收视率系统
一、项目背景
对《中国好声音》、《快乐男声》、《最美和声》、《中国梦之声》等各种音乐选节目收视率的一个调查。依托北330万高清交互数字电视双向用户,从中随机抽取25000户作为样本进行统计。
二、项目需求
这里展示从节目的维度,统计每个节目的平均收视人数、平均到达人数、收视率、到达率和市场份额。我们根据每天抽样用户的收视数据,统计出每个节目按天、按小时、按分钟的上述5个收视指标。
三、 系统功能(这里以一个维度为例)
主要包括收视概况浏览、收视率走势分析、收视指标对比、收视数据对比查看。
五、 收视指标定义
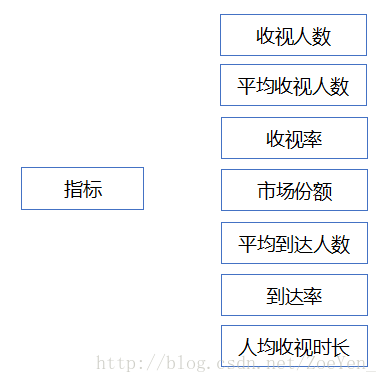
收视人数
总的:某天收视人数(S11):sum(distinct stbnum) WHERE 指定日期。
频道:某天收视人数(S21):sum(distinct stbnum) WHERE 指定日期 AND 指定频道。
节目(这1天内收看此节目的人数):某天收视人数(S31):sum(distinct stbnum) WHERE 指定日期 AND 指定节目。
平均收视人数
该指标为在选定期间内平均每分钟的用户ID数。
总的:
每分钟(X11): sum(distinct stbnum)
每分钟(X12):……
每分钟(X1n):……
平均收视人数:(X11 + X12 + … + X1n)/n
频道:
每分钟(X21): sum(distinct stbnum) where 指定频道名称 = 频道名
每分钟(X22):……
每分钟(X2n):……
平均收视人数:(X21 + X22 + … + X2n)/n
节目:
每分钟(X31): sum(distinct stbnum) where 指定节目名称 = 节目名
每分钟(X32):……
每分钟(X3n):……
平均收视人数:(X31 + X32 + … + X3n)/n
收视率
平均收视人数/系统总ID数。
CONSTANT系统总ID数 IDNUM = sum(distinct stbnum)。
总的,频道,节目:
每分钟收视率Y1:X1/IDNUM;
每分钟收视率Y2:……
每分钟收视率Yn:Xn/IDNUM
某一段时间的收视率:(Y1 + Y2… + Yn)/n
市场份额
对应频道平均收视人数/所有频道平均收视人数。
总体:
100%
频道:
每分钟(Z21):X21/ sum(distinct stbnum) where 时间
……
每分钟(Z2n):X2n/ sum(distinct stbnum) where 时间
市场份额:(Z21 + … + Z2n)/n
节目:
每分钟(Z31):X31/ sum(distinct stbnum) where 时间
……
每分钟(Z3n):X3n/ sum(distinct stbnum) where 时间
市场份额:(Z31 + … + Z3n)/n
平均到达人数
默认扣除在某个频道或整个系统停留时间小于60s的用户ID,不包括60s,跟平均收视人数的差别在于排除原始记录中停留时间小于60s的记录。
总的:
每分钟(U11): sum(distinct stbnum) WHERE ((a_e – a_s)>=60)
每分钟(U12):……
每分钟(U1n):……
平均到达人数:(U11 + U12 + … + U1n)/n
频道:
每分钟(U21): sum(distinct stbnum) where 指定频道名称 = 频道名 AND ((a_e – a_s)>=60)
每分钟(U22):……
每分钟(U2n):……
平均到达人数:(U21 + U22 + … + U2n)/n
节目:
每分钟(U31): sum(distinct stbnum) where 指定节目名称 = 节目名 AND ((a_e – a_s)>=60)
每分钟(U32):……
每分钟(U3n):……
平均到达人数:(U31 + U32 + … + U3n)/n
到达率
平均到达人数/系统总ID数。
CONSTANT系统总ID数 IDNUM = sum(distinct stbnum)。
总的,频道,节目:
每分钟(V1):U1/ IDNUM
……
每分钟(Vn):Un/ IDNUM
某一段时间的到达率:(V1 + V2 + … + Vn)/n
人均收视时长
所有频道 —— 每天所有用户ID的总时间/用户ID数;具体某个频道 —— 访问过该频道的所有用户ID每天总时间/该频道每天的用户ID数;具体某个栏目 —— 访问过每期节目的所有用户ID总时间/该栏目的用户ID数。
总的:
某天人均收视时长(W11):SUM(a_e – a_s)/S11
频道:
某天人均收视时长(W21):SUM(a_e – a_s)/S21
节目:
某天人均收视时长(W31):SUM(a_e – a_s)/S31
六、开发流程
1.通过flume收集工具将用户产生的原始数据收集到hdfs分布式文件系统。
2.编写MR程序对原始的收视数据进行解析、清洗、提取业务所需的有效字段。
3.利用hive工具将MR处理后的数据导入数据仓库,同时对该数据进行统计分析。
4.编写应用程序或者使用sqoop工具将hive分析的最终数据导入数据库,比如mysql数据库。
5.前端查询,实现数据的可视化。
七.源数据
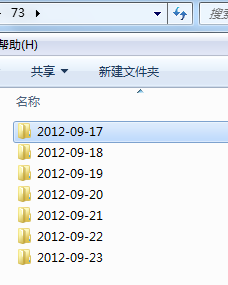


利用hdfs的小文件合并MergeSmallFilesToHDFS.java将每天的小文件合并为大文件,具体参考http://blog.csdn.net/zoeyen_/article/details/78947676
八、将源数据上传到hdfs文件系统
这里使用flume采集工具,我将flume工具安装在主节点(pc1)上,仅使用了一层agent。
①启动集群

②修改flume的配置文件
[hadoop@pc1 conf]$ vi flume-conf.properties
agent1.channels = ch1
agent1.sinks = sink1
# Define and configure an Spool directory source(使用spooldir监控日志目录)
agent1.sources.source1.channels = ch1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/tvdata
#前三项必须配置,具体参数可参考官方文档
agent1.sources.source1.ignorePattern = event(_\d{4}\-\d{2}\-\d{2}_\d{2}_\d{2})?\.log(\.COMPLETED)?
agent1.sources.source1.deserializer.maxLineLength = 10240
#配置收集每行数据的最大长度
# Configure channel(channel 选择file,防止数据丢失)
agent1.channels.ch1.type = file
#也可以配置内存
agent1.channels.ch1.checkpointDir = /home/hadoop/app/flume/checkpointDir
agent1.channels.ch1.dataDirs = /home/hadoop/app/flume/dataDirs
#在flume目录下创建以上两个路径
# Define and configure a hdfs sink(数据采集到hdfs)
agent1.sinks.sink1.channel = ch1
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path =
hdfs://pc1:9000/home/app/tvdata/%Y%m%d
#如果是集群就配置对外提供服务的地址
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
agent1.sinks.sink1.hdfs.rollInterval = 300
agent1.sinks.sink1.hdfs.rollSize = 67108864
agent1.sinks.sink1.hdfs.rollCount = 0
#agent1.sinks.sink1.hdfs.codeC = snappy #没有做snappy压缩
③创建路径

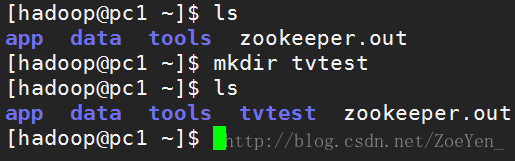
④将源数据上传到tvtest目录下

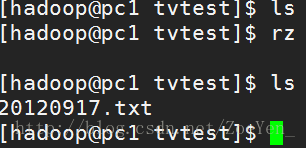
⑤进入flume安装目录,执行运行命令
[hadoop@node2 flume]$bin/flume-ng agent -n agent1 -c conf -f conf/flume-conf.properties ⑥查看
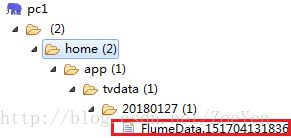
出现乱码
查看官方文档,hdfs.fileType默认为SequenceFil,改为datastream就可以按原样输出数据到hdfs。


删除已经采集到hdfs的数据,重新采集
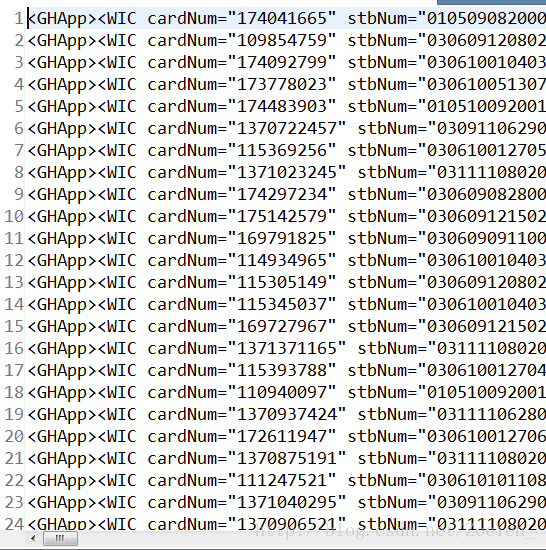
九、 编写MR程序对原始的收视数据进行解析、清洗、提取业务需要的有效字段
①对源数据进行预处理,提取需要的数据。编写一个只有mapper的mapreduce程序,调用一个DataUtil接口,这个接口引用了jsoup的jar包,来解析源数据的每一行数据,将机顶盒号和日期作为输出key,其它作为输出value。其中日期的解析由TimeUtil这个类实现。
/*
* 解析机顶盒用户原始数据
*/
public class ParseAndFilterLog extends Configured implements Tool {
/*
* 只需Mapper完成原始数据解析
*/
public static class ExtractTVMsgLogMapper extends
//Mapper<LongWritable, BytesWritable, Text, Text> {
Mapper {
//public void map(LongWritable key, BytesWritable value, Context context)
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 原始数据
//String data = new String(value.getBytes(), 0, value.getLength());
String data = value.toString();
// 调用接口直接解析出我们需要数据格式
// stbNum + "@" + date + "@" + sn + "@" + p+ "@" + s + "@" + e + "@"
// + duration
DataUtil.transData(data, context);
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: ParseAndFilterLog [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set("mapreduce.output.textoutputformat.separator", "@");
job.setJarByClass(ParseAndFilterLog.class);
job.setMapperClass(ExtractTVMsgLogMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//job.setInputFormatClass(SequenceFileInputFormat.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),new ParseAndFilterLog(), args);
System.exit(ec);
}
}
/**
*
* 解析机顶盒用户原始数据
*
*
*
*
*
*
*/
public class DataUtil {
@SuppressWarnings("unchecked")
public static void transData(String text,Context context) {
try {
//通过Jsoup解析每行数据
Document doc = Jsoup.parse(text);
//获取WIC标签内容,每行数据只有一个WIC标签
Elements content = doc.getElementsByTag("WIC");
//解析出机顶盒号
String stbNum = content.get(0).attr("stbNum");
if(stbNum == null||"".equals(stbNum)){
return ;
}
//解析出日期
String date = content.get(0).attr("date");
if(date == null||"".equals(date)){
return ;
}
//解析A标签
Elements els = doc.getElementsByTag("A");
for (Element el : els) {
//解析结束时间
String e = el.attr("e");
if(e ==null||"".equals(e)){
break;
}
//解析起始时间
String s = el.attr("s");
if(s == null||"".equals(s)){
break;
}
//解析节目内容
String p = el.attr("p");
if(p == null||"".equals(p)){
break;
}
//解析频道
String sn = el.attr("sn");
if(sn ==null||"".equals(sn)){
break ;
}
//对节目解码
p = URLDecoder.decode(p, "utf-8");
//解析出统一的节目名称,比如:天龙八部(1),天龙八部(2),同属于一个节目
int index = p.indexOf("(");
if (index != -1) {
p = p.substring(0, index);
}
//起始时间转换为秒
int startS = TimeUtil.TimeToSecond(s);
//结束时间转换为秒
int startE = TimeUtil.TimeToSecond(e);
if (startE < startS) {
startE = startE + 24 * 3600;
}
//每条记录的收看时长
int duration = startE - startS;
context.write(new Text(stbNum + "@" + date), new Text(sn + "@" + p+ "@" + s + "@" + e + "@" + duration));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
import java.util.ArrayList;
import java.util.List;
/**
*
* 时间工具
*
*/
public class TimeUtil {
/**
* 将时间00:00:00转换为秒 int
*
* @param time
* @return
*/
public static int TimeToSecond(String time) {
if (time == null||time.equals("")) {
return 0;
}
String[] my = time.split(":");
int hour = Integer.parseInt(my[0]);
int min = Integer.parseInt(my[1]);
int sec = Integer.parseInt(my[2]);
int totalSec = hour * 3600 + min * 60 + sec;
return totalSec;
}
/**
* 将时间00:00:00转换为秒 String
*
* @param time
* @return
*/
public static String TimeToSecond2(String time) {
if (time == null) {
return "";
}
String[] my = time.split(":");
int hour = Integer.parseInt(my[0]);
int min = Integer.parseInt(my[1]);
int sec = Integer.parseInt(my[2]);
int totalSec = hour * 3600 + min * 60 + sec;
return totalSec + "";
}
/**
* 求两个时间的字符串差值
* @param a_e
* @param a_s
* @return
*/
public static String getDuration(String a_e, String a_s) {
if (a_e == null || a_s == null) {
return 0 + "";
}
int ae = Integer.parseInt(a_e);
int as = Integer.parseInt(a_s);
return (ae - as) + "";
}
/**
* 将时间 00:00转换为秒 int
*
* @param time
* @return
*/
public static int Time2ToSecond(String time) {
if (time == null) {
return 0;
}
String[] my = time.split(":");
int hour = Integer.parseInt(my[0]);
int min = Integer.parseInt(my[1]);
int totalSec = hour * 3600 + min * 60;
return totalSec;
}
/**
* 提取start end 之间的分钟数
*
* @param time
* @return
*/
public static List getTimeSplit(String start, String end) {
List list = new ArrayList();
String[] s = start.split(":");
int sh = Integer.parseInt(s[0]);
int sm = Integer.parseInt(s[1]);
String[] e = end.split(":");
int eh = Integer.parseInt(e[0]);
int em = Integer.parseInt(e[1]);
if (eh < sh) {
eh = 24;
}
if (sh == eh) {
for (int m = sm; m <= em; m++) {
int am = m + 1;
int ah = sh;
if (am == 60) {
am = 0;
ah += 1;
}
String hstr = "";
String mstr = "";
if (sh < 10) {
hstr = "0" + sh;
} else {
hstr = sh + "";
}
if (m < 10) {
mstr = "0" + m;
} else {
mstr = m + "";
}
String time = hstr + ":" + mstr ;
list.add(time);
}
} else {
for (int h = sh; h <= eh; h++) {
if (h == 24) {
break;
}
if (h == sh) {
for (int m = sm; m <= 59; m++) {
int am = m + 1;
int ah = h;
if (am == 60) {
am = 0;
ah += 1;
}
String hstr = "";
String mstr = "";
if (h < 10) {
hstr = "0" + h;
} else {
hstr = h + "";
}
if (m < 10) {
mstr = "0" + m;
} else {
mstr = m + "";
}
String time = hstr + ":" + mstr ;
list.add(time);
}
} else if (h == eh) {
for (int m = 0; m <= em; m++) {
int am = m + 1;
int ah = h;
if (am == 60) {
am = 0;
ah += 1;
}
String hstr = "";
String mstr = "";
if (h < 10) {
hstr = "0" + h;
} else {
hstr = h + "";
}
if (m < 10) {
mstr = "0" + m;
} else {
mstr = m + "";
}
String time = hstr + ":" + mstr ;
list.add(time);
}
} else {
for (int m = 0; m <= 59; m++) {
int am = m + 1;
int ah = h;
if (am == 60) {
am = 0;
ah += 1;
}
String hstr = "";
String mstr = "";
if (h < 10) {
hstr = "0" + h;
} else {
hstr = h + "";
}
if (m < 10) {
mstr = "0" + m;
} else {
mstr = m + "";
}
String time = hstr + ":" + mstr ;
list.add(time);
}
}
}
}
return list;
}
} 



数据解析之后,得到
01050908200000218@2012-09-22@浙江卫视@综艺精选@23:58:04@00:03:05@301
01050908200000218@2012-09-22@浙江卫视@综艺精选@00:18:03@00:23:03@300
调用接口直接解析出我们需要数据格式
stbNum + “@” + date + “@” + sn + “@” + p+ “@” + s + “@” + e + “@”
stbNum是机顶盒号 date是日期 s是每条记录的起始时间 e是每条记录的结束时间 p是具体节目 sn是具体频道
②针对①的结果统计当前在播数,写一个类名为ExtractCurrentNum.的MR程序统计每分钟的当前在播数。
/**
*
* 针对上一步的结果统计每分钟的当前在播数
*
*/
public class ExtractCurrentNum extends Configured implements Tool {
public static class ExtractCurrentNumMapper extends
Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// stbNum0+"@"+date1+"@"+sn2+"@"+p3+"@"+s4+"@"+e5+"@"+duration6
String[] kv = StringUtils.split(value.toString(), "@");
// 过滤掉不合格数据
if (kv.length != 7) {
return;
}
// 机顶盒号
String stbnum = kv[0].trim();
// 日期
String date = kv[1].trim();
// 将时间段解析为每分钟记录,比如23:51:45~23:56:45之间的每分钟
List list = TimeUtil.getTimeSplit(kv[4], kv[5]);
int size = list.size();
// 循环统计所有指标每分钟的数据
for (int i = 0; i < size; i++) {
// 根据start end 切割的每分钟
String min = list.get(i);
// 输出每分钟当前在播人数(1)
context.write(new Text(date + "@" + min), new Text(stbnum));
}
}
}
public static class ExtractCurrentNumReduce extends
Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// 定义当前在播数集合
private Set set_curnum = new HashSet();
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
set_curnum.clear();
for (Text value : values) {
set_curnum.add(value.toString());
}
// 计算出当前在播人数
result.set(set_curnum.size()+"");
context.write(key, result);
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err
.println("Usage: ExtractProgramCurrentNum [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
job.setJarByClass(ExtractCurrentNum.class);
job.setMapperClass(ExtractCurrentNumMapper.class);
job.setReducerClass(ExtractCurrentNumReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new ExtractCurrentNum(), args);
System.exit(ec);
}
}


③针对①的结果统计每个频道每天的收视人数和人均收视时长
/**
*
* 统计每个频道每天的收视人数和人均收视时长
*
*/
public class ExtractChannelNumAndTimelen extends Configured implements Tool {
public static class ExtractChannelNumAndTimelenMapper extends
Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// stbNum0+"@"+date1+"@"+sn2+"@"+p3+"@"+s4+"@"+e5+"@"+duration6
String[] kv = StringUtils.split(value.toString(), "@");
// 过滤掉不合格数据
if (kv.length != 7) {
return;
}
// 机顶盒号
String stbnum = kv[0].trim();
// 日期
String date = kv[1].trim();
// 节目
String channel = kv[2].trim();
String duration = kv[6].trim();
// 输出每条记录用户的机顶盒号和时长
context.write(new Text(channel + "@" + date), new Text(stbnum + "@"
+ duration));
}
}
public static class ExtractChannelNumAndTimelenReduce extends
Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// 定义收视人数集合
private Set set_num = new HashSet();
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
set_num.clear();
int timelen = 0;
for (Text value : values) {
String[] arr = StringUtils.split(value.toString(), "@");
set_num.add(arr[0]);
// 满足到达条件
if (arr.length > 1) {
timelen += Integer.parseInt(arr[1]);
}
}
int num = set_num.size();
// 计算出每天的收视人数和人均收视时长
result.set(num + "@" + timelen / num);
context.write(key, result);
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err
.println("Usage: ExtractChannelNumAndTimelen [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
job.setJarByClass(ExtractChannelNumAndTimelen.class);
job.setMapperClass(ExtractChannelNumAndTimelenMapper.class);
job.setReducerClass(ExtractChannelNumAndTimelenReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new ExtractChannelNumAndTimelen(), args);
System.exit(ec);
}
}
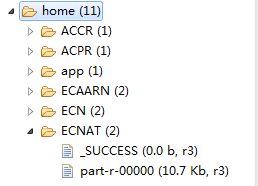

④针对①的结果统计每个频道每分钟的平均收视人数和平均到达人数
/**
*
* 针对上一步的结果统计每个频道每分钟的平均收视人数和平均到达人数
*
*/
public class ExtractChannelAvgAndReachNum extends Configured implements Tool {
public static class ExtractChannelAvgAndReachNumMapper extends
Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// stbNum0+"@"+date1+"@"+sn2+"@"+p3+"@"+s4+"@"+e5+"@"+duration6
String[] kv = StringUtils.split(value.toString(), "@");
// 过滤掉不合格数据
if (kv.length != 7) {
return;
}
// 机顶盒号
String stbnum = kv[0].trim();
// 日期
String date = kv[1].trim();
// 频道
String channel = kv[2].trim();
// 起始时间
int start = TimeUtil.TimeToSecond(kv[4].trim());
// 结束时间
int end = TimeUtil.TimeToSecond(kv[5].trim());
// 将时间段解析为每分钟记录,比如23:51:45~23:56:45之间的每分钟
List list = TimeUtil.getTimeSplit(kv[4], kv[5]);
int size = list.size();
// 循环统计所有指标每分钟的数据
for (int i = 0; i < size; i++) {
// 根据start end 切割的每分钟
String min = list.get(i);
// 输出每分钟栏目的收视人数(1)和到达人数(0,1)
if ((end - start) > 60) {
// 达到人数满足此条件
context.write(new Text(channel + "@" + date + "@" + min),
new Text(stbnum + "@" + stbnum));
}
context.write(new Text(channel + "@" + date + "@" + min),
new Text(stbnum + "@"));
}
}
}
public static class ExtractChannelAvgAndReachNumReduce extends
Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// 定义平均收视人数集合
private Set set_avgnum = new HashSet();
// 定义平均到达人数集合
private Set set_reachnum = new HashSet();
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
set_avgnum.clear();
set_reachnum.clear();
for (Text value : values) {
String[] arr = StringUtils.split(value.toString(), "@");
set_avgnum.add(arr[0]);
// 满足到达条件
if (arr.length > 1) {
set_reachnum.add(arr[1]);
}
}
// 计算出每分钟的收视人数和到达人数
result.set(set_avgnum.size() + "@" + set_reachnum.size());
context.write(key, result);
}
}
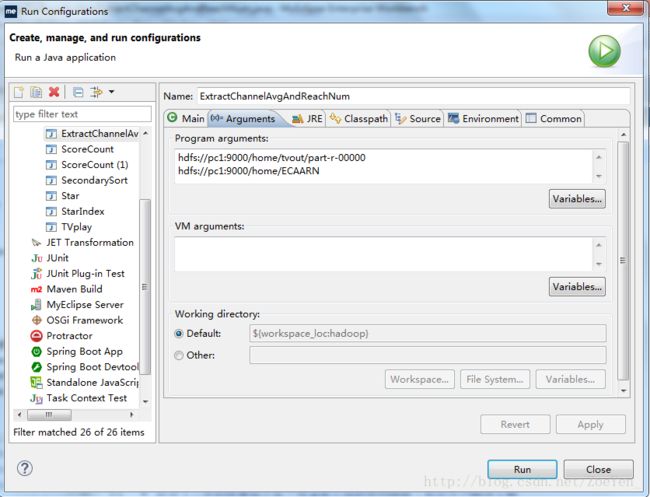
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err
.println("Usage: ExtractChannelAvgAndReachNum [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
job.setJarByClass(ExtractChannelAvgAndReachNum.class);
job.setMapperClass(ExtractChannelAvgAndReachNumMapper.class);
job.setReducerClass(ExtractChannelAvgAndReachNumReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new ExtractChannelAvgAndReachNum(), args);
System.exit(ec);
}
}

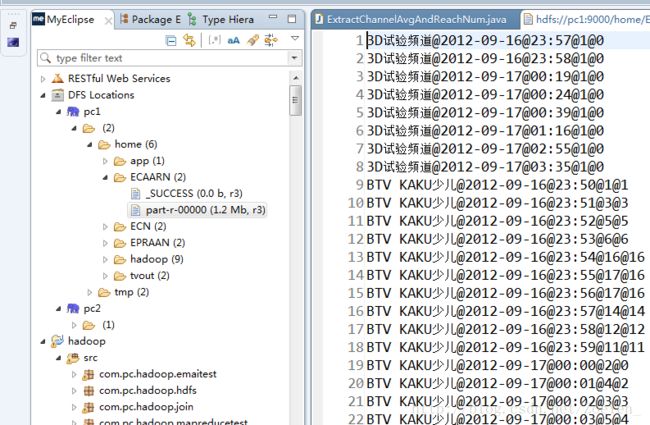
⑤针对①的结果统计每个节目每分钟的平均收视人数和平均到达人数
/**
*
* 针对上一步的结果统计每个节目每分钟的平均收视人数和平均到达人数
*
*/
public class ExtractProgramAvgAndReachNum extends Configured implements Tool {
public static class ExtractAvgAndReachNumMapper extends
Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// stbNum0+"@"+date1+"@"+sn2+"@"+p3+"@"+s4+"@"+e5+"@"+duration6
String[] kv = StringUtils.split(value.toString(), "@");
// 过滤掉不合格数据
if (kv.length != 7) {
return;
}
// 机顶盒号
String stbnum = kv[0].trim();
// 日期
String date = kv[1].trim();
// 节目
String column = kv[3].trim();
// 起始时间
int start = TimeUtil.TimeToSecond(kv[4].trim());
// 结束时间
int end = TimeUtil.TimeToSecond(kv[5].trim());
// 将时间段解析为每分钟记录,比如23:51:45~23:56:45之间的每分钟
List list = TimeUtil.getTimeSplit(kv[4], kv[5]);
int size = list.size();
// 循环统计所有指标每分钟的数据
for (int i = 0; i < size; i++) {
// 根据start end 切割的每分钟
String min = list.get(i);
// 输出每分钟栏目的收视人数(1)和到达人数(0,1)
if ((end - start) > 60) {
// 达到人数满足此条件
context.write(new Text(column + "@" + date + "@" + min),
new Text(stbnum + "@" + stbnum));
}
context.write(new Text(column + "@" + date + "@" + min),
new Text(stbnum + "@"));
}
}
}
public static class ExtractAvgAndReachNumReduce extends
Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// 定义平均收视人数集合
private Set set_avgnum = new HashSet();
// 定义平均到达人数集合
private Set set_reachnum = new HashSet();
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
set_avgnum.clear();
set_reachnum.clear();
for (Text value : values) {
String[] arr = StringUtils.split(value.toString(), "@");
set_avgnum.add(arr[0]);
// 满足到达条件
if (arr.length > 1) {
set_reachnum.add(arr[1]);
}
}
// 计算出每分钟的收视人数和到达人数
result.set(set_avgnum.size() + "@" + set_reachnum.size());
context.write(key, result);
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: ExtractProgramAvgAndReachNum [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
job.setJarByClass(ExtractProgramAvgAndReachNum.class);
job.setMapperClass(ExtractAvgAndReachNumMapper.class);
job.setReducerClass(ExtractAvgAndReachNumReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new ExtractProgramAvgAndReachNum(), args);
System.exit(ec);
}
}
StringUtils接口实现字符串转换成数组的功能
public class StringUtils {
/*
* 将字符串转换为数组
*/
public static String[] split(String value,String regex){
if(value==null)
value = "";
String[] valueItems = value.split(regex);
return valueItems;
}
}
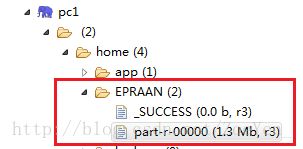

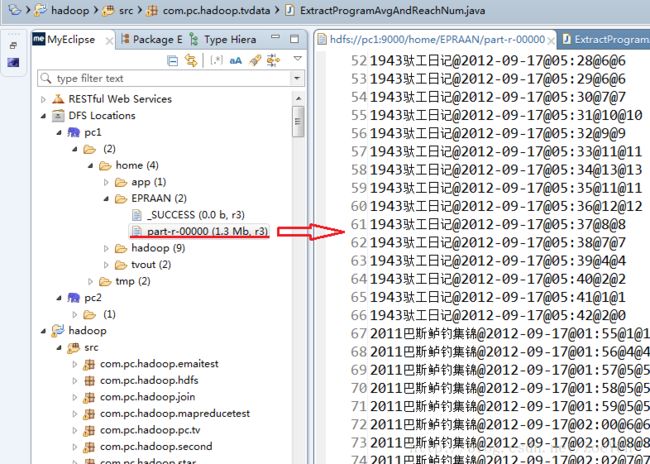
⑥针对①的结果统计每个节目每天的收视人数和人均收视时长。
/**
*
* 针对上一步的结果统计每个节目每天的收视人数和人均收视时长
*
*/
public class ExtractProgramNumAndTimelen extends Configured implements Tool {
public static class ExtractProgramNumAndTimelenMapper extends
Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// stbNum0+"@"+date1+"@"+sn2+"@"+p3+"@"+s4+"@"+e5+"@"+duration6
String[] kv = StringUtils.split(value.toString(), "@");
// 过滤掉不合格数据
if (kv.length != 7) {
return;
}
// 机顶盒号
String stbnum = kv[0].trim();
// 日期
String date = kv[1].trim();
// 节目
String column = kv[3].trim();
String duration = kv[6].trim();
//输出每条记录用户的机顶盒号和时长
context.write(new Text(column + "@" + date),
new Text(stbnum + "@" + duration));
}
}
public static class ExtractProgramNumAndTimelenReduce extends
Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// 定义收视人数集合
private Set set_num = new HashSet();
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
set_num.clear();
int timelen = 0;
for (Text value : values) {
String[] arr = StringUtils.split(value.toString(), "@");
set_num.add(arr[0]);
// 满足到达条件
if (arr.length > 1) {
timelen +=Integer.parseInt(arr[1]);
}
}
int num = set_num.size();
// 计算出每天的收视人数和人均收视时长
result.set(num + "@" + timelen/num);
context.write(key, result);
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: ExtractProgramNumAndTimelen [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
job.setJarByClass(ExtractProgramNumAndTimelen.class);
job.setMapperClass(ExtractProgramNumAndTimelenMapper.class);
job.setReducerClass(ExtractProgramNumAndTimelenReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new ExtractProgramNumAndTimelen(), args);
System.exit(ec);
}
}

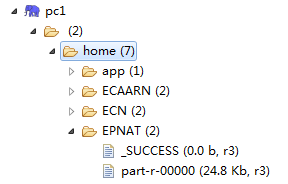
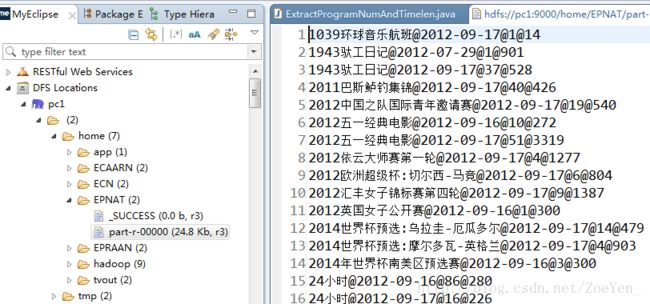
⑦根据每分钟的当前在播数和每个频道每分钟的平均收视人数和平均到达人数统计频道每天每分钟的收视指标AnalyzeCountChannelRating。
public class AnalyzeCountChannelRating extends Configured implements Tool {
public static class AnalyzeCountChannelRatingMapper extends
Mapper<Object, Text, Text, Text> {
// 存储当前在播数集合
private Map curNumMap = new HashMap();
/**
* 获取分布式缓存文件
*/
@SuppressWarnings("deprecation")
protected void setup(Context context) throws IOException,
InterruptedException {
BufferedReader br;
String infoAddr = null;
// 返回缓存文件路径
Path[] cacheFilesPaths = context.getLocalCacheFiles();
for (Path path : cacheFilesPaths) {
String pathStr = path.toString();
br = new BufferedReader(new FileReader(pathStr));
while (null != (infoAddr = br.readLine())) {
// 按行读取并解析当前在播数据
String[] tvjoin = StringUtils.split(infoAddr.toString(),
"@");
if (tvjoin.length == 3) {
curNumMap.put(
tvjoin[0].trim() + "@" + tvjoin[1].trim(),
tvjoin[2].trim());
}
}
}
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// channel0 + "@" + date1 + "@" + min2+avgnum3 +reachnum4
String[] kv = StringUtils.split(value.toString(), "@");
if (kv.length != 5) {
return;
}
// 平均收视人数
int avgnum = Integer.parseInt(kv[3].trim());
// 到达人数
int reachnum = Integer.parseInt(kv[4].trim());
// 当前在播数
int currentStbnum = Integer.parseInt(curNumMap.get(kv[1].trim()
+ "@" + kv[2].trim()));
// 收视率
float tvrating = (float) avgnum / 25000 * 100;
// 市场份额
float marketshare = (float) avgnum / currentStbnum * 100;
// 到达率
float reachrating = (float) reachnum / 25000 * 100;
// 将计算的所有指标输出
context.write(value, new Text(tvrating + "@" + reachrating + "@"
+ marketshare));
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err
.println("Usage: AnalyzeCountChannelRating cache in [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
// 添加缓存文件
FileSystem fs = FileSystem.get(conf);
FileStatus[] dirstatus = fs.listStatus(new Path(otherArgs[0]));
for (FileStatus file : dirstatus) {
job.addCacheFile(file.getPath().toUri());
}
job.setJarByClass(AnalyzeCountChannelRating.class);
job.setMapperClass(AnalyzeCountChannelRatingMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 1; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new AnalyzeCountChannelRating(), args);
System.exit(ec);
}
}

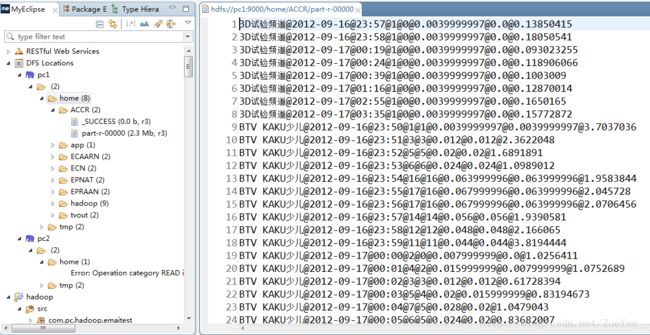
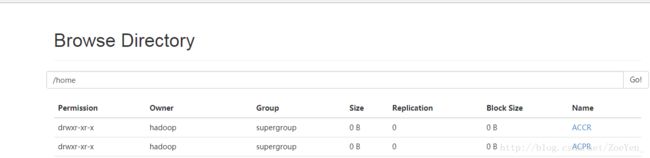
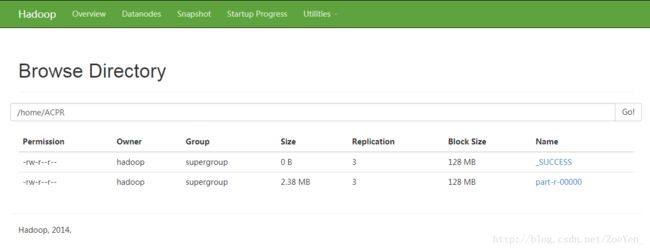
![]()
输入路径是
hdfs://pc2:9000/home/ECN/part-r-00000
hdfs://pc2:9000/home/ECAARN/part-r-00000
输出路径是
hdfs://pc2:9000/home/ACCR
[hadoop@pc1 hadoop]$ bin/hadoop jar ACCR.jar com.pc.hadoop.tvdata.AnalyzeCountChannelRating hdfs://pc2:9000/home/ECN/part-r-00000 hdfs://pc2:9000/home/ECAARN/part-r-00000 hdfs://pc2:9000/home/ACCR/回车运行,报错

Exception in thread "main" java.lang.IllegalArgumentException: Wrong FS: hdfs://cluster1:9000/home/hadoop/ECAARN/part-r-00000, expected: hdfs://cluster1
代码不能识别此hdfs文件系统,期望:hdfs://cluster1
最后在http://blog.csdn.net/a2011480169/article/details/51804139找到解决办法。
在配置文件conf中指定所用的文件系统—HDFS

重新运行
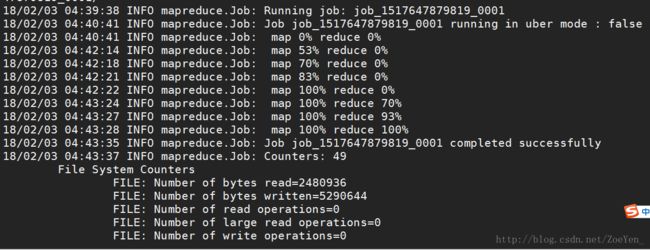
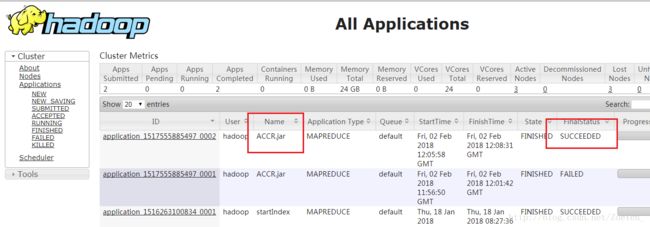
⑦根据每分钟的当前在播数和每个节目每分钟的平均收视人数和平均到达人数统计节目每天每分钟的收视指标AnalyzeCountProgramRating。
/**
*
* 统计频道每天每分钟的收视指标
*
*/
public class AnalyzeCountChannelRating extends Configured implements Tool {
public static class AnalyzeCountChannelRatingMapper extends
Mapper {
// 存储当前在播数集合
private Map curNumMap = new HashMap();
/**
* 获取分布式缓存文件
*/
@SuppressWarnings("deprecation")
protected void setup(Context context) throws IOException,
InterruptedException {
BufferedReader br;
String infoAddr = null;
// 返回缓存文件路径
Path[] cacheFilesPaths = context.getLocalCacheFiles();
for (Path path : cacheFilesPaths) {
String pathStr = path.toString();
br = new BufferedReader(new FileReader(pathStr));
while (null != (infoAddr = br.readLine())) {
// 按行读取并解析当前在播数据
String[] tvjoin = StringUtils.split(infoAddr.toString(),
"@");
if (tvjoin.length == 3) {
curNumMap.put(
tvjoin[0].trim() + "@" + tvjoin[1].trim(),
tvjoin[2].trim());
}
}
}
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// channel0 + "@" + date1 + "@" + min2+avgnum3 +reachnum4
String[] kv = StringUtils.split(value.toString(), "@");
if (kv.length != 5) {
return;
}
// 平均收视人数
int avgnum = Integer.parseInt(kv[3].trim());
// 到达人数
int reachnum = Integer.parseInt(kv[4].trim());
// 当前在播数
int currentStbnum = Integer.parseInt(curNumMap.get(kv[1].trim()
+ "@" + kv[2].trim()));
// 收视率
float tvrating = (float) avgnum / 25000 * 100;
// 市场份额
float marketshare = (float) avgnum / currentStbnum * 100;
// 到达率
float reachrating = (float) reachnum / 25000 * 100;
// 将计算的所有指标输出
context.write(value, new Text(tvrating + "@" + reachrating + "@"
+ marketshare));
}
}
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://pc2:9000");
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err
.println("Usage: AnalyzeCountChannelRating cache in [...] " );
System.exit(2);
}
Job job = Job.getInstance();
// 设置输出key value分隔符
job.getConfiguration().set(
"mapreduce.output.textoutputformat.separator", "@");
// 添加缓存文件
FileSystem fs = FileSystem.get(conf);
FileStatus[] dirstatus = fs.listStatus(new Path(otherArgs[0]));
for (FileStatus file : dirstatus) {
job.addCacheFile(file.getPath().toUri());
}
job.setJarByClass(AnalyzeCountChannelRating.class);
job.setMapperClass(AnalyzeCountChannelRatingMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ec = ToolRunner.run(new Configuration(),
new AnalyzeCountChannelRating(), args);
System.exit(ec);
}
}
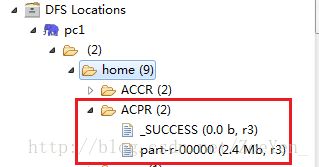
输入路径是
hdfs://pc2:9000/home/ECN/part-r-00000
hdfs://pc2:9000/home/EPRAAN/part-r-00000
输出路径是
hdfs://pc2:9000/home/ACCR


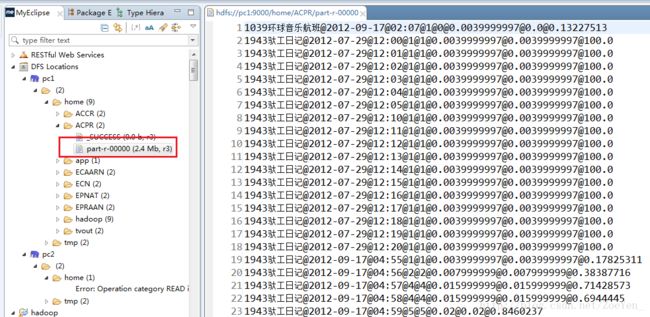
[hadoop@pc1 hadoop]$ bin/hadoop jar ACPR.jar com.pc.hadoop.tvdata.AnalyzeCountProgramRating hdfs://pc1:9000/home/ECN/part-r-00000 hdfs://pc1:9000/home/EPRAAN/part-r-00000 hdfs://pc1:9000/home/ACPR/


由于没有安装maven,所以这里采用的是手动去导出export jar包,再用到全名的类名路径。
十、利用hive工具将MR处理后的数据导入数据仓库,同时对该数据进行统计分析
①先创建hive表(一般创建hive外部表)
创建channellog_min外部表
create external table channellog_min(tvchannel string,tvtime string,tvmin string,avgnum int ,reachnum int ,tvrating double,reachrating double,marketshare double) PARTITIONED BY(tvdate string) row format delimited fields terminated by ‘@’ location ‘/homer/hive/warehouse/channellog_min/’;
创建channellog_hour外部表
create external table channellog_hour(tvchannel string,tvtime string,tvhour string,avgnum int,reachnum int ,tvrating double,reachrating double,marketshare double) PARTITIONED BY(tvdate string) row format delimited fields terminated by ‘@’ location ‘/home/hive/warehouse/channellog_hour/’;
创建channellog_day外部表
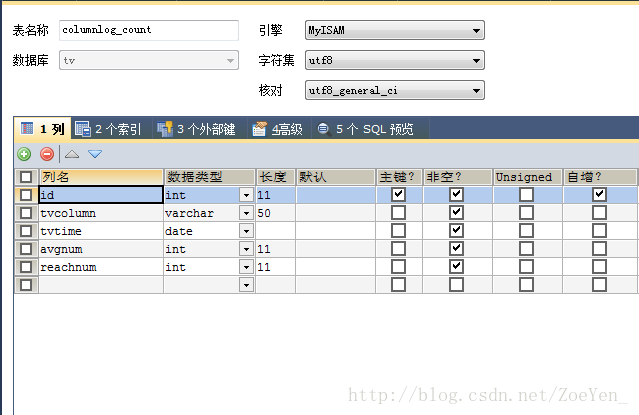
create external table channellog_day(tvchannel string,tvtime string,avgnum int,reachnum int ,tvrating double,reachrating double,marketshare double) PARTITIONED BY(tvdate string) row format delimited fields terminated by '@' location '/home/hive/warehouse/channellog_day/';创建columnlog_min外部表
create external table columnlog_min(tvcolumn string,tvtime string,tvmin string,avgnum int ,reachnum int ,tvrating double,reachrating double,marketshare double) PARTITIONED BY(tvdate string) row format delimited fields terminated by '@' location '/home/hive/warehouse/columnlog_min/';创建columnlog_hour外部表
create external table columnlog_hour(tvcolumn string,tvtime string,tvhour string,avgnum int,reachnum int ,tvrating double,reachrating double,marketshare double) PARTITIONED BY(tvdate string) row format delimited fields terminated by '@' location '/home/hive/warehouse/columnlog_hour/';创建columnlog_day外部表
create external table columnlog_day(tvcolumn string,tvtime string,avgnum int,reachnum int ,tvrating double,reachrating double,marketshare double) PARTITIONED BY(tvdate string) row format delimited fields terminated by '@' location '/home/hive/warehouse/columnlog_day/'; 创建channellog_count外部表
create external table channellog_count(tvchannel string,tvtime string,num int ,timelen int ) PARTITIONED BY(tvdate string) row format delimited fields terminated by '@' location '/home/hive/warehouse/channellog_count/';创建columnlog_count外部表
create external table columnlog_count(tvcolumn string,tvtime string,num int ,timelen int ) PARTITIONED BY(tvdate string) row format delimited fields terminated by '@' location '/home/hive/warehouse/columnlog_count/';启动mysql,再启动hive,依次创建表

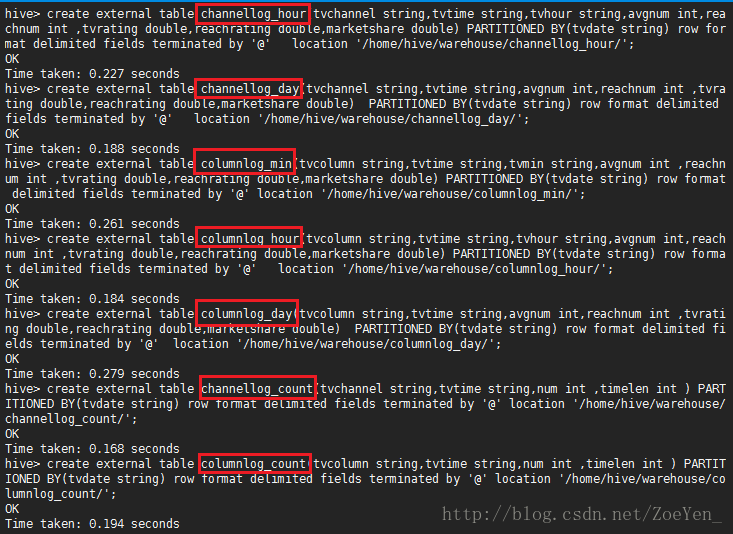
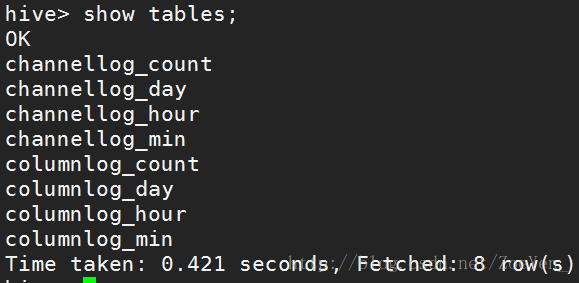


②创建好表(一共是8张表)之后,往表里加载即导入对应数据。
1、
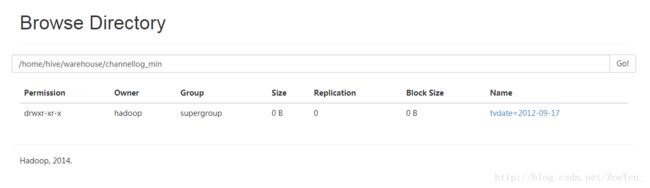
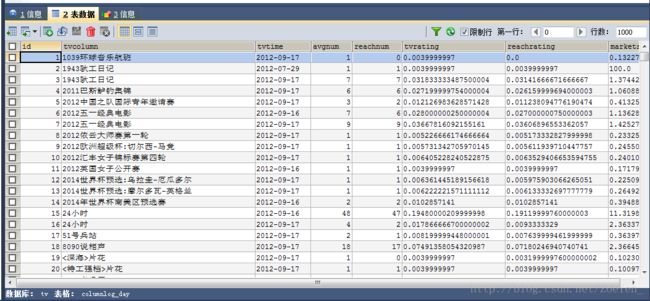
load data inpath ‘/home/ACCR/part-r-00000’ into table channellog_min
partition(tvdate=’2012-09-17’);

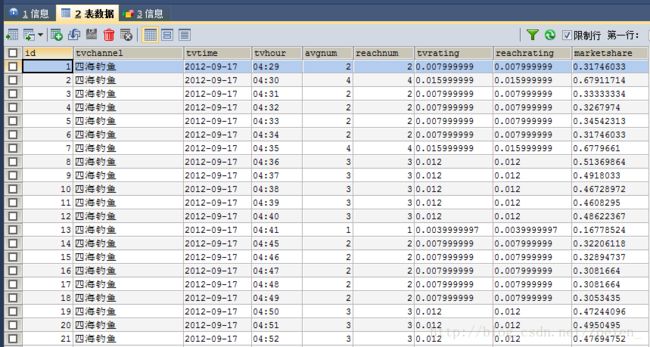
hive> select * from channellog_min;

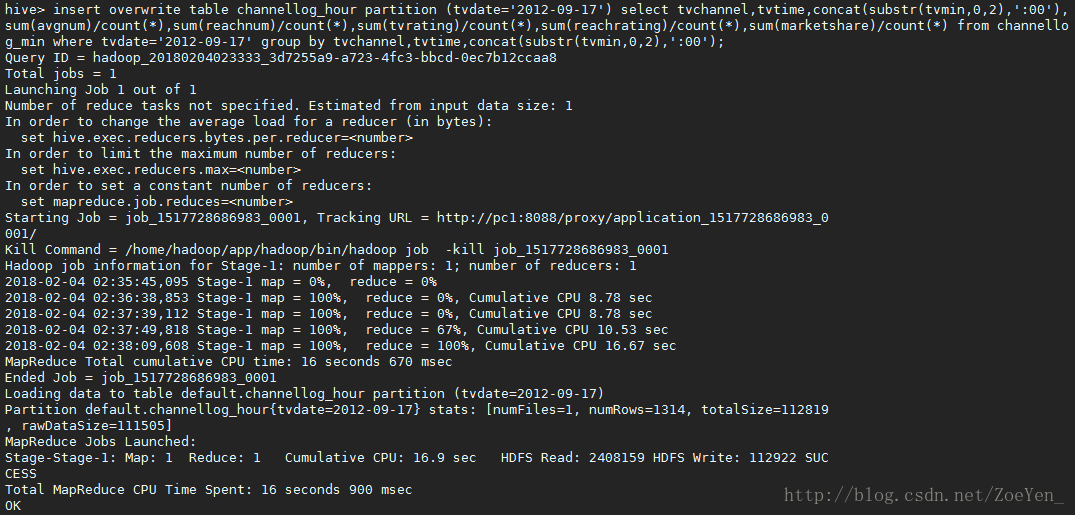
2、把分钟表导入到小时表中同时在语句中计算当前在播数,收视率,市场份额,到达率等,里面集成了mapreduce过程,就不需要另外编写mapreduce函数
insert overwrite table channellog_hour partition (tvdate=’2012-09-17’)
select
tvchannel,tvtime,concat(substr(tvmin,0,2),’:00’),sum(avgnum)/count(),sum(reachnum)/count(),sum(tvrating)/count(),sum(reachrating)/count(),sum(marketshare)/count(*)
from channellog_min where tvdate=’2012-09-17’ group by
tvchannel,tvtime,concat(substr(tvmin,0,2),’:00’);


3、从频道的分钟表中查询数据插入到频道的天表
insert overwrite table channellog_day partition (tvdate=’2012-09-17’)
select tvchannel,tvtime,
sum(avgnum)/count(),sum(reachnum)/count(),sum(tvrating)/count(),sum(reachrating)/count(),sum(marketshare)/count(*)
from channellog_min where tvdate=’2012-09-17’ group by
tvchannel,tvtime;



.
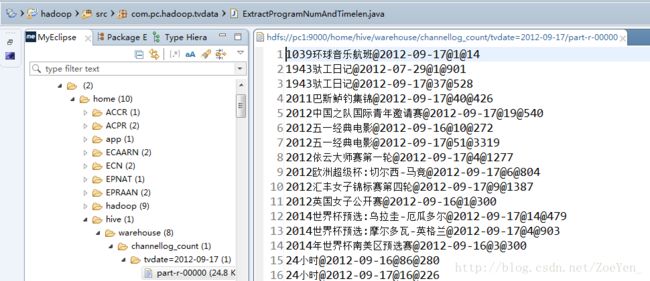
4、 加载收视时长相关数据到channel_count表中
load data inpath ‘/home/ECNAT/part-r-00000’ into table
channellog_count partition(tvdate=’2012-09-17’);


5、
load data inpath ‘/home/ACPR/part-r-00000’ into table columnlog_min
partition(tvdate=’2012-09-17’);


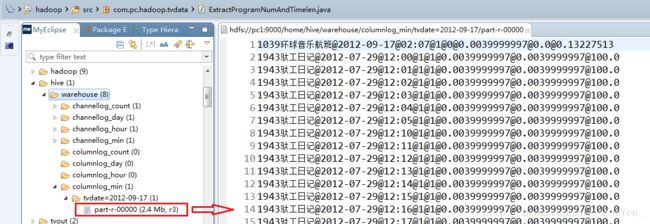
6、从节目的分钟表中查询数据插入到节目小时表
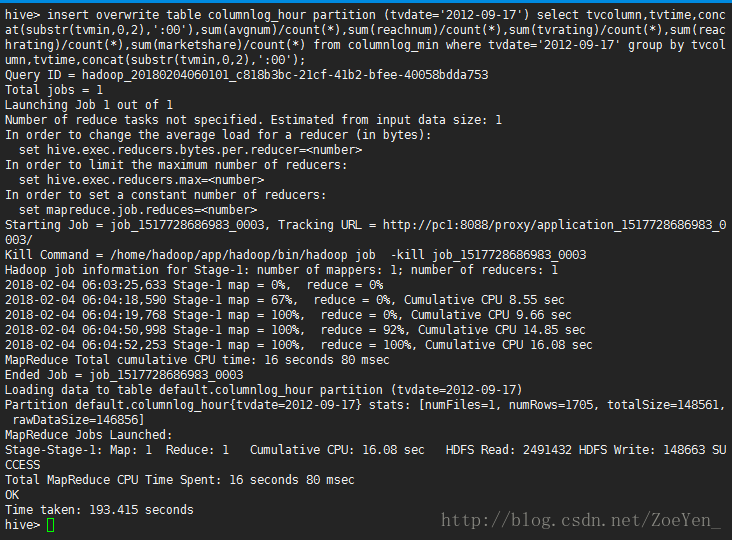
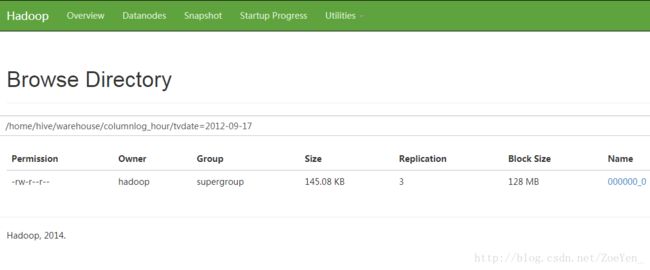
insert overwrite table columnlog_hour partition (tvdate=’2012-09-17’)
select
tvcolumn,tvtime,concat(substr(tvmin,0,2),’:00’),sum(avgnum)/count(),sum(reachnum)/count(),sum(tvrating)/count(),sum(reachrating)/count(),sum(marketshare)/count(*)
from columnlog_min where tvdate=’2012-09-17’ group by
tvcolumn,tvtime,concat(substr(tvmin,0,2),’:00’);

7、 从节目的分钟表中查询数据插入到节目的天表
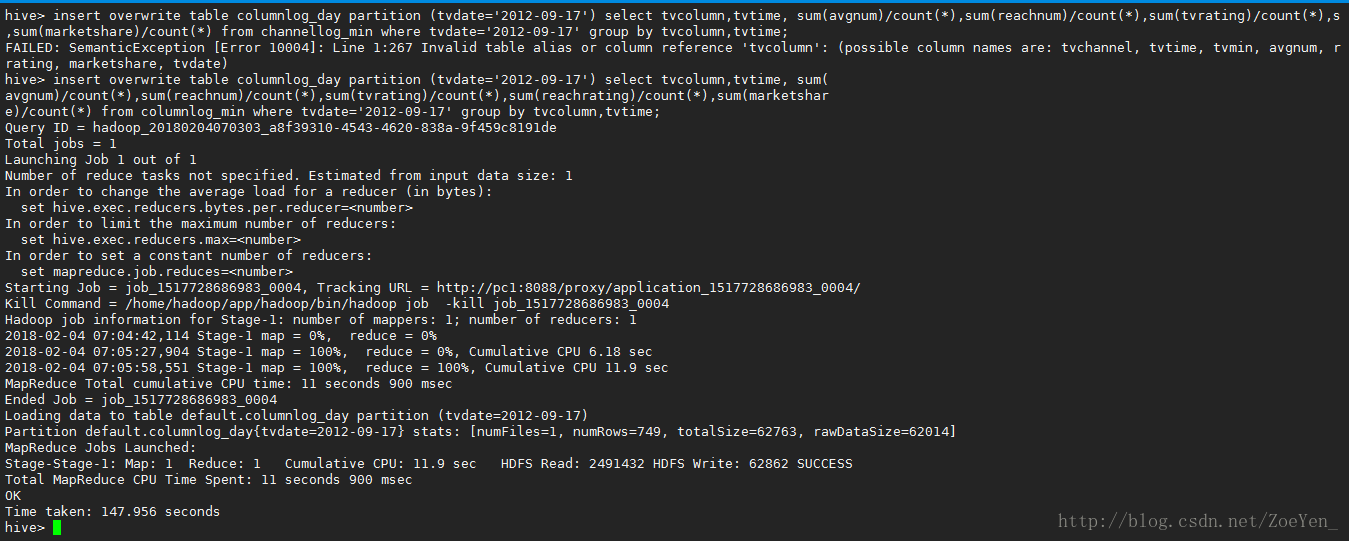
insert overwrite table columnlog_day partition (tvdate=’2012-09-17’)
select tvcolumn,tvtime,
sum(avgnum)/count(),sum(reachnum)/count(),sum(tvrating)/count(),sum(reachrating)/count(),sum(marketshare)/count(*)
from columnlog_min where tvdate=’2012-09-17’ group by
tvcolumn,tvtime;
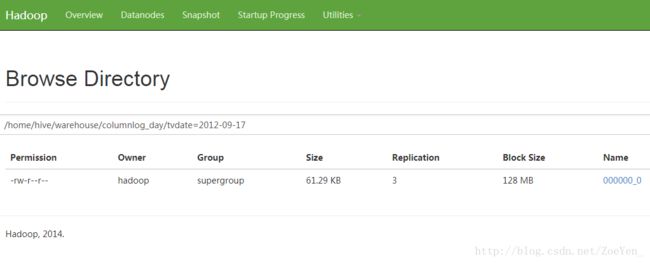

8、 加载收视时长相关数据到channel_count表中
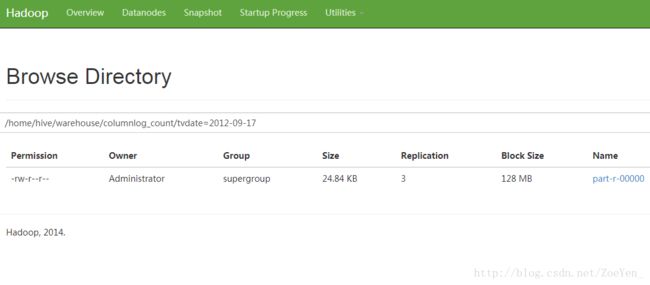
load data inpath ‘/home/EPNAT/part-r-00000’ into table columnlog_count
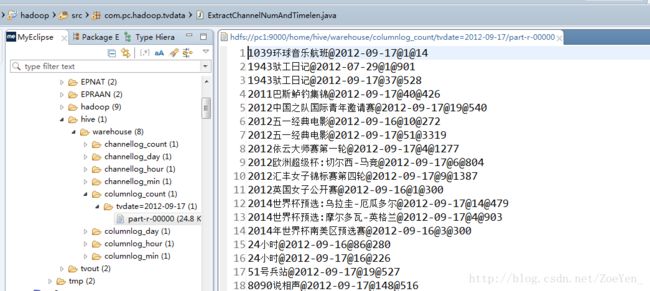
partition(tvdate=’2012-09-17’);

十一、编写应用程序或者使用sqoop 工具将hive 分析的最终数据导入mysql 数据库。

1.使用sqlyog数据库管理工具链接mysql数据库,为广电项目建立一个专门的数据库
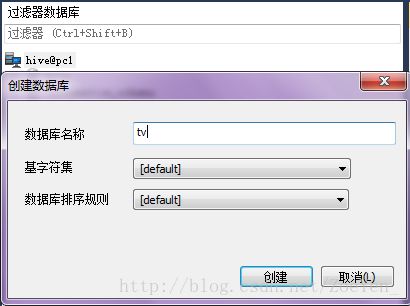
sqlyog的使用可参考 http://blog.csdn.net/zoeyen_/article/details/78722197
2.在MySQL中创建对应的表
注意:数据类型要对,否则导不进去
①channellog_min
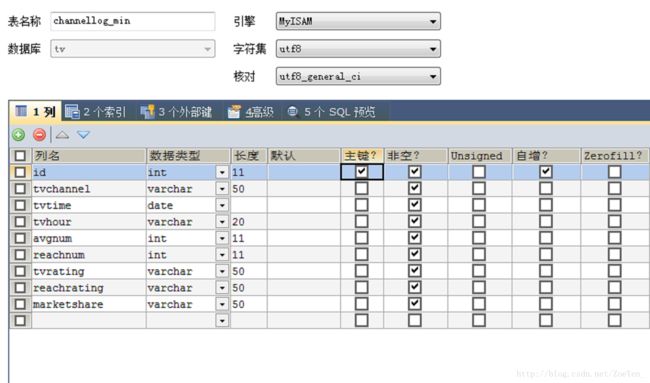
sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table channellog_min --columns tvchannel,tvtime,tvhour,avgnum,reachnum,tvrating,reachrating,marketshare --export-dir /home/hive/warehouse/channellog_min/tvdate=2012-09-17 --input-fields-terminated-by '@'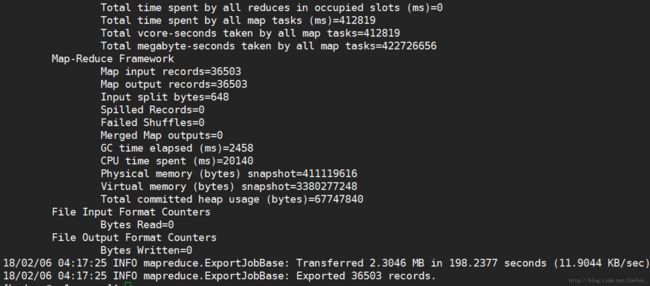
②channellog_hour
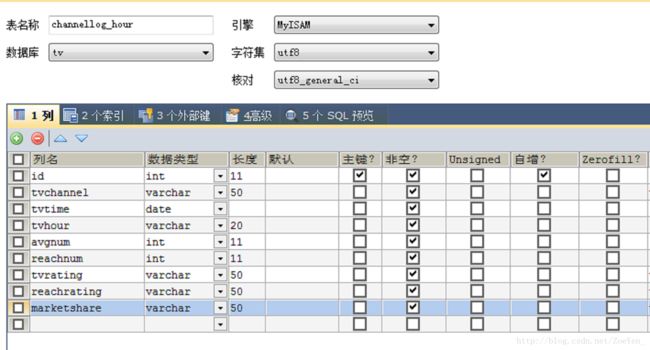
sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table channellog_hour --columns tvchannel,tvtime,tvhour,avgnum,reachnum,tvrating,reachrating,marketshare --export-dir /home/hive/warehouse/channellog_hour/tvdate=2012-09-17 --input-fields-terminated-by '@'


③channellog_day
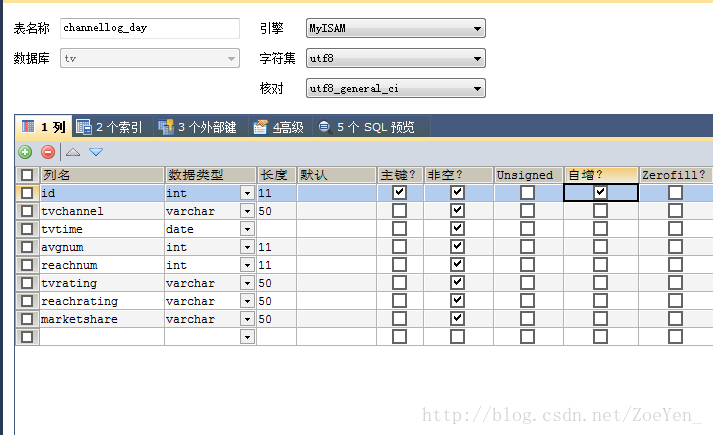
sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table channellog_day --columns tvchannel,tvtime,avgnum,reachnum,tvrating,reachrating,marketshare --export-dir /home/hive/warehouse/channellog_day/tvdate=2012-09-17 --input-fields-terminated-by '@'
④channellog_count
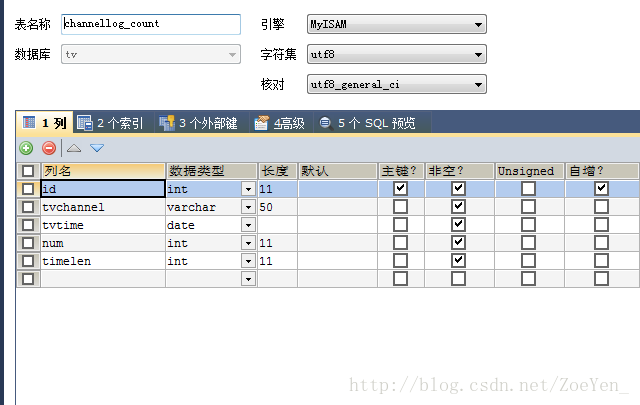
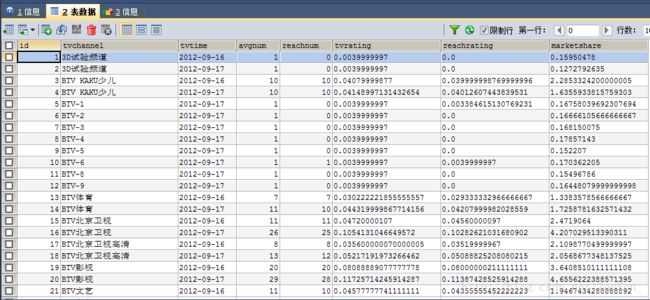
sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table channellog_count --columns tvchannel,tvtime,num,timelen --export-dir /home/hive/warehouse/channellog_count/tvdate=2012-09-17 --input-fields-terminated-by '@'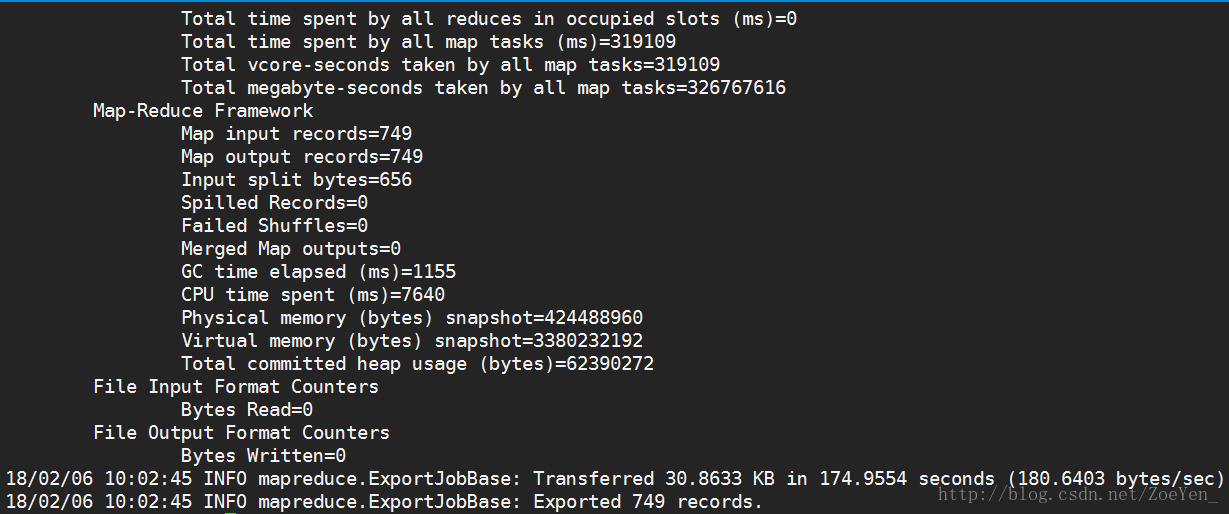

⑤columnlog_min

sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table columnlog_min --columns tvcolumn,tvtime,tvhour,avgnum,reachnum,tvrating,reachrating,marketshare --export-dir /home/hive/warehouse/columnlog_min/tvdate=2012-09-17 --input-fields-terminated-by '@'
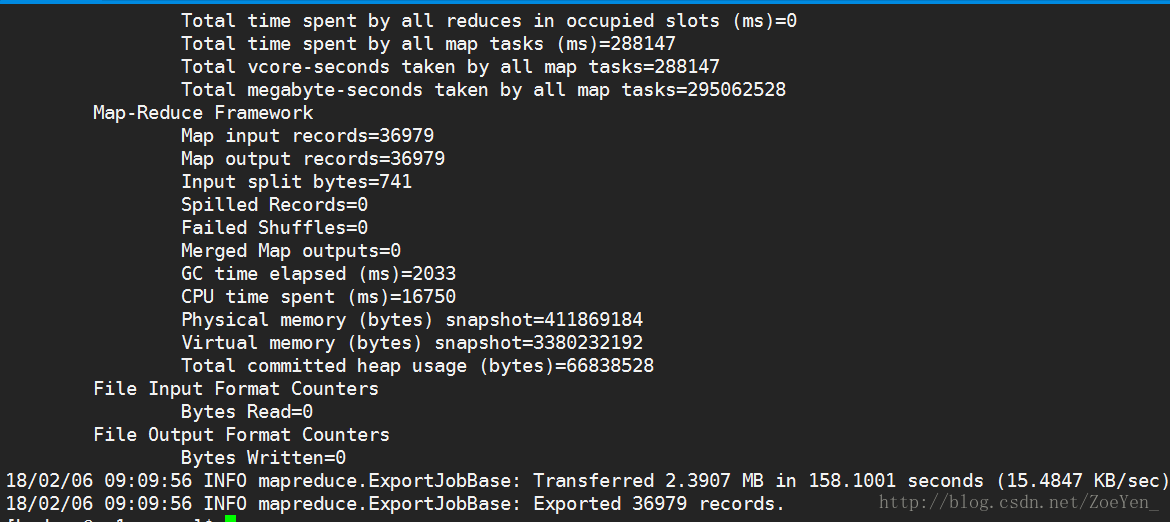
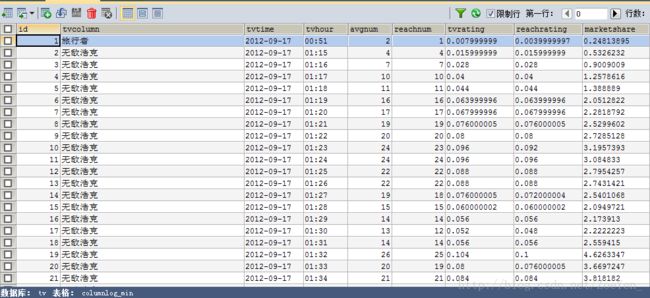
⑥columnlog_hour

sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table columnlog_hour --columns tvcolumn,tvtime,tvhour,avgnum,reachnum,tvrating,reachrating,marketshare --export-dir /home/hive/warehouse/columnlog_hour/tvdate=2012-09-17 --input-fields-terminated-by '@'

⑦columnlog_day
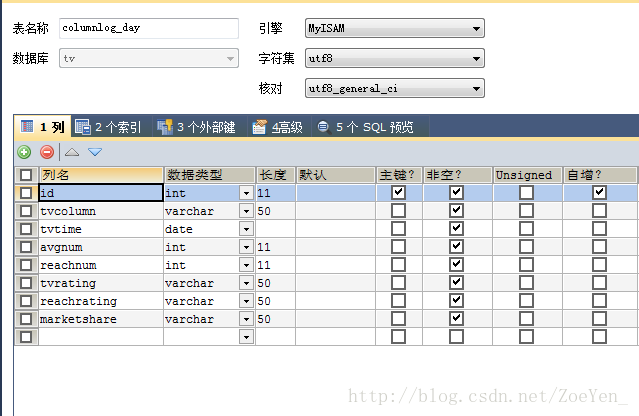
sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table columnlog_day --columns tvcolumn,tvtime,avgnum,reachnum,tvrating,reachrating,marketshare --export-dir /home/hive/warehouse/columnlog_day/tvdate=2012-09-17 --input-fields-terminated-by '@'
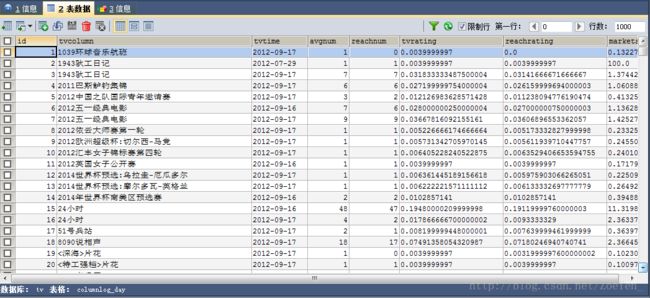
⑧columnlog_count
sqoop export --connect 'jdbc:mysql://pc1/tv?useUnicode=true&characterEncoding=utf-8' --username hive --password hive --table columnlog_count --columns tvcolumn,tvtime,num,timelen --export-dir /home/hive/warehouse/columnlog_count/tvdate=2012-09-17 --input-fields-terminated-by '@'
十二、使用Azkaban实现自动化流程
azkaban的安装配置参考
http://blog.csdn.net/zoeyen_/article/details/79301684
编写脚本文件
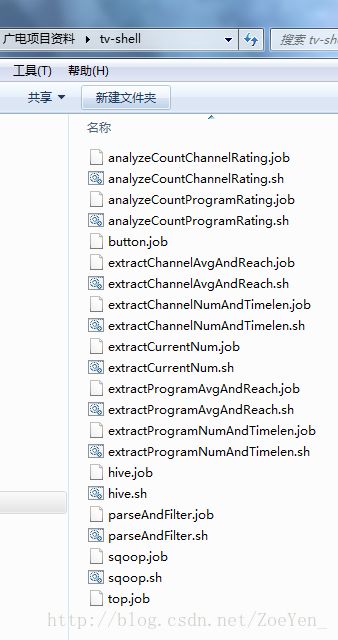
将脚本文件打包为一个zip压缩包

登录azkaban,新建一个project

将zip压缩包上传到项目下
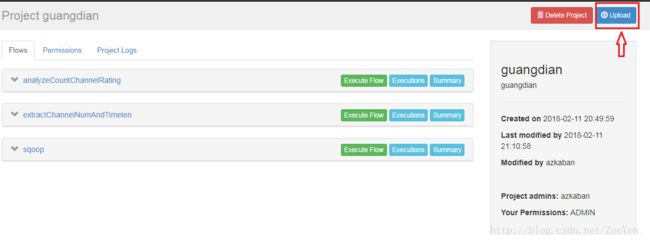
查看sqoop的工作流
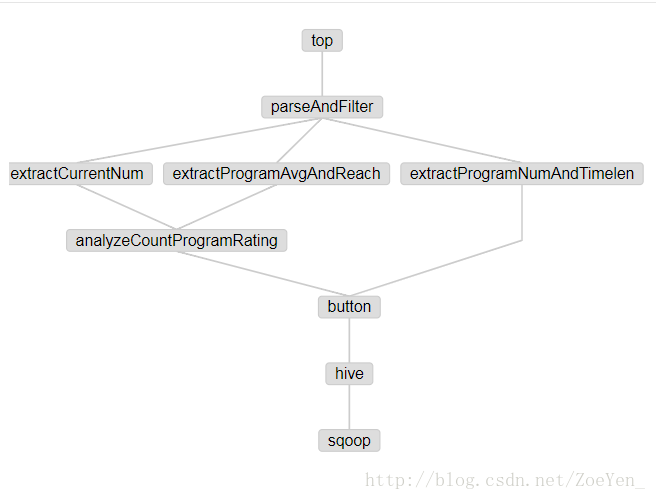

如果执行失败,查看日志

执行成功,查看详细
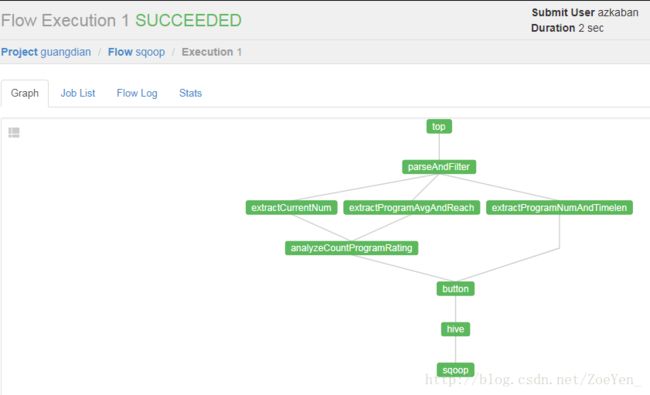
查看数据库结果

ok!