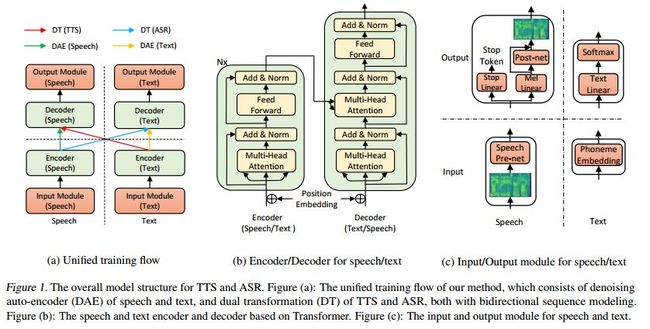
如上图所示,图(a)描述了DAE和DT的转换流程,图(b)展示了我们采用的Transformer模型结构,图(c)显示了语音和文本的输入输出处理模块。
为了验证这一方法的有效性,我们在英语上模拟低资源的场景,选用LJSpeech数据集进行实验,LJSpeech包含13100个英语音频片段和相应的文本,音频的总长度约为24小时。我们将数据集分成3组:300个样本作为验证集,300个样本作为测试集,剩下的12500个样本用来训练。在这12500个样本中,我们随机选择200个配对的语音和文本数据,剩下的数据当作不配对的语音文本数据。
我们邀请了30个专业评估员对生成的声音进行可懂度(Intelligibility Rate)以及MOS(Mean Opinion Score,平均主观意见分)评测。MOS指标用来衡量声音接近人声的自然度,在极低资源场景下,我们一般用可懂度来评估是否能产生可理解的声音。
经过实验,我们提出的方法可以产生可理解的语音,其单词级的可懂度高达99.84%,而如果仅对200个配对数据进行训练,则几乎无法产生可以被听懂的语音,这显示出我们方法在极低资源场景下的实用性。
下面展示了我们方法合成的声音Demo:
文字:“The forms of printed letters should be beautiful and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves.”
Demo
更多Demo声音,请访问:
https://speechresearch.github.io/unsuper/

长按扫码,查看Demo
语音合成上的MOS得分以及语音识别的PER(Phoneme Error Rate,音素错误率)如下表所示。我们的方法在TTS上达到2.68的MOS,在ASR上达到11.7%的PER,远优于仅在200个配对数据上训练的基线模型(Pair-200),并且接近使用所有训练样本的监督模型(Supervised)。由于我们的语音合成仅使用了效果较差的Griffin-Lim作为声码器合成声音,作为对比,我们也列出了真实样本(Ground Truth, GT)以及真实样本的梅尔频谱图通过Griffin-Lim转换得到的声音(GT(Griffin-Lim))的MOS得分作参考。
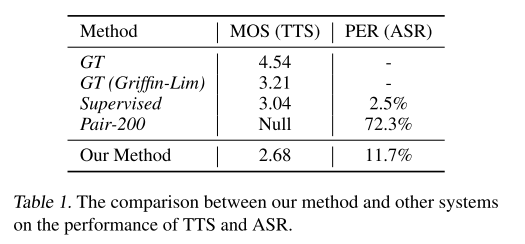
为了研究我们方法中每个模块的有效性,我们通过逐步将每个模块添加到基线(Pair-200)系统进行对比研究。实验中先后添加了以下模块:去噪自编码器(DAE)、对偶变换(DT)和双向序列建模(BSM),结果如下表所示。可以看到,随着更多模块的加入,TTS的MOS得分以及ASR的PER都稳定地提高,显示出各个模块的重要性。

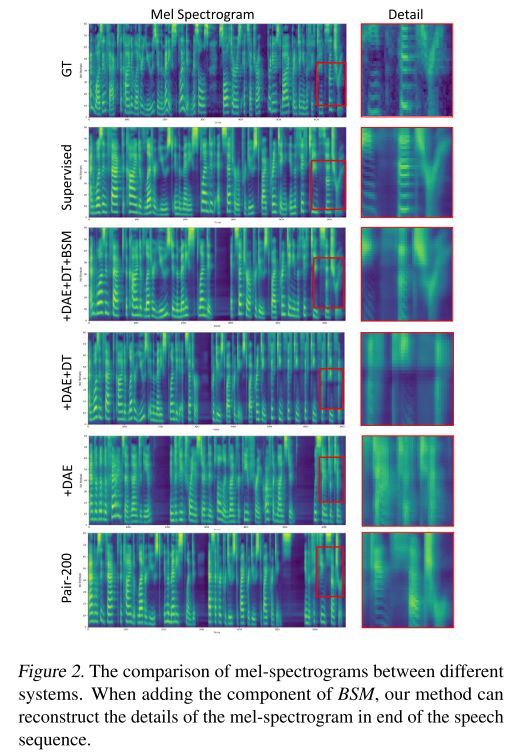
我们还可视化了测试集中由不同系统生成的梅尔频谱图,如下图所示。由于Pair-200和Pair-200 + DAE不能产生能被理解的语音,因此红色边界框中的梅尔频谱图的细节也与真实频谱大不相同。当添加DT时,整个频谱图更接近真实频谱图,然而受到误差传播的影响,位于频谱图序列末尾的红色边界框细节仍然与真实数据不同。当进一步添加BSM时,边界框中的细节比较接近真实数据,这也证明了BSM在我们的方法中的有效性。当然如果使用LJSpeech的全部配对数据进行监督训练,模型可以重建更接近真实情况的细节。
我们的方法仅利用约20分钟的语音-文本配对数据,以及额外的不配对数据,在英语上取得了很好的效果,产生了高可懂度的语音。当前,我们正在持续提高这一方法的性能,直接支持文本字符的输入而不是先将字符转化为音素作为输入,同时支持多个说话人的无监督语音数据。我们还在尝试利用更少的语音-文本数据(甚至完全不用配对数据)以实现高质量的语音合成与语音识别。未来,我们将利用这项技术支持其它低资源语言,让更多的语言拥有语音合成与识别功能。
论文地址
详细内容请查阅论文,论文地址:https://speechresearch.github.io/papers/almost_unsup_tts_asr_2019.pdf

长按扫码,查看论文
我们也将在不久后开放论文源代码,敬请关注!
作者简介

谭旭,微软亚洲研究院机器学习组研究员,主要研究兴趣为机器学习算法及其在自然语言、语音领域中的应用,研究成果发表在ICML、NIPS、ICLR、AAAI、ACL、EMNLP、NAACL等会议上。
你也许还想看:



![]()
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:[email protected]。