NLP:语言表示之词向量——从onehot到word2vector:CBOW和Skip-Gram
入门NLP:语言表示之词向量——从onehot到word2vector:CBOW和Skip-Gram
笔者在入学期间从计算机视觉方面来学习深度学习理论,然后在一次实习中,恰巧接触到了NLP领域,并从事了NLP文本分类相关的工作,之后的几篇帖子中也会较为详细的介绍一下相关知识,以便自己更好的梳理。
在计算机视觉中,我们处理的数据为图片,其中图片本身就是像素矩阵,也就是说本身为一种数值,可以直接拿来进行相关的处理,但是NLP中要处理的大多为为字符数据,这种数据对于模型来讲就无法直接处理,需要进行转为计算机可以理解的向量形式才能进行训练。
词向量的表示
一般来讲,将字符表示为向量,有两种表示方式:one-hot vector和Distributed representation
1.one-hot vector
在以往的处理中,最为直观的做法就是One-hot Representation,做过数据挖掘方面的同学肯定对此不陌生,它就是将一个词映射为一个一维的向量,只有一个元素为1,其余全部为0,并且其他词的向量不能和它相同。如下图:

- 注意:1. 这种方式将数据以稀疏方式存储,使用起来十分简洁。2. 然而,每个词之间是独立的,没法表示出词语之间的相关信息。
2.Distributed representation
one-hot编码方式只是将字符进行符号量化,并没有考虑任何语义信息。 所以在 distributional hypothesis中,Harris提出上下文相似的词,其语义是相似的。因此,可以将一个词映射为一个低维实数向量(为数值分布),如[0.856,0.369,0.159,0.458,........,1.568],一方面降低了特征维度,另一方面挖掘了word之间的关联性。
- 注意:1.考虑了词之间的相似关系。 2.包含了更多的信息,并且每一维都有特定的含义
词向量模型
这里主要介绍一下word2vector模型,这个模型的主要想法就是利用模型将词表征为可以处理的向量,得到的词向量是我们上述说的Distributed representation表现形式。
这里主要讲一下较为重要的CBOW和Skip-Gram两种算法
1.CBOW算法
论文可以参考:Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.

我们针对The quick brown fox jumps over the lazy dog.这句话来进行讲解。
CBOW算法从上图网络结构上来看,是采用了使用上下文单词来预测中心词的方法来获得词向量。
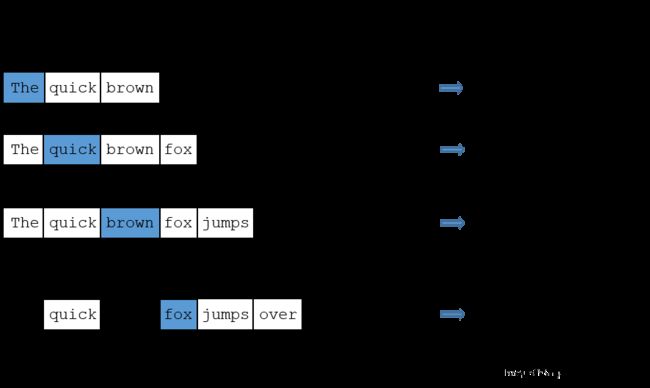
首先,他的上下单词是如何确定的呢? 在CBOW中,会定义一个为window_size的参数,假如window的大小为2,那么中心词的前2个词和后面2个词就被选入了我们的窗口里,以brown为例,上下文单词为['The ', 'quick ', ‘fox’, ‘jumps’]。
下面的图示就很好的展示了这个过程,右侧的train samples就是(input word, output word) 形式的训练数据
获得了训练样本,还是不够的,模型只能接受数值型数据,对于字符级数据无法完成相应的任务。
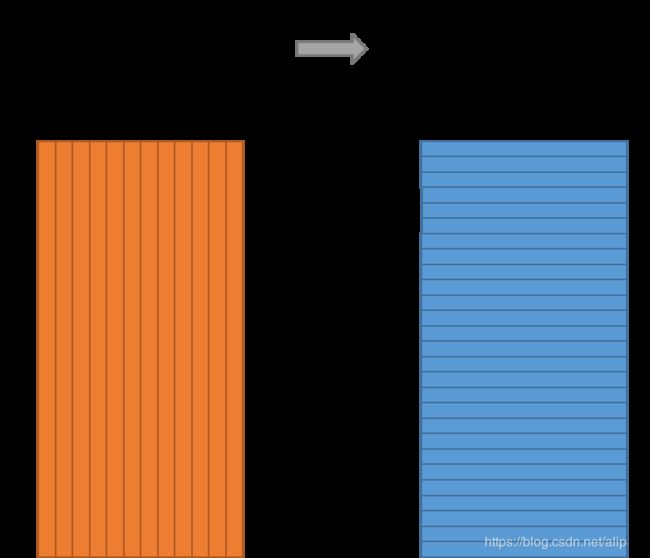
之后,模型先将每个字符处理为one-hot形式,其中维度大小为词表的大小(不同词的个数)。例如,一篇文章由1000个不同的词构成,那么词表大小即为1000,每个词(quick)的one-hot即为11000大小*。然后,将one-hot向量进行相加。
以The quick brown fox jumps over the lazy dog.,预测brown 为例。
the:[1,0,0,0…0,0] , X1
quick:[0,1,0,0…0,0], X2
fox :[0,0,1,0…0,0], X3
jumps :[0,0,0,1…0,0], X4
brown目标向量为:[0,0,0,0,1,…0], Y
输入向量为:X = X1 +X2+X3+X4, 即为[1,1,1,1,0,0…0]
获得了一个输入向量以及目标向量后,我们就可以将输入向量X输入全连接层(设置好维度参数)中,进行参数的优化训练。这里优化的目标是让模型能够学的词与词之间的上下文关系,我们的代价函数就是使得sofamax中预测的分布y与真实值Y这两个矩阵的交叉熵最小化,也可以最小化这两个矩阵的差平方,即损失值。

训练结束后,对我们真正有用的是隐层中的权重W,这里就是我们所需要的词向量。如下图所示:
我们举个简单的例子,来看一下怎么提取出一个词的词向量表达:
The quick brown fox jumps over the lazy dog.
假设我们获取的隐层权重分布如右下矩阵,我们想要获取jumps 的词向量,之前jumps 的one-hot为[0,0,0,1,0…0],于是我们将one-hot与权重矩阵相乘,便得到了相应的向量表示。

2.Skip-Gram算法
Skip-Gram算法与CBOW算法的结构相似。不同的是:skip-gram模型的输入是一个单词W1,它的输出是W1的上下文单词Wo1,…,Woc。
因此,模型的输入是单纯的中心词的one-hot表示形式的向量,输出就是softmax层中对词表中所有词的预测概率,真实标签为window中词的one-hot。当然,与CBOW不同的是,没有向量相加的过程。其余过程相似。
