Tensorflow-gpu+Keras+Pycharm+Yolo3人脸识别模型训练、图片/视频测试的入门教程与坑
本文内容是承接上文的深度学习Python环境下的配置方法进行,参照了许多他人的经验博客并加以总结,如果环境不同的话,可以只看经验部分
零、训练环境和源代码准备
E3-1231V3+GTX970(4G)
YOLO3代码下载:https://github.com/qqwweee/keras-yolo3
一、训练相关文件(夹)的创建
- 按照下图建立红圈画的文件夹
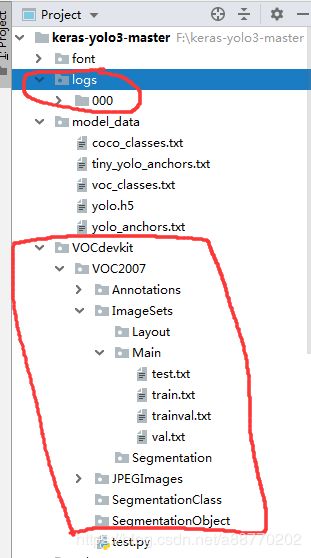
- 准备好你拿来训练的图片和测试用的图片(视频),图片放到ImageSets文件夹中,然后用labelImg这个工具去把训练用图片里准确地标注出你要识别的物体并生成xml文件(我用的是人脸识别就标人脸了),标注方法如下:
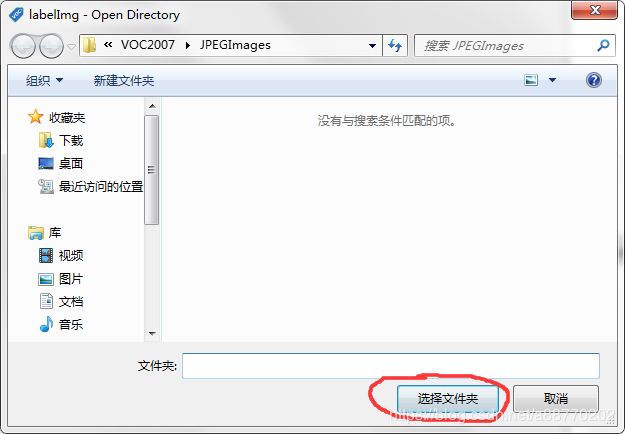
2.1 在labelImg中选择你存放图片的ImageSets文件夹

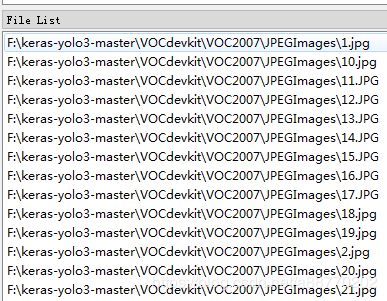
2.2 然后右边自动读取了图片列表
2.3 按W键(或者点Create RectBox按钮)光标出现准线,然后按住把人脸框出来像这样

给框出来的人脸起个类别名字,点ok,再按Ctrl+S(或者点Save按钮)生成同名的xml文件。 - 把这些xml文件移动到Annotations文件夹中
- 在VOC2007下新建一个python文件来运行以下代码,如此生成ImageSet/Main目录下的四个文件
import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行之后Main目录下生成了四个文件
- 生成yolo3所需的train.txt、val.txt、test.txt文件
5.1 修改voc_annotation.py中的classes数组为你自己刚才标注的那几个类别,我是用习主席和安倍晋三、巴赫三个人的人脸训练,所以改成这样

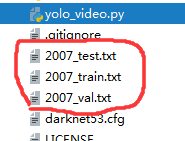
5.2运行voc_annotation.py,生成三个文件
二、修改部分文件内容
- 修改yolo3.cfg文件
打开yolo3.cfg文件。搜索yolo(共出现三次),每次按下图红字修改

- 把model_data下的voc_classes.txt内容改为你标记的类别,我的是这样:
- 修改train.py文件,用以下代码替换:
"""
Retrain the YOLO model for your own dataset.
"""
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
def _main():
annotation_path = '2007_train.txt'
log_dir = 'logs/000/'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/yolo_anchors.txt'
class_names = get_classes(classes_path)
anchors = get_anchors(anchors_path)
input_shape = (416,416) # multiple of 32, hw
model = create_model(input_shape, anchors, len(class_names) )
train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'):
model.compile(optimizer='adam', loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5",
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
batch_size = 10
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.shuffle(lines)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=500,
initial_epoch=0)
model.save_weights(log_dir + 'trained_weights.h5')
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False,
weights_path='model_data/yolo_weights.h5'):
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body:
# Do not freeze 3 output layers.
num = len(model_body.layers)-7
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
np.random.shuffle(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
i %= n
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i += 1
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
if n==0 or batch_size<=0: return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == '__main__':
_main()
三、开始训练
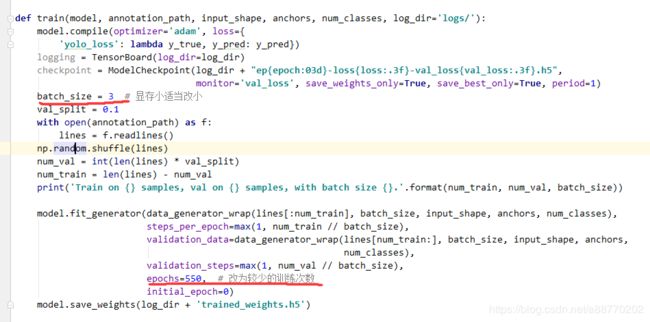
运行train.py,如果出现OOM以及chunk报错,说明你显存不够,尝试把下图画出的两个参数适当改小(batch_size改到2还不行就考虑改epoch吧,还溢出我暂时也不知道咋办了)
然后这样训练一会儿(emmm性能可以的电脑估计十几二十分钟吧,反正小Demo用不用太长时间)得到trained_weights.h5文件
四、视频流和图片的测试
这里有个大坑,我搜到的许多博主只测试了图片,并没有视频文件的测试,导致我拿视频去试要么啥都测不到,要么标记框瞎框,有的边界都溢出int了(一度怀疑人生),后来经同学提示说可能是opencv的图片读取BGR顺序和Image图片的RGB读取顺序不同,然后看了一下detect_video函数发现拿图片帧去处理的是Image而用cv2.show的还是Image顺序,确实没转换过去,于是百度了一波转换方法,改了改代码就可以正常识别了。修改后代码如下:
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC))
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))#Opencv转PIL
image = yolo.detect_image(image)
result = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)#显示的时候再PIL转回Opencv
#
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
#
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
# if isOutput:
# out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
在yolo.py文件末尾加上以下代码再运行,用于测试图片/视频流,否则官方的代码只是写好了函数,并没有给你写入口调用啥的。
def detect_img(yolo):
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = yolo.detect_image(image)
r_image.show()
yolo.close_session()
if __name__ == '__main__':
if (int(input("Please input detect_type 1->image, 2->video\n")) == 1):
detect_img(YOLO())
else:
detect_video(YOLO(), input("Input video filename:\n"))
输入的是图片或者视频的相对路径(Pycharm里右键你要测试的图片/视频,点Copy Relative Path就复制下来啦)
四、一点点经验
训练的出现的val_loss到十几的时候差不多可以在小Demo里挺准确得框出来了,再大一些效果应该会变差
五、参考博客
https://blog.csdn.net/mingqi1996/article/details/83343289
https://blog.csdn.net/davidlee8086/article/details/79693079
https://blog.csdn.net/Patrick_Lxc/article/details/80615433
https://blog.csdn.net/u012746060/article/details/81183006