MNIST手写数字识别程序
实验环境:
python3.6.3 pip 9.0.1 tensorflow 1.10.0 window 10 oracle vm virtualbox ubuntu 16.0.1
1.基于tensorflow对mnist预测,需要连接外网。
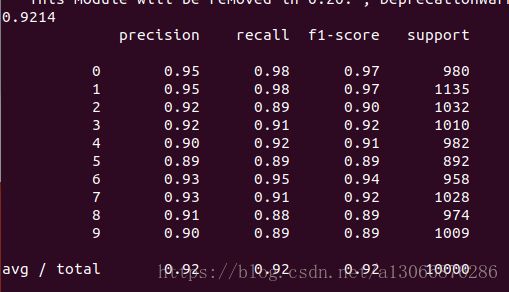
下面代码可以直接复制去调试,识别率高达98%,最低也在91%。python对代码格式有非常高的要求。行头不能同时存在tab和空格。函数内行头对齐。大概有3/40分钟左右.不过我在8月20号训练结果不是这样,最高也就97%,最低89%。不清楚其中原因
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据集
mnist = input_data.read_data_sets("/dataset",one_hot=True)
#每一批数据大小
batch_size = 100
#计算多少批数据
n_batch = mnist.train.num_examples
#定义两个placeholder,None=100,28*28=784,即100行784列
x = tf.placeholder(tf.float32,[None,784])
#0-9个输出标签
y = tf.placeholder(tf.float32,[None,10])
#创建一个简单的神经网络
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([1,10]))
#softmax函数转化为概率值
prediction = tf.nn.softmax(tf.matmul(x,W)+b)
#二次代价函数
loss = tf.reduce_mean(tf.square(y-prediction))
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#初始化变量
init = tf.global_variables_initializer()
#tf.equal()比较函数大小是否相同,相同为True,不同为false;tf.argmax():求y=1在哪个位置,求概率最#大在哪个位置
#argmax返回一维张量中最大的值所在的位置,结果存放在一个布尔型列表中
correct_prediction= tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
#cast转化类型,将布尔型转化为32位浮点型,true=1.0,false=0.0再求平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(init)
#将所有图片训练21次
for epoch in range(21):
#每次训练所有图片
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
#feed_dict传入训练集的图片和标签
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
#传入测试集的图片和标签
acc = sess.run(accuracy,feed_dict={x:batch_xs,y:batch_ys})
print("Iter"+str(epoch)+",Testing Accuracy:"+str(acc))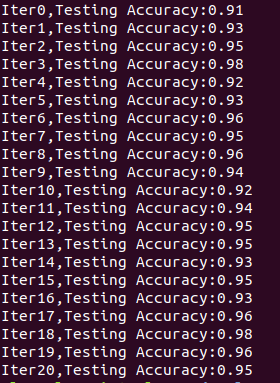
2.数据模型对mnist预测,预测结果在代码后面截图,几分钟就可看到结果
import struct
from sklearn import cross_validation,svm,metrics
#将mnist 数据集转换成csv格式
def to_csv(name,maxdata):
#打开标签数据集
lbl_f = open("./dataset/"+name+"-labels.idx1-ubyte","rb")
#打开图像数据集
img_f = open("./dataset/"+name+"-images.idx3-ubyte","rb")
#写入csv文件
csv_f = open("./dataset/"+name+",csv","w",encoding="utf-8")
#将字节流转换成python数据类型复制给标签
mag,lbl_count=struct.unpack(">II",lbl_f.read(8))
#将字节流转换成python数据类型复制给图像
mag,img_count=struct.unpack(">II",img_f.read(8))
#将字节流转换成python数据类型复制给行列
rows,cols=struct.unpack(">II",img_f.read(8))
#计算数据总量
pixels=rows*cols
res=[]
for idx in range(lbl_count):
#设置计数器,大于数据个数总量就跳出循环
if idx > maxdata:break
label=struct.unpack("B",lbl_f.read(1))[0]
bdata=img_f.read(pixels)
sdata=list(map(lambda n:str(n),bdata))
#写入标签
csv_f.write(str(labek)+",")
#写入数据
csv_f.write(",".join(sdata)+"\r\n")
if idx < 10:
s="P2 28 28 255\n"
s+=" ".join(sdata)
iname="./dataset/{0}-{1}-{2}.pgm".format(name.idx,label)
with open(iname,"w",encoding="utf-8")as f:
f.write(s)
#关闭数据流,释放资源
csv_f.close()
lbl_f.close()
img_f.close()
#转换到train.csv 1000个数据
to_csv("train",1000)
#转换到t10k.csv 1000个数据
to_csv("t10k",1000)
#通过sklearn的交叉验证处理数据,svm训练数据预测结果,metrics生成分类报告和准确率
def load_csv(fname):
labels=[]
images=[]
with open(fname,"r")as f:
for line in f:
cols=line.split(",")
if len(cols)<2:continue
labels.append(int(cols.pop(0)))
vals=list(map(lambda n:int(n)/256,cols))
images.append(vals)
return{"labels":labels,"images":images}
data=load_csv("./dataset/train.csv")
test=load_csv("./dataset/t10k.csv")
clf=svm.SVC()
#训练数据集
clf.fit(data["images"],data["labels"])
#预测数据集
predict=clf.predict(test["images"])
#生成测试精度
sore=metrics.accuracy_score(test["labels"],predict)
#生成交叉验证的报告
report=metrics.classification_report(test["labels"],predict)
print(score)
ptrint(report)该结果是训练1000次的
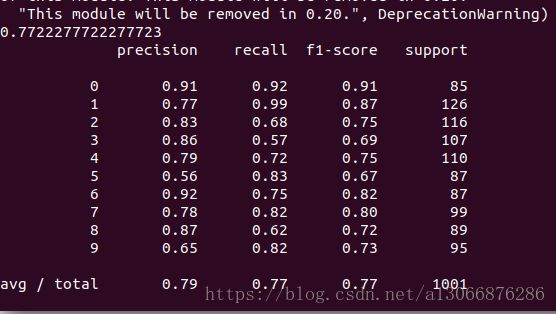
该结果是训练10000次的