什么是http及RFC?
这几天,阅读RFC2616认真学习一遍HTTP/1.1协议,一直认为要做互联网开发的话,一定要对于HTTP协议烂熟于胸,于是下定决心要将这个协议好好理解一遍。这两天,工作之余,拿着RFC就在那里读,对于HTTP协议有了不错的理解,对于其中的字段与机制有了一定的理解,于是静下心来,好好总结一下这两天的阅读收获,同时也是一个回顾复习。
HTTP协议描述的是发送方与接收方的通信协议,通过两方的自觉遵守而存在,当然有不少的浏览器并没有百分百遵守这份协议。HTTP是运行于应用层的协议,基于TCP协议而运作。基本上是客户/服务器对答模式,其中也包括在传输过程中的代理,网关,通道,缓存等都需要遵守这份协议。
阅读完RFC之后,较为难以理解的部分是关于连接机制与缓存机制,其他都基本上是字段与头部格式的定义,在里面就不一一列举,提供一个快查的网址:Quick reference to HTTP headers;
主要有两种比较重要的机制,在这里总结一下:
一, 连接机制;
HTTP/1.1支持两种连接机制,一种是非持久连接,第二种是持久连接。基本上默认是使用持久连接,因为这样能够减少建立连接时候的网络延时与CPU消耗。其中服务器与客户端都会假定连接没有关闭,除非对方传来的头文件包含" Connection:close",不然连接将继续保持。客户端,服务器与代理都可以随时结束连接,而他们也应该有一套机制去重新搭建起连接,并保持正确性。每个客户端也只能与一个服务器保持两条连接。代理也只能保持2N条连接,N 为代理的活跃用户数。对于连接的时候,由用户向服务器端发送一个带有"Expect"的信息到服务器端,服务器端如果连接正常则返回一个100 ( continue )的信息到客户端,提示客户端可以继续发送。
HTTP对于传输道路上的元素也有一定的要求。也规定了不透明代理可以改变哪些字段,而不能改变哪些字段。
二.缓存机制;
HTTP中使用缓存主要有两个作用,一个是在很多情况下可以减少发送包,减少网络IO,使用“过期”机制来处理;第二个是可以减少发送整包的操作,减少带宽需求,使用“验证”机制来处理。
(1)“过期”机制(Expiration Model),用于服务器端制定一个“过期时间”,主要有两种计算方式,按优先级顺序,第一种是年龄(Age),第二种是过期时间(Expiration)。对于第一种,服务器会提供一个年龄字段(Age)与一个有效年龄(max-age),而年龄的计算,则是采用服务器生成时的初始年龄再加上从服务器生成至缓存的时间。如果有Age 这个字段的存在,则说明这个消息不是第一手的,中间有缓存的存在。而要计算一个消息是否过期,则需要采用以下的方法:
if( max_age_value )
Freshness_lifetime = max_age_value ;
Else
Freshness_lifetime = expires_value - date_value ;
Response_is_fresh = ( freshness_lifetime > current_age ) ;
总体计算方法都比较直观与简单,而如果需要更新缓存的话,则可以加入以下字段:
Cache-Control : max-age = 0 ; OR Cache-Control : no-cache ;
(2)验证机制(Validation Model ) ,采用这种机制的时候,缓存先向服务器验证当前的缓存条目是否最新的,则收到304的提示表示 Not Modified,条目是最新的。否则则会收到服务器返回的新缓存条目。而进行验证的时候,可以使用两个标准,一个是使用服务器在原条目上的"Last-Modified",使用条件GET(If-Modified-Since OR If-Not-Modified-Since)去查询。第二个是使用服务器为每个条目生成的"Entity Tag",这个Tag如何生成完成由服务器去决定,因此也衍生出两种验证策略,一种是强验证,即如果一个条目发生了改变之后"Entity Tag"也马上变化的,第二种是使用弱验证,即条目变化了"Entity Tag"仍然保持不变,相对验证条件更弱。而对于是使用强验证还是弱验证则是取决于服务器端了。
以前对于HTTP和FTP也是有所了解的,看了一遍英文版的RFC文档,虽然很痛苦,但是感觉是有所不同的。
1,HTTP所表达的控制以及描述性相关的信息都包含在了HTTP的起始行和首部之中。BNF的使用使得自己能够清晰的梳理出起始行和首部中所有类别的元信息。对于每一类的元信息具体包含哪些内容也能够有所了解。这一抽象的方法不仅HTTP协议定义的时候比较严谨之外,在实现HTTP解析器(浏览器)的时候参照BNF写代码是非常容易实现的。这也提醒了我们在编写相关的系统设计方案的时候是可以借鉴类似的方法的。毕竟使用文字表述的设计方案存在这问题遗漏,表述不够清晰,不同人理解有所差异等方面的问题。(我们会看到在FTP之中也有类似的方法,状态图)。HTTP被设计成为一种非常容易扩展的协议,因此协议时松散的。头域可以加入需要的头部名和指定的值,尽管有的头部没有加入RFC标准,但是可能成为约定成俗的标准(虽然这会给HTTP的安全性带来了挑战),由此可以看出良好的设计方案在一开始的时候就考虑到其以扩展性,这也是HTTP能够长期存在,不断发展的原因。
2,FTP采用的是控制和数据相分离的模式实现文件的传送。首先这一设计思想在程序的设计之中本身就很常见。FTP采用的是命令+响应码的形式来控制文件传输的功能,若干条命令+不同类别的响应码会导致不同的结果,其组合方式多种多样,但是FTP的RFC文档给出了这些组合的状态图。六种类型的状态图覆盖了FTP可能的所有情况。前面我们提到HTTP的BNF表示方法利于编写程序,这里的状态图同样给出了编写完备FTP软件的指导性方法。当然状态图也可以看出有的命令是有先后顺序的,但是大多数的命令是没有此要求的。
3,RTSP可以说基本复用了HTTP的设计思路,从请求和响应的消息组成可以清晰的看出。但是其也借鉴了FTP中相关的优秀思想。比如数据和控制的分离,RTSP的数据传输就是由RTP/RTCP等协议去实现的。在HTTP中,请求响应模式采用的是CS的模式,即客户端发起请求,服务器应答响应。FTP的就发生了变化,首先在FTP的架构之中存在这一个客户端控制这两个服务器的通信。两个SERVER的通信以及在FTP中的Port模式下(数据连接是由服务器发起的),这两种情况跟HTTP就很不相同。至于到了RTSP请求是双向的。
总的来说三种协议都是基于文本的应用层协议,基于文本的协议在需要某些属性、方法或者命令的时候能够比较方便的添加。相对与传输层以及网络层(虽然也有扩展)来说,固定的位置表达的含义是确定的,基于文本的协议比较灵活多变。当然协议最基本的分层原则也在HTTP,FTP以及RTSP中有所体现,即应用层协议应尽量减少其与下层之间的耦合性。虽然常见的HTTP都是基于TCP协议的,但是HTTP并不关心整个HTTP消息在传输层如何使用的。
一、概述
1.1 五层模型
互联网的实现,分成好几层。每一层都有自己的功能,就像建筑物一样,每一层都靠下一层支持。
用户接触到的,只是最上面的一层,根本没有感觉到下面的层。要理解互联网,必须从最下层开始,自下而上理解每一层的功能。
如何分层有不同的模型,有的模型分七层,有的分四层。我觉得,把互联网分成五层,比较容易解释。
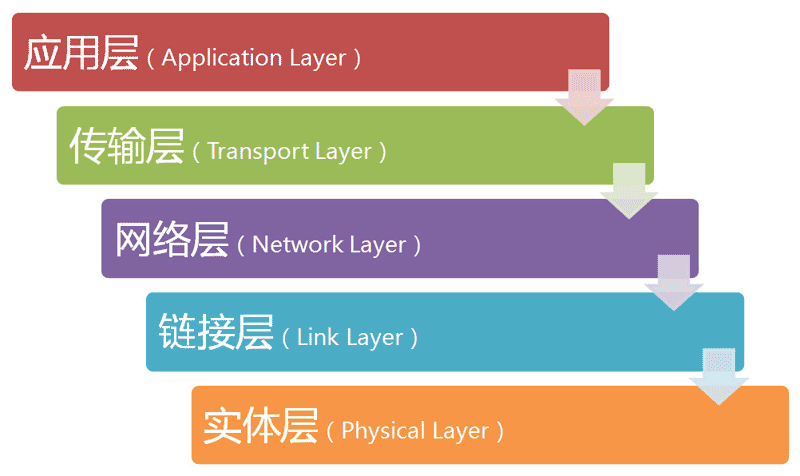
如上图所示,最底下的一层叫做"实体层"(Physical Layer),最上面的一层叫做"应用层"(Application Layer),中间的三层(自下而上)分别是"链接层"(Link Layer)、"网络层"(Network Layer)和"传输层"(Transport Layer)。越下面的层,越靠近硬件;越上面的层,越靠近用户。
它们叫什么名字,其实并不重要。只需要知道,互联网分成若干层就可以了。
1.2 层与协议
每一层都是为了完成一种功能。为了实现这些功能,就需要大家都遵守共同的规则。
大家都遵守的规则,就叫做"协议"(protocol)。
互联网的每一层,都定义了很多协议。这些协议的总称,就叫做"互联网协议"(Internet Protocol Suite)。它们是互联网的核心,下面介绍每一层的功能,主要就是介绍每一层的主要协议。
二、实体层
我们从最底下的一层开始。
电脑要组网,第一件事要干什么?当然是先把电脑连起来,可以用光缆、电缆、双绞线、无线电波等方式。

这就叫做"实体层",它就是把电脑连接起来的物理手段。它主要规定了网络的一些电气特性,作用是负责传送0和1的电信号。
三、链接层
3.1 定义
单纯的0和1没有任何意义,必须规定解读方式:多少个电信号算一组?每个信号位有何意义?
这就是"链接层"的功能,它在"实体层"的上方,确定了0和1的分组方式。
3.2 以太网协议
早期的时候,每家公司都有自己的电信号分组方式。逐渐地,一种叫做"以太网"(Ethernet)的协议,占据了主导地位。
以太网规定,一组电信号构成一个数据包,叫做"帧"(Frame)。每一帧分成两个部分:标头(Head)和数据(Data)。

"标头"包含数据包的一些说明项,比如发送者、接受者、数据类型等等;"数据"则是数据包的具体内容。
"标头"的长度,固定为18字节。"数据"的长度,最短为46字节,最长为1500字节。因此,整个"帧"最短为64字节,最长为1518字节。如果数据很长,就必须分割成多个帧进行发送。
3.3 MAC地址
上面提到,以太网数据包的"标头",包含了发送者和接受者的信息。那么,发送者和接受者是如何标识呢?
以太网规定,连入网络的所有设备,都必须具有"网卡"接口。数据包必须是从一块网卡,传送到另一块网卡。网卡的地址,就是数据包的发送地址和接收地址,这叫做MAC地址。

每块网卡出厂的时候,都有一个全世界独一无二的MAC地址,长度是48个二进制位,通常用12个十六进制数表示。

前6个十六进制数是厂商编号,后6个是该厂商的网卡流水号。有了MAC地址,就可以定位网卡和数据包的路径了。
3.4 广播
定义地址只是第一步,后面还有更多的步骤。
首先,一块网卡怎么会知道另一块网卡的MAC地址?
回答是有一种ARP协议,可以解决这个问题。这个留到后面介绍,这里只需要知道,以太网数据包必须知道接收方的MAC地址,然后才能发送。
其次,就算有了MAC地址,系统怎样才能把数据包准确送到接收方?
回答是以太网采用了一种很"原始"的方式,它不是把数据包准确送到接收方,而是向本网络内所有计算机发送,让每台计算机自己判断,是否为接收方。

上图中,1号计算机向2号计算机发送一个数据包,同一个子网络的3号、4号、5号计算机都会收到这个包。它们读取这个包的"标头",找到接收方的MAC地址,然后与自身的MAC地址相比较,如果两者相同,就接受这个包,做进一步处理,否则就丢弃这个包。这种发送方式就叫做"广播"(broadcasting)。
有了数据包的定义、网卡的MAC地址、广播的发送方式,"链接层"就可以在多台计算机之间传送数据了。
四、网络层
4.1 网络层的由来
以太网协议,依靠MAC地址发送数据。理论上,单单依靠MAC地址,上海的网卡就可以找到洛杉矶的网卡了,技术上是可以实现的。
但是,这样做有一个重大的缺点。以太网采用广播方式发送数据包,所有成员人手一"包",不仅效率低,而且局限在发送者所在的子网络。也就是说,如果两台计算机不在同一个子网络,广播是传不过去的。这种设计是合理的,否则互联网上每一台计算机都会收到所有包,那会引起灾难。
互联网是无数子网络共同组成的一个巨型网络,很像想象上海和洛杉矶的电脑会在同一个子网络,这几乎是不可能的。
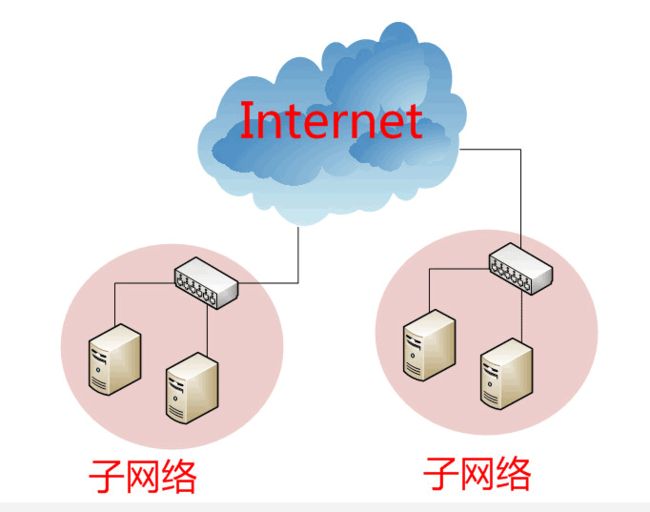
因此,必须找到一种方法,能够区分哪些MAC地址属于同一个子网络,哪些不是。如果是同一个子网络,就采用广播方式发送,否则就采用"路由"方式发送。("路由"的意思,就是指如何向不同的子网络分发数据包,这是一个很大的主题,本文不涉及。)遗憾的是,MAC地址本身无法做到这一点。它只与厂商有关,与所处网络无关。
这就导致了"网络层"的诞生。它的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做"网络地址",简称"网址"。
于是,"网络层"出现以后,每台计算机有了两种地址,一种是MAC地址,另一种是网络地址。两种地址之间没有任何联系,MAC地址是绑定在网卡上的,网络地址则是管理员分配的,它们只是随机组合在一起。
网络地址帮助我们确定计算机所在的子网络,MAC地址则将数据包送到该子网络中的目标网卡。因此,从逻辑上可以推断,必定是先处理网络地址,然后再处理MAC地址。
4.2 IP协议
规定网络地址的协议,叫做IP协议。它所定义的地址,就被称为IP地址。
目前,广泛采用的是IP协议第四版,简称IPv4。这个版本规定,网络地址由32个二进制位组成。

习惯上,我们用分成四段的十进制数表示IP地址,从0.0.0.0一直到255.255.255.255。
互联网上的每一台计算机,都会分配到一个IP地址。这个地址分成两个部分,前一部分代表网络,后一部分代表主机。比如,IP地址172.16.254.1,这是一个32位的地址,假定它的网络部分是前24位(172.16.254),那么主机部分就是后8位(最后的那个1)。处于同一个子网络的电脑,它们IP地址的网络部分必定是相同的,也就是说172.16.254.2应该与172.16.254.1处在同一个子网络。
但是,问题在于单单从IP地址,我们无法判断网络部分。还是以172.16.254.1为例,它的网络部分,到底是前24位,还是前16位,甚至前28位,从IP地址上是看不出来的。
那么,怎样才能从IP地址,判断两台计算机是否属于同一个子网络呢?这就要用到另一个参数"子网掩码"(subnet mask)。
所谓"子网掩码",就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.254.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道"子网掩码",我们就能判断,任意两个IP地址是否处在同一个子网络。方法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知IP地址172.16.254.1和172.16.254.233的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算,结果都是172.16.254.0,因此它们在同一个子网络。
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
4.3 IP数据包
根据IP协议发送的数据,就叫做IP数据包。不难想象,其中必定包括IP地址信息。
但是前面说过,以太网数据包只包含MAC地址,并没有IP地址的栏位。那么是否需要修改数据定义,再添加一个栏位呢?
回答是不需要,我们可以把IP数据包直接放进以太网数据包的"数据"部分,因此完全不用修改以太网的规格。这就是互联网分层结构的好处:上层的变动完全不涉及下层的结构。
具体来说,IP数据包也分为"标头"和"数据"两个部分。

"标头"部分主要包括版本、长度、IP地址等信息,"数据"部分则是IP数据包的具体内容。它放进以太网数据包后,以太网数据包就变成了下面这样。

IP数据包的"标头"部分的长度为20到60字节,整个数据包的总长度最大为65,535字节。因此,理论上,一个IP数据包的"数据"部分,最长为65,515字节。前面说过,以太网数据包的"数据"部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
4.4 ARP协议
关于"网络层",还有最后一点需要说明。
因为IP数据包是放在以太网数据包里发送的,所以我们必须同时知道两个地址,一个是对方的MAC地址,另一个是对方的IP地址。通常情况下,对方的IP地址是已知的(后文会解释),但是我们不知道它的MAC地址。
所以,我们需要一种机制,能够从IP地址得到MAC地址。
这里又可以分成两种情况。第一种情况,如果两台主机不在同一个子网络,那么事实上没有办法得到对方的MAC地址,只能把数据包传送到两个子网络连接处的"网关"(gateway),让网关去处理。
第二种情况,如果两台主机在同一个子网络,那么我们可以用ARP协议,得到对方的MAC地址。ARP协议也是发出一个数据包(包含在以太网数据包中),其中包含它所要查询主机的IP地址,在对方的MAC地址这一栏,填的是FF:FF:FF:FF:FF:FF,表示这是一个"广播"地址。它所在子网络的每一台主机,都会收到这个数据包,从中取出IP地址,与自身的IP地址进行比较。如果两者相同,都做出回复,向对方报告自己的MAC地址,否则就丢弃这个包。
总之,有了ARP协议之后,我们就可以得到同一个子网络内的主机MAC地址,可以把数据包发送到任意一台主机之上了。
五、传输层
5.1 传输层的由来
有了MAC地址和IP地址,我们已经可以在互联网上任意两台主机上建立通信。
接下来的问题是,同一台主机上有许多程序都需要用到网络,比如,你一边浏览网页,一边与朋友在线聊天。当一个数据包从互联网上发来的时候,你怎么知道,它是表示网页的内容,还是表示在线聊天的内容?
也就是说,我们还需要一个参数,表示这个数据包到底供哪个程序(进程)使用。这个参数就叫做"端口"(port),它其实是每一个使用网卡的程序的编号。每个数据包都发到主机的特定端口,所以不同的程序就能取到自己所需要的数据。
"端口"是0到65535之间的一个整数,正好16个二进制位。0到1023的端口被系统占用,用户只能选用大于1023的端口。不管是浏览网页还是在线聊天,应用程序会随机选用一个端口,然后与服务器的相应端口联系。
"传输层"的功能,就是建立"端口到端口"的通信。相比之下,"网络层"的功能是建立"主机到主机"的通信。只要确定主机和端口,我们就能实现程序之间的交流。因此,Unix系统就把主机+端口,叫做"套接字"(socket)。有了它,就可以进行网络应用程序开发了。
5.2 UDP协议
现在,我们必须在数据包中加入端口信息,这就需要新的协议。最简单的实现叫做UDP协议,它的格式几乎就是在数据前面,加上端口号。
UDP数据包,也是由"标头"和"数据"两部分组成。

"标头"部分主要定义了发出端口和接收端口,"数据"部分就是具体的内容。然后,把整个UDP数据包放入IP数据包的"数据"部分,而前面说过,IP数据包又是放在以太网数据包之中的,所以整个以太网数据包现在变成了下面这样:

UDP数据包非常简单,"标头"部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
5.3 TCP协议
UDP协议的优点是比较简单,容易实现,但是缺点是可靠性较差,一旦数据包发出,无法知道对方是否收到。
为了解决这个问题,提高网络可靠性,TCP协议就诞生了。这个协议非常复杂,但可以近似认为,它就是有确认机制的UDP协议,每发出一个数据包都要求确认。如果有一个数据包遗失,就收不到确认,发出方就知道有必要重发这个数据包了。
因此,TCP协议能够确保数据不会遗失。它的缺点是过程复杂、实现困难、消耗较多的资源。
TCP数据包和UDP数据包一样,都是内嵌在IP数据包的"数据"部分。TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
六、应用层
应用程序收到"传输层"的数据,接下来就要进行解读。由于互联网是开放架构,数据来源五花八门,必须事先规定好格式,否则根本无法解读。
"应用层"的作用,就是规定应用程序的数据格式。
举例来说,TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了"应用层"。
这是最高的一层,直接面对用户。它的数据就放在TCP数据包的"数据"部分。因此,现在的以太网的数据包就变成下面这样。
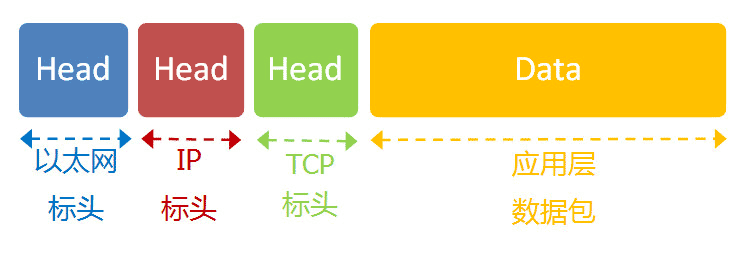
至此,整个互联网的五层结构,自下而上全部讲完了。这是从系统的角度,解释互联网是如何构成的。下一篇,我反过来,从用户的角度,自上而下看看这个结构是如何发挥作用,完成一次网络数据交换的。
本文介绍如何将一个 HTTP 网站升级到 HTTPS 。

一、获取证书
升级到 HTTPS 协议的第一步,就是要获得一张证书。
证书是一个二进制文件,里面包含经过认证的网站公钥和一些元数据,要从经销商购买。
- GoGetSSL
- SSLs.com
- SSLmate.com
证书有很多类型,首先分为三种认证级别。

- 域名认证(Domain Validation):最低级别认证,可以确认申请人拥有这个域名。对于这种证书,浏览器会在地址栏显示一把锁。
- 公司认证(Company Validation):确认域名所有人是哪一家公司,证书里面会包含公司信息。
- 扩展认证(Extended Validation):最高级别的认证,浏览器地址栏会显示公司名。
还分为三种覆盖范围。
- 单域名证书:只能用于单一域名,
foo.com的证书不能用于www.foo.com- 通配符证书:可以用于某个域名及其所有一级子域名,比如
*.foo.com的证书可以用于foo.com,也可以用于www.foo.com- 多域名证书:可以用于多个域名,比如
foo.com和bar.com
认证级别越高、覆盖范围越广的证书,价格越贵。
还有一个免费证书的选择。为了推广HTTPS协议,电子前哨基金会EFF成立了 Let's Encrypt,提供免费证书(教程和工具)。
拿到证书以后,可以用 SSL Certificate Check 检查一下,信息是否正确。
二、安装证书
证书可以放在/etc/ssl目录(Linux 系统),然后根据你使用的Web服务器进行配置。
- 证书配置文件生成器,by Mozilla
- 配置文件模板,by SSLMate
如果使用 Let's Encrypt 证书,请使用自动安装工具 Certbot。
安装成功后,使用 SSL Labs Server Test 检查一下证书是否生效。
三、修改链接
下一步,网页加载的 HTTP 资源,要全部改成 HTTPS 链接。因为加密网页内如果有非加密的资源,浏览器是不会加载那些资源的。
<script src="http://foo.com/jquery.js">script>
上面这行加载命令,有两种改法。
<script src="https://foo.com/jquery.js">script> <script src="//foo.com/jquery.js">script>
其中,改法二会根据当前网页的协议,加载相同协议的外部资源,更灵活一些。
另外,如果页面头部用到了rel="canonical",也要改成HTTPS网址。
<link rel="canonical" href="https://foo.com/bar.html" />
四、301重定向
下一步,修改 Web 服务器的配置文件,使用 301 重定向,将 HTTP 协议的访问导向 HTTPS 协议。
Nginx 的写法。
server { listen 80; server_name domain.com www.domain.com; return 301 https://domain.com$request_uri; }
Apache 的写法(.htaccess文件)。
RewriteEngine On RewriteCond %{HTTPS} off RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
五、安全措施
以下措施可以进一步保证通信安全。
5.1 HTTP Strict Transport Security (HSTS)
访问网站时,用户很少直接在地址栏输入https://,总是通过点击链接,或者3xx重定向,从HTTP页面进入HTTPS页面。攻击者完全可以在用户发出HTTP请求时,劫持并篡改该请求。
另一种情况是恶意网站使用自签名证书,冒充另一个网站,这时浏览器会给出警告,但是许多用户会忽略警告继续访问。
"HTTP严格传输安全"(简称 HSTS)的作用,就是强制浏览器只能发出HTTPS请求,并阻止用户接受不安全的证书。
它在网站的响应头里面,加入一个强制性声明。以下例子摘自维基百科。
Strict-Transport-Security: max-age=31536000; includeSubDomains
上面这段头信息有两个作用。
(1)在接下来的一年(即31536000秒)中,浏览器只要向
example.com或其子域名发送HTTP请求时,必须采用HTTPS来发起连接。用户点击超链接或在地址栏输入http://www.example.com/,浏览器应当自动将http转写成https,然后直接向https://www.example.com/发送请求。(2)在接下来的一年中,如果
example.com服务器发送的证书无效,用户不能忽略浏览器警告,将无法继续访问该网站。
HSTS 很大程度上解决了 SSL 剥离攻击。只要浏览器曾经与服务器建立过一次安全连接,之后浏览器会强制使用HTTPS,即使链接被换成了HTTP。
该方法的主要不足是,用户首次访问网站发出HTTP请求时,是不受HSTS保护的。
如果想要全面分析网站的安全程度,可以使用 Mozilla 的 Observatory。
5.2 Cookie
另一个需要注意的地方是,确保浏览器只在使用 HTTPS 时,才发送Cookie。
网站响应头里面,Set-Cookie字段加上Secure标志即可。
Set-Cookie: LSID=DQAAAK...Eaem_vYg; Secure