A Neural Algorithm 0f Artistic Style 云笔记
A Neural Algorithm 0f Artistic Style
论文
/
代码笔记
__________________________________________
Guo__
一.style-transfer算法实现原理
在原论文中使用的模型是以
VGG网络为基础,一个在视觉物体识别基准任务上和人类视觉能力相匹配的卷积神经网络,在style-transfer中使用了VGG19的16个卷积层和5个池化层特征空间,没有全连接层(
Tricks:其中的池化层使用
平均池化替代了原本VGG19网络的最大池化,由此可改进梯度流并获得更有感染力的结果)。
网络的每一层都定义了一个非线性的过滤器(
Tricks:激活函数采用
RELU),其复杂性随着网络层位置的深入而增加。对一个输入图片x,CNN中的每一层滤波器对其进行编码,响应结果反映了输入图像从底层到高层的信息变化。为了实现不同层图片信息的可视化,我们对一个高斯白噪声图片进行梯度下降来找到另一张可以匹配原图特征响应的图片。
1.1 content内容匹配
我们定义p和x分别为原图和用于生成的白噪声图,P和F为网络L层的原图和白噪声图的特征相应输出,用平均错误作为损失函数来体现两个特征图间误差,于是这就由一个实际问题转换为求解下式
最小化的
优化问题,根据数学,对影响输出的变量
按照梯度的反方向调整,能实现对输入的
最小化:

对其求偏导的结果为:

对于这个式子,使用标准的反向传播算法(
SGD随机梯度下降法)将能求得各层中相对输入图像x的梯度,再根据权值更新规则(W=W+a*(梯度),a为学习率)对各层权值进行更新,直到随机噪声图像x在CNN网络中的相应层的输出特征
F和原图p产生的输出特征
P
相同。在原算法中采用的是VGG网络中的
conv1_1,conv2_1,con3_1,conv4_1和conv5_1(
Tricks
:卷积逐次获取图像的局部->全局特征
,低层实现了对内容、偏重于像素级的优化、高层偏重于对图像含义的全局优化)这5层作为优化层,使得相应层的特征输出相同,由此便实现了高斯白噪声图对原图的自动生成。
在CNN网络每一层的响应部分建立一个风格再现器:计算不同滤波器响应间的关系,通过输入图片在空间上的扩展获取其期望,这些特征的相关性由Gram矩阵G给出 , G由L层特征向量图i和j的内积得到:

1.2 Style艺术风格匹配
为了产生匹配给定图片风格的
纹理信息,我们通过对一张高斯白噪声图片进行梯度下降的方法来找到另一个匹配原始图片风格的纹理图片。具体的计算过程可以看作一个对于原始图像Gram矩阵和待生成图像Gram矩阵差值的
均方最小化问题。为此,我们定义a为原始风格图片,x为待生成图片,A和G分别为CNN网络中L层的各自的风格表现(即响应输出),该层对整体的损失loss(或者称为敏感度)可得:

则可得全局损失loss
(
链式求导
)为:

其中W为各层对全局损失函数的权重因子(具体的权重计算如下),各层对全局损失的敏感度E关于该层激活值的导数可以按照如下的方式计算得到:

在网络的的低层,敏感度E相对激活值的导数可以通过标准的反向传播算法计算得,在原论文中的风格重建是通过让
高斯白噪声图响应层的输出响应匹配
艺术风格图像在CNN网络中
‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’ and ‘conv5 1’的响应输出
(局部损失函数最小)实现的。
1.3 正则化
为了实现原图向艺术风格图的转化,即产生一张图片融合原始图像的内容和艺术照片的风格(
高层响应),我们对
高斯白噪声底图和
原始图片在网络某一层输出响应的差值
(损失函数为均方差值)以及
风格图片在CNN网络中各个层输出的差值(
损失函数为均方差值)进行正则化全局最小优化处理。这里,我们定义p为原始图片、a为艺术图片、x为高斯白噪声图片,那么全局最小优化问题可以转换为以下的函数优化问题:

其中,α和β是内容图和风格图在优化问题中所占的权重值(会对最终的艺术效果有所应影响),举例说明:在原论文figure2显示的图片,实际的生成过程是通过将高斯白噪声图向
conten原始图在‘
conv4_2’响应和
风格图在
conv1_1’,'conv2_1',''conv3_1','conv4_1','conv5_1'
(在这些层的权重为1/5,其他输出层权值为0)这些层的响应,运用上述公式计算,实现
全局最小优化
,
具体的优化方法为反向传播(
SNG随机梯度下降)。其中,α/β比值为0.001(B,C,D),或者0.0001,Figure3图片显示的结果则表现了不同content和style
权重造成的影响,其中对风格图的相关层响应匹配情况为
:
‘conv1 _1’ (A) , ‘conv1_1’ and ‘conv2_1’ (B), ‘conv1_1’, ‘conv2_1’ and ‘conv3_1’ (C), ‘conv1_1’ ,‘conv2_1’, ‘conv3_1’and‘conv4_1’(D),‘conv1_1’, ‘conv2_1’, ‘conv3_1’, ‘conv4_1’ and ‘conv5_1’(E) .各层的权重因子总是根据
激活层的数量进行等概率分割的,各层相等。
通过
求解正则化损失函数最小条件下的各层
权值
、
偏置,即可得用于生成对应艺术风格(如梵高的星空风格)得CNN网络模型
二、VGG19网络模型简析
2.1 算法网络及激活函数
本论文中主要使用模型为VGG19(效果较好),其采用了16个卷积层和5个池化层,卷积层用于提取图像(
高斯白噪声图、艺术风格图、原始图像)从局部到全局的特征向量图,池化层采用平均池化实现对图像的降维处理,避免模型过于关注细节,造成过拟合,有利于对全局抽象特征的获取。此外,对每个卷积层输出进行非线性处理,此处采用激活函数(
RELU
函数_纠正线性单元)。
激活函数是深度学习非线性的主要来源,通常包括:simgoid、tanh、ReLU,其中
ReLU是目前用的最多的激活函数,主要原因为其收敛更快、并且能保持同样的效果。
标准的ReLU函数为max(x,0),当x>0时输出x,当x<0时输出0;
tash函数为双切正切函数,取值为[-1.1];
sigmod函数为S形函数,取值范围为[0,1];引入激活函数的主要目的是解决线性模型无法解决线性不可分数据的分类问题。在每一层叠加完了以后,
加一个激活函数, 这样输出的就是一个不折不扣的非线性函数,神经网络的表达能力更加强大,
既可以生成线性分类器又能实现非线性分类模型的构建。
在本算法中,具体的VGG19网络如下,对
.deploy网络描述文件进行分析后,通过Microsoft Ofiice Visio工具描绘得
:
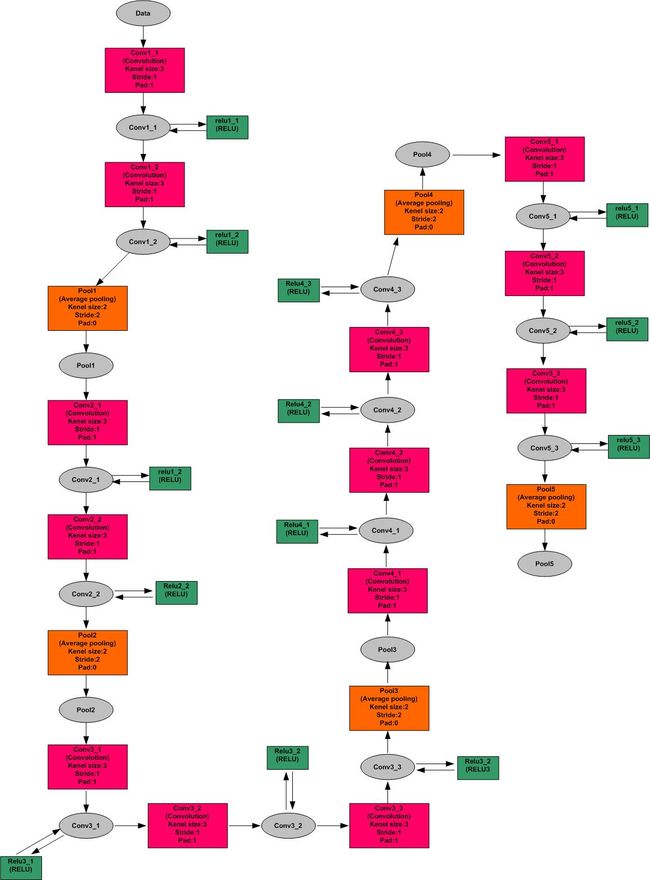
2.2 CNN中的卷积原理
该算法使用卷积神经网络(CNN),算法中大量涉及卷积运算,因而在此做一原理分析,帮助记忆与CNN理解,首先,卷积的
运算对象
为特征检测子(
卷积核
)与图像数据(包括
原始图像
和
特征向量图
)。在Caffe中,卷积是将
卷积核与输入图像
变成两个大矩阵A和B,然后A和B按照
矩阵乘法
的形式相乘得到卷积运算结果C(这种方式能充分发挥GPU乘法运算的高效性)。具体的A和B生成及计算过程如下(Microsoft Office Visio):
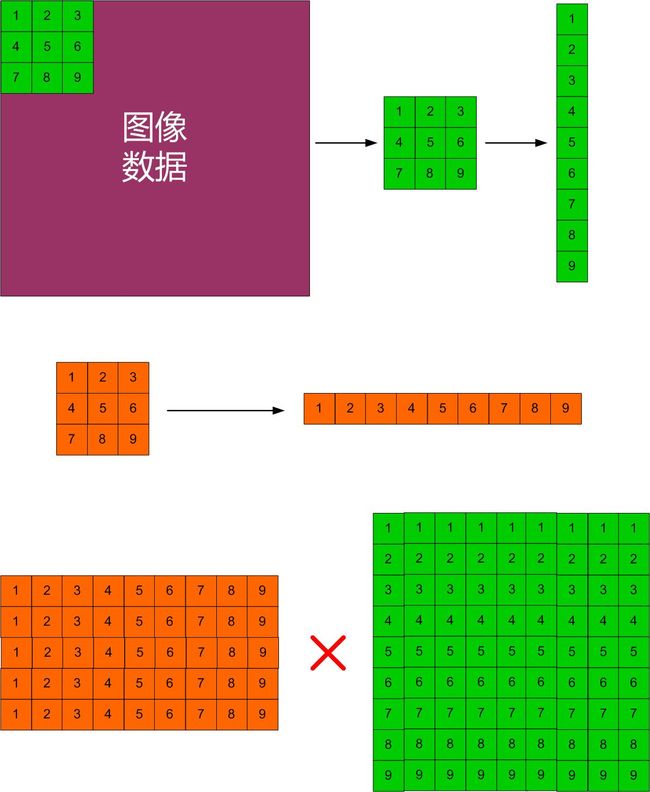
由示意图可知:
矩阵A的行数
代表
卷积核数量
,每一行的具体值代表卷积核数据,
矩阵B的列数
代表原图的
像素块数量
,每一列具体值代表像素块像素值,根据
矩阵论乘法
运算过程,A的每一行和B的每一列做对位相乘,得到新的
特征向量图
,即卷积结果。
三、算法实现
整套算法的实现基于
CRSN
本科生实验室
服务器设备,128
G
运行内存,3.2
GCPU
频率、英伟达1080p显卡、酷睿
I7
、8核处理器、暂时运行于虚拟机模式下,未能发挥设备整体运算性能,单张风格转换时间为3h
,
后期将补充
GPU
加速模式下的数据,具体转换如下,整体效果较为满意:

四、
P
y
thon
代码理解(
人生苦短,我用
Python
!
)
算法的验证性demo采用python作为编程语言编写,其中神经网络计算通过Caffe负责完成,损失最小化,矩阵操作等则有numpy和scipy完成,这里的最优化方法采用L_BFGS
,
具体的算法笔记如下:
# system imports 系统函数库
import argparse
import logging
import os
import sys
import timeit
# library imports 依赖库导入
import caffe
import numpy as np
import progressbar as pb
from scipy.fftpack import ifftn
from scipy.linalg.blas import sgemm
from scipy.misc import imsave
from scipy.optimize import minimize
from skimage import img_as_ubyte
from skimage.transform import rescale
# logging 打印信息格式定义
LOG_FORMAT = "%(filename)s:%(funcName)s:%(asctime)s.%(msecs)03d -- %(message)s"
# numeric constants
INF = np.float32(np.inf)
STYLE_SCALE = 1.2
# weights for the individual models 选用不同网络模型(VGG19/VGG16/GOOGLENET/CAFFENET)时content和style优化层的选取及各层的权重
# assume that corresponding layers' top blob matches its name
VGG19_WEIGHTS = {"content": {"conv4_2": 1},
"style": {"conv1_1": 0.2,
"conv2_1": 0.2,
"conv3_1": 0.2,
"conv4_1": 0.2,
"conv5_1": 0.2}}
VGG16_WEIGHTS = {"content": {"conv4_2": 1},
"style": {"conv1_1": 0.2,
"conv2_1": 0.2,
"conv3_1": 0.2,
"conv4_1": 0.2,
"conv5_1": 0.2}}
GOOGLENET_WEIGHTS = {"content": {"conv2/3x3": 2e-4,
"inception_3a/output": 1-2e-4},
"style": {"conv1/7x7_s2": 0.2,
"conv2/3x3": 0.2,
"inception_3a/output": 0.2,
"inception_4a/output": 0.2,
"inception_5a/output": 0.2}}
CAFFENET_WEIGHTS = {"content": {"conv4": 1},
"style": {"conv1": 0.2,
"conv2": 0.2,
"conv3": 0.2,
"conv4": 0.2,
"conv5": 0.2}}
# argparse 参数解析
parser = argparse.ArgumentParser(description="Transfer the style of one image to another.",
usage="style.py -s -c ") #格式
parser.add_argument("-s", "--style-img", type=str, required=True, help="input style (art) image")
parser.add_argument("-c", "--content-img", type=str, required=True, help="input content image")
parser.add_argument("-g", "--gpu-id", default=0, type=int, required=False, help="GPU device number")
parser.add_argument("-m", "--model", default="vgg16", type=str, required=False, help="model to use")
parser.add_argument("-i", "--init", default="content", type=str, required=False, help="initialization strategy")
parser.add_argument("-r", "--ratio", default="1e4", type=str, required=False, help="style-to-content ratio")
parser.add_argument("-n", "--num-iters", default=512, type=int, required=False, help="L-BFGS iterations")
parser.add_argument("-l", "--length", default=512, type=float, required=False, help="maximum image length")
parser.add_argument("-v", "--verbose", action="store_true", required=False, help="print minimization outputs")
parser.add_argument("-o", "--output", default=None, required=False, help="output path")
def _compute_style_grad(F, G, G_style, layer):
"""
Computes style gradient and loss from activation features. 对艺术风格图在激活层的输出特征进行梯度和敏感度计算
"""
# compute loss and gradient
(Fl, Gl) = (F[layer], G[layer]) #得到对应的层的输出Fl表示艺术图像、Gl表示高斯白噪声图像
c = Fl.shape[0]**-2 * Fl.shape[1]**-2 #Blob shape[0]表示输入图像的宽度,shape[1]表示高度,c为图像像素总数
El = Gl - G_style[layer] #噪声图像和艺术风格图像在L层的响应差值,G_style为艺术风格图在对应层的响应
loss = c/4 * (El**2).sum() #使用均方差损失函数
grad = c * sgemm(1.0, El, Fl) * (Fl>0) #sgemm矩阵乘法函数,对所有激活层进行链式求导得该层梯度
return loss, grad
def _compute_content_grad(F, F_content, layer):
"""
Computes content gradient and loss from activation features. 对content图在激活层的输出特征进行梯度和敏感度计算
"""
# compute loss and gradient
Fl = F[layer] #获得高斯白噪声在激活层的响应输出
El = Fl - F_content[layer] #由理论部分推导的敏感度计算公式
loss = (El**2).sum() / 2 #采用均方差计算公式
grad = El * (Fl>0) #对所有激活层进行链式求导得该层梯度
return loss, grad
def _compute_reprs(net_in, net, layers_style, layers_content, gram_scale=1):
"""
Computes representation matrices for an image. 计算图像在网络中的输出矩阵表示
"""
# input data and forward pass #输入图像并进行前向传播
(repr_s, repr_c) = ({}, {}) #构建存储矩阵
net.blobs["data"].data[0] = net_in #将输入图像放入网络data层的输入端
net.forward() #根据输入进行前向传播
# loop through combined set of layers
for layer in set(layers_style)|set(layers_content): #对应style和content图的优化层时
F = net.blobs[layer].data[0].copy() #拷贝该层的输出数据
F.shape = (F.shape[0], -1)
repr_c[layer] = F #将拷贝的conten层数据存储
if layer in layers_style: #当循环至style层相应激活层时
repr_s[layer] = sgemm(gram_scale, F, F.T) #计算
return repr_s, repr_c
def style_optfn(x, net, weights, layers, reprs, ratio):
"""
Style transfer optimization callback for scipy.optimize.minimize(). #对风格转换过程进行损失最小化优化
:param numpy.ndarray x: 经过扁平化处理的阵列数据(高斯白噪声图像数据)
Flattened data array.
:param caffe.Net net:
Network to use to generate gradients. 用于计算梯度的网络
:param dict weights: 网络中的权值
Weights to use in the network.
:param list layers:
Layers to use in the network. 网络中计算梯度将用到的层信息
:param tuple reprs:
Representation matrices packed in a tuple.
:param float ratio:
Style-to-content ratio. style/content的的权重比例参数,影响输出结果的艺术程度
"""
# update params #根据weight参数提供的数据对style/content相应优化层的参数进行更新
layers_style = weights["style"].keys()
layers_content = weights["content"].keys()
net_in = x.reshape(net.blobs["data"].data.shape[1:]) #将数据输入到网络
# compute representations
(G_style, F_content) = reprs #得到不同网络模型时的优化层信息
(G, F) = _compute_reprs(net_in, net, layers_style, layers_content) #前向传播并得到相应优化层的响应数据
# backprop by layer #逐层反向传播计算
loss = 0 #初始化损失值为0
net.blobs[layers[-1]].diff[:] = 0 #将权值更新值清零
for i, layer in enumerate(reversed(layers)): #对所有已知层
next_layer = None if i == len(layers)-1 else layers[-i-2]
grad = net.blobs[layer].diff[0] #得该层原始梯度值更新值
# style contribution
if layer in layers_style: #当处于style层时
wl = weights["style"][layer] #根据不同的模型及优化层数量选择得各优化层权值
(l, g) = _compute_style_grad(F, G, G_style, layer) #根据style各层损失函数及梯度计算函数得响应值
loss += wl * l * ratio #全局损失为各层敏感值的加权和
grad += wl * g.reshape(grad.shape) * ratio
# content contribution
if layer in layers_content: #当为content内容层时
wl = weights["content"][layer]
(l, g) = _compute_content_grad(F, F_content, layer) #得各层得loss和梯度
loss += wl * l #得全局损失
grad += wl * g.reshape(grad.shape)
# compute gradient
net.backward(start=layer, end=next_layer) #调用反向传播函数,随机梯度下降(SGD)法计算梯度更新权值
if next_layer is None: #next_layer用于判断是否需要进行权值更新
grad = net.blobs["data"].diff[0]
else:
grad = net.blobs[next_layer].diff[0]
# format gradient for minimize() function #格式化梯度更新值为float64格式,方便用于优化
grad = grad.flatten().astype(np.float64)
return loss, grad #返回当前损失函数值及梯度更新值
class StyleTransfer(object): #风格转换类
"""
Style transfer class.
"""
def __init__(self, model_name, use_pbar=True): #对self网络进行初始化
"""
Initialize the model used for style transfer. #确定用于风格转换得网络模型
:param str model_name:
Model to use.
:param bool use_pbar:
Use progressbar flag. #progressbar启用标志位(用于显示进度)
"""
style_path = os.path.abspath(os.path.split(__file__)[0])
base_path = os.path.join(style_path, "models", model_name) #根据路径及模型名加载相应模型
# vgg19
if model_name == "vgg19":
model_file = os.path.join(base_path, "VGG_ILSVRC_19_layers_deploy.prototxt")
pretrained_file = os.path.join(base_path, "VGG_ILSVRC_19_layers.caffemodel")
mean_file = os.path.join(base_path, "ilsvrc_2012_mean.npy")
weights = VGG19_WEIGHTS
# vgg16
elif model_name == "vgg16":
model_file = os.path.join(base_path, "VGG_ILSVRC_16_layers_deploy.prototxt")
pretrained_file = os.path.join(base_path, "VGG_ILSVRC_16_layers.caffemodel")
mean_file = os.path.join(base_path, "ilsvrc_2012_mean.npy")
weights = VGG16_WEIGHTS
# googlenet
elif model_name == "googlenet":
model_file = os.path.join(base_path, "deploy.prototxt")
pretrained_file = os.path.join(base_path, "bvlc_googlenet.caffemodel")
mean_file = os.path.join(base_path, "ilsvrc_2012_mean.npy")
weights = GOOGLENET_WEIGHTS
# caffenet
elif model_name == "caffenet":
model_file = os.path.join(base_path, "deploy.prototxt")
pretrained_file = os.path.join(base_path, "bvlc_reference_caffenet.caffemodel")
mean_file = os.path.join(base_path, "ilsvrc_2012_mean.npy")
weights = CAFFENET_WEIGHTS
else:
assert False, "model not available"
# add model and weights 加载模型和权值(不同模型时用于content和style的优化层种类与数量及权重比不一样)
self.load_model(model_file, pretrained_file, mean_file)
self.weights = weights.copy()
self.layers = []
for layer in self.net.blobs:
if layer in self.weights["style"] or layer in self.weights["content"]: #对style和content预设优化层参数
self.layers.append(layer)
self.use_pbar = use_pbar #是否启用progressbar
# set the callback function
if self.use_pbar:
def callback(xk):
self.grad_iter += 1
try:
self.pbar.update(self.grad_iter)
except:
self.pbar.finished = True
if self._callback is not None:
net_in = xk.reshape(self.net.blobs["data"].data.shape[1:])
self._callback(self.transformer.deprocess("data", net_in))
else:
def callback(xk):
if self._callback is not None:
net_in = xk.reshape(self.net.blobs["data"].data.shape[1:])
self._callback(self.transformer.deprocess("data", net_in))
self.callback = callback
def load_model(self, model_file, pretrained_file, mean_file): #模型加载函数
"""
Loads specified model from caffe install (see caffe docs).
:param str model_file:
Path to model protobuf.
:param str pretrained_file:
Path to pretrained caffe model.
:param str mean_file:
Path to mean file.
"""
# load net (supressing stderr output)
null_fds = os.open(os.devnull, os.O_RDWR) #开启系统函数打开文件(可读可写模式)
out_orig = os.dup(2)
os.dup2(null_fds, 2)
net = caffe.Net(model_file, pretrained_file, caffe.TEST) #调用caffe网络加载模型函数
os.dup2(out_orig, 2)
os.close(null_fds)
# all models used are trained on imagenet data #所有用于测试的模型都属于用于imagenet数据识别的模型
transformer = caffe.io.Transformer({"data": net.blobs["data"].data.shape})
transformer.set_mean("data", np.load(mean_file).mean(1).mean(1)) #设置均值文件数据
transformer.set_channel_swap("data", (2,1,0)) #
transformer.set_transpose("data", (2,0,1)) #对输入数据做转置处理
transformer.set_raw_scale("data", 255) #设置原始数据尺寸
# add net parameters
self.net = net #得网络
self.transformer = transformer
def get_generated(self):
"""
Saves the generated image (net input, after optimization). 存储生成的风格图片
:param str path:
Output path.
"""
data = self.net.blobs["data"].data
img_out = self.transformer.deprocess("data", data)
return img_out
def _rescale_net(self, img):
"""
Rescales the network to fit a particular image. 根据输入图片重新配置网络的输入尺寸
"""
# get new dimensions and rescale net + transformer 获取新尺寸并更新
new_dims = (1, img.shape[2]) + img.shape[:2]
self.net.blobs["data"].reshape(*new_dims)
self.transformer.inputs["data"] = new_dims
def _make_noise_input(self, init): #生成白噪声文件
"""
Creates an initial input (generated) image.
"""
# specify dimensions and create grid in Fourier domain 指定相应维度,并在傅氏域生成
dims = tuple(self.net.blobs["data"].data.shape[2:]) + \
(self.net.blobs["data"].data.shape[1], )
grid = np.mgrid[0:dims[0], 0:dims[1]]
# create frequency representation for pink noise
Sf = (grid[0] - (dims[0]-1)/2.0) ** 2 + \
(grid[1] - (dims[1]-1)/2.0) ** 2
Sf[np.where(Sf == 0)] = 1
Sf = np.sqrt(Sf)
Sf = np.dstack((Sf**int(init),)*dims[2])
# apply ifft to create pink noise and normalize
ifft_kernel = np.cos(2*np.pi*np.random.randn(*dims)) + \
1j*np.sin(2*np.pi*np.random.randn(*dims))
img_noise = np.abs(ifftn(Sf * ifft_kernel))
img_noise -= img_noise.min()
img_noise /= img_noise.max()
# preprocess the pink noise image 将白噪声图像输入到网络进行预处理
x0 = self.transformer.preprocess("data", img_noise)
return x0
def _create_pbar(self, max_iter):
"""
Creates a progress bar.
"""
self.grad_iter = 0
self.pbar = pb.ProgressBar()
self.pbar.widgets = ["Optimizing: ", pb.Percentage(),
" ", pb.Bar(marker=pb.AnimatedMarker()),
" ", pb.ETA()]
self.pbar.maxval = max_iter
def transfer_style(self, img_style, img_content, length=512, ratio=1e5, #风格变换函数
n_iter=512, init="-1", verbose=False, callback=None):
"""
Transfers the style of the artwork to the input image.
:param numpy.ndarray img_style:
A style image with the desired target style. 参数1:风格图style
:param numpy.ndarray img_content:
A content image in floating point, RGB format. 参数2:内容图content
:param function callback:
A callback function, which takes images at iterations. 参数:回调,当达到相应的迭代次数时返回当时的风格转移效果图片
"""
# assume that convnet input is square
orig_dim = min(self.net.blobs["data"].shape[2:])
# rescale the images 对输入图片尺寸进行调整
scale = max(length / float(max(img_style.shape[:2])),
orig_dim / float(min(img_style.shape[:2])))
img_style = rescale(img_style, STYLE_SCALE*scale)
scale = max(length / float(max(img_content.shape[:2])),
orig_dim / float(min(img_content.shape[:2])))
img_content = rescale(img_content, scale)
# compute style representations #计算style图在相应层的输出相应
self._rescale_net(img_style)
layers = self.weights["style"].keys()
net_in = self.transformer.preprocess("data", img_style)
gram_scale = float(img_content.size)/img_style.size
G_style = _compute_reprs(net_in, self.net, layers, [],
gram_scale=1)[0]
# compute content representations #计算content图在相应层的输出相应
self._rescale_net(img_content)
layers = self.weights["content"].keys()
net_in = self.transformer.preprocess("data", img_content)
F_content = _compute_reprs(net_in, self.net, [], layers)[1]
# generate initial net input #生成一张预处理的白噪声图,图片根据选定参数会在初始化阶段向content图和style图由不同程度的相似性
# "content" = content image, see kaishengtai/neuralart
if isinstance(init, np.ndarray):
img0 = self.transformer.preprocess("data", init)
elif init == "content":
img0 = self.transformer.preprocess("data", img_content)
elif init == "mixed":
img0 = 0.95*self.transformer.preprocess("data", img_content) + \
0.05*self.transformer.preprocess("data", img_style)
else:
img0 = self._make_noise_input(init)
# compute data bounds 计算数据极值
data_min = -self.transformer.mean["data"][:,0,0]
data_max = data_min + self.transformer.raw_scale["data"]
data_bounds = [(data_min[0], data_max[0])]*(img0.size/3) + \
[(data_min[1], data_max[1])]*(img0.size/3) + \
[(data_min[2], data_max[2])]*(img0.size/3)
# optimization params 优化
grad_method = "L-BFGS-B"
reprs = (G_style, F_content)
minfn_args = {
"args": (self.net, self.weights, self.layers, reprs, ratio),
"method": grad_method, "jac": True, "bounds": data_bounds,
"options": {"maxcor": 8, "maxiter": n_iter, "disp": verbose}
}
# optimize
self._callback = callback
minfn_args["callback"] = self.callback
if self.use_pbar and not verbose:
self._create_pbar(n_iter)
self.pbar.start()
res = minimize(style_optfn, img0.flatten(), **minfn_args).nit
self.pbar.finish()
else:
res = minimize(style_optfn, img0.flatten(), **minfn_args).nit
return res
def main(args):
"""
Entry point.
"""
# logging 打印想改数据
level = logging.INFO if args.verbose else logging.DEBUG
logging.basicConfig(format=LOG_FORMAT, datefmt="%H:%M:%S", level=level)
logging.info("Starting style transfer.")
# set GPU/CPU mode 模式选择与设置
if args.gpu_id == -1:
caffe.set_mode_cpu()
logging.info("Running net on CPU.")
else:
caffe.set_device(args.gpu_id)
caffe.set_mode_gpu()
logging.info("Running net on GPU {0}.".format(args.gpu_id))
# load images 加载style和content图片
img_style = caffe.io.load_image(args.style_img)
img_content = caffe.io.load_image(args.content_img)
logging.info("Successfully loaded images.")
# artistic style class 艺术风格转换
use_pbar = not args.verbose
st = StyleTransfer(args.model.lower(), use_pbar=use_pbar)
logging.info("Successfully loaded model {0}.".format(args.model))
# perform style transfer 进行艺术风格转换并打印所需时间
start = timeit.default_timer()
n_iters = st.transfer_style(img_style, img_content, length=args.length,
init=args.init, ratio=np.float(args.ratio),
n_iter=args.num_iters, verbose=args.verbose)
end = timeit.default_timer()
logging.info("Ran {0} iterations in {1:.0f}s.".format(n_iters, end-start))
img_out = st.get_generated()
# output path
if args.output is not None:
out_path = args.output
else:
out_path_fmt = (os.path.splitext(os.path.split(args.content_img)[1])[0],
os.path.splitext(os.path.split(args.style_img)[1])[0],
args.model, args.init, args.ratio, args.num_iters)
out_path = "outputs/{0}-{1}-{2}-{3}-{4}-{5}.jpg".format(*out_path_fmt)
# DONE!
imsave(out_path, img_as_ubyte(img_out))
logging.info("Output saved to {0}.".format(out_path))
if __name__ == "__main__":
args = parser.parse_args()
main(args)