spark集群安装和基本使用
spark官网下载地址:http://spark.apache.org/downloads.html
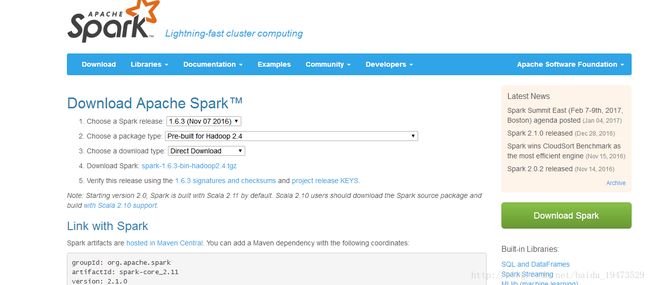
我下载的是1.6.3兼容hadoop2.4的版本spark-1.6.3-bin-hadoop2.4
一、下载、解压
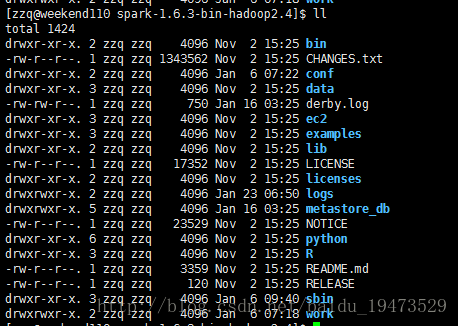
目录结构
二、修改配置文件
[zzq@weekend110 spark-1.6.3-bin-hadoop2.4]$ cd conf/
[zzq@weekend110 conf]$ ll
total 36
-rw-r--r--. 1 zzq zzq 987 Nov 2 15:25 docker.properties.template
-rw-r--r--. 1 zzq zzq 1105 Nov 2 15:25 fairscheduler.xml.template
-rw-r--r--. 1 zzq zzq 1734 Nov 2 15:25 log4j.properties.template
-rw-r--r--. 1 zzq zzq 6671 Nov 2 15:25 metrics.properties.template
-rw-r--r--. 1 zzq zzq 878 Jan 6 07:22 slaves
-rw-r--r--. 1 zzq zzq 1292 Nov 2 15:25 spark-defaults.conf.template
-rwxr-xr-x. 1 zzq zzq 4345 Jan 6 06:53 spark-env.sh
进入conf目录,我把spark-env.sh和slaves后面的.template删掉了,分别修改这2个配置文件
vim spark-env.shexport JAVA_HOME=/usr/local/jdk1.7.0_79
export SPARK_MASTER_IP=192.168.16.130
export SPARK_MASTER_PORT=7077
[zzq@weekend110 conf]$ cat spark-env.sh
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site.
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# - SPARK_CLASSPATH, default classpath entries to append
# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_CLASSPATH, default classpath entries to append
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Options read in YARN client mode
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_EXECUTOR_INSTANCES, Number of executors to start (Default: 2)
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_YARN_APP_NAME, The name of your application (Default: Spark)
# - SPARK_YARN_QUEUE, The hadoop queue to use for allocation requests (Default: ‘default’)
# - SPARK_YARN_DIST_FILES, Comma separated list of files to be distributed with the job.
# - SPARK_YARN_DIST_ARCHIVES, Comma separated list of archives to be distributed with the job.
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_IP, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_INSTANCES, to set the number of worker processes per node
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
export JAVA_HOME=/usr/local/jdk1.7.0_79
export SPARK_MASTER_IP=192.168.16.130
export SPARK_MASTER_PORT=7077
修改slaves文件,指定worker
[zzq@weekend110 conf]$ vim slaves
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
weekend111
weekend112我添加了hosts
weekend111地址是192.168.16.135weekend112地址是192.168.16.136
远程拷贝
scp -r spark-1.6.3-bin-hadoop2.4/ weekend111:/home/zzq/app
scp -r spark-1.6.3-bin-hadoop2.4/ weekend112:/home/zzq/app三、使用spark
启动spark
[zzq@weekend110 spark-1.6.3-bin-hadoop2.4]$ ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/zzq/app/spark-1.6.3-bin-hadoop2.4/logs/spark-zzq-org.apache.spark.deploy.master.Master-1-weekend110.out
weekend111: starting org.apache.spark.deploy.worker.Worker, logging to /home/zzq/app/spark-1.6.3-bin-hadoop2.4/logs/spark-zzq-org.apache.spark.deploy.worker.Worker-1-weekend111.out
weekend112: starting org.apache.spark.deploy.worker.Worker, logging to /home/zzq/app/spark-1.6.3-bin-hadoop2.4/logs/spark-zzq-org.apache.spark.deploy.worker.Worker-1-weekend112.out
weekend111: failed to launch org.apache.spark.deploy.worker.Worker:
weekend111: full log in /home/zzq/app/spark-1.6.3-bin-hadoop2.4/logs/spark-zzq-org.apache.spark.deploy.worker.Worker-1-weekend111.out
weekend112: failed to launch org.apache.spark.deploy.worker.Worker:
weekend112: full log in /home/zzq/app/spark-1.6.3-bin-hadoop2.4/logs/spark-zzq-org.apache.spark.deploy.worker.Worker-1-weekend112.out
查看进程一个master二个Worker
[zzq@weekend110 spark-1.6.3-bin-hadoop2.4]$ jps
2156 Jps
2093 Master
[zzq@weekend111 ~]$ jps
2019 Jps
1969 Worker[zzq@weekend112 ~]$ jps
2129 Jps
2079 Worker
spark的web界面

spark shell使用
[zzq@weekend110 spark-1.6.3-bin-hadoop2.4]$ ./bin/spark-shell --master spark://192.168.16.130:7077 --executor-memory 1G --total-executor-cores 2
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.3
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) Client VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
17/02/03 06:00:15 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
17/02/03 06:00:18 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
17/02/03 06:00:26 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/02/03 06:00:26 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
Java HotSpot(TM) Client VM warning: You have loaded library /tmp/libnetty-transport-native-epoll5980461953900249225.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'.
17/02/03 06:00:31 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
17/02/03 06:00:32 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
SQL context available as sqlContext.
scala>
spark-shell参数详解
--executor-memory 是指定每个executor(执行器)占用的内存
--total-executor-cores是所有executor总共使用的cpu核数
--executor-cores是每个executor使用的cpu核数 例子:路径是hdfs上的wc.txt文件,reduce结果也返回到hdfs
scala> sc.textFile("hdfs://weekend110:9000/hadoop/data/wc.txt").flatMap(_.split(" "))
res17: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[15] at flatMap at :28
scala> res17.map((_,1)).reduceByKey(_ + _)
res18: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[17] at reduceByKey at :30
scala> res18.saveAsTextFile("hdfs://weekend110:9000/hadoop/data/output") 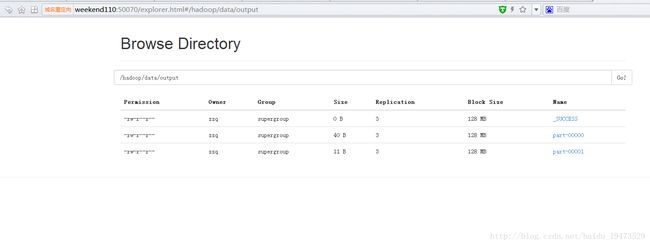
这是运行结果
[zzq@weekend110 ~]$ hadoop fs -cat /hadoop/data/wc.txt
hello jetty hadoop apple
thank hello
Scala程序的例子
package Test2
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object TestSpark {
def main(args: Array[String]) {
if(args.length < 2){
println("args params error");
}
/** spark例子 */
val masterAddr = "spark://weekend110:7077";
val conf = new SparkConf().setAppName("wordCount").setMaster(masterAddr);
val sc = new SparkContext(conf);
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(args(1))
sc.stop();
}
}我用maven打的包发现一个异常
Java HotSpot(TM) Client VM warning: You have loaded library /tmp/libnetty-transport-native-epoll9051232252112870247.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'.
Exception in thread "main" java.io.IOException: No FileSystem for scheme: c
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2385)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2392)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:89)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2431)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2413)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:368)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:256)
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:228)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:304)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:202)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.Partitioner$.defaultPartitioner(Partitioner.scala:65)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$reduceByKey$3.apply(PairRDDFunctions.scala:331)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$reduceByKey$3.apply(PairRDDFunctions.scala:331)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.PairRDDFunctions.reduceByKey(PairRDDFunctions.scala:330)
at Test2.TestSpark$.main(TestSpark.scala:20)
at Test2.TestSpark.main(TestSpark.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
我修改了pom.xml,build部分
src/main/scala/
org.scala-tools
maven-scala-plugin
compile
testCompile
2.10.3
org.apache.maven.plugins
maven-shade-plugin
2.2
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
reference.conf
cn.chinahadoop.spark.Analysis
META-INF/services/org.apache.hadoop.fs.FileSystem
运行:
[zzq@weekend110 spark-1.6.3-bin-hadoop2.4]$ ./bin/spark-submit --master spark://weekend110:7077 --name WordCountByscala --class Test2.TestSpark --executor-memory 1G --total-executor-cores 2 ./wordCount.jar hdfs://weekend110:9000/hadoop/data/wc.txt hdfs://weekend110:9000/hadoop/data/output
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/02/03 08:40:14 INFO SparkContext: Running Spark version 1.6.3
17/02/03 08:40:14 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/02/03 08:40:15 INFO SecurityManager: Changing view acls to: zzq
17/02/03 08:40:15 INFO SecurityManager: Changing modify acls to: zzq
17/02/03 08:40:15 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(zzq); users with modify permissions: Set(zzq)
17/02/03 08:40:15 INFO Utils: Successfully started service 'sparkDriver' on port 47906.
17/02/03 08:40:15 INFO Slf4jLogger: Slf4jLogger started
17/02/03 08:40:15 INFO Remoting: Starting remoting
17/02/03 08:40:15 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:54718]
17/02/03 08:40:15 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 54718.
17/02/03 08:40:15 INFO SparkEnv: Registering MapOutputTracker
17/02/03 08:40:15 INFO SparkEnv: Registering BlockManagerMaster
17/02/03 08:40:15 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-ee825a30-c3e4-45d8-90dc-ea822974efbc
17/02/03 08:40:15 INFO MemoryStore: MemoryStore started with capacity 517.4 MB
17/02/03 08:40:16 INFO SparkEnv: Registering OutputCommitCoordinator
17/02/03 08:40:16 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/02/03 08:40:16 INFO SparkUI: Started SparkUI at http://192.168.16.130:4040
17/02/03 08:40:16 INFO HttpFileServer: HTTP File server directory is /tmp/spark-2ec0fcd4-587e-4620-bd54-6cacfddc54ee/httpd-2043fbfd-e881-4f58-865c-c4eba096324a
17/02/03 08:40:16 INFO HttpServer: Starting HTTP Server
17/02/03 08:40:16 INFO Utils: Successfully started service 'HTTP file server' on port 39554.
17/02/03 08:40:16 INFO SparkContext: Added JAR file:/home/zzq/app/spark-1.6.3-bin-hadoop2.4/./wordCount.jar at http://192.168.16.130:39554/jars/wordCount.jar with timestamp 1486140016635
17/02/03 08:40:16 INFO AppClient$ClientEndpoint: Connecting to master spark://weekend110:7077...
17/02/03 08:40:17 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20170203084017-0002
17/02/03 08:40:18 INFO AppClient$ClientEndpoint: Executor added: app-20170203084017-0002/0 on worker-20170203055642-192.168.16.135-59890 (192.168.16.135:59890) with 1 cores
17/02/03 08:40:18 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170203084017-0002/0 on hostPort 192.168.16.135:59890 with 1 cores, 1024.0 MB RAM
17/02/03 08:40:18 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 42663.
17/02/03 08:40:18 INFO NettyBlockTransferService: Server created on 42663
17/02/03 08:40:18 INFO BlockManagerMaster: Trying to register BlockManager
17/02/03 08:40:18 INFO AppClient$ClientEndpoint: Executor added: app-20170203084017-0002/1 on worker-20170203055645-192.168.16.136-42516 (192.168.16.136:42516) with 1 cores
17/02/03 08:40:18 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170203084017-0002/1 on hostPort 192.168.16.136:42516 with 1 cores, 1024.0 MB RAM
17/02/03 08:40:18 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.16.130:42663 with 517.4 MB RAM, BlockManagerId(driver, 192.168.16.130, 42663)
17/02/03 08:40:18 INFO BlockManagerMaster: Registered BlockManager
17/02/03 08:40:19 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/1 is now RUNNING
17/02/03 08:40:19 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
17/02/03 08:40:19 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/0 is now RUNNING
17/02/03 08:40:21 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
17/02/03 08:40:21 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 134.3 KB, free 517.3 MB)
17/02/03 08:40:22 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 12.4 KB, free 517.3 MB)
17/02/03 08:40:22 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.16.130:42663 (size: 12.4 KB, free: 517.4 MB)
17/02/03 08:40:22 INFO SparkContext: Created broadcast 0 from textFile at TestSpark.scala:20
Java HotSpot(TM) Client VM warning: You have loaded library /tmp/libnetty-transport-native-epoll5070917405505758915.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'.
17/02/03 08:40:26 INFO FileInputFormat: Total input paths to process : 1
17/02/03 08:40:26 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
17/02/03 08:40:26 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
17/02/03 08:40:26 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
17/02/03 08:40:26 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
17/02/03 08:40:26 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
17/02/03 08:40:27 INFO SparkContext: Starting job: saveAsTextFile at TestSpark.scala:20
17/02/03 08:40:27 INFO DAGScheduler: Registering RDD 3 (map at TestSpark.scala:20)
17/02/03 08:40:27 INFO DAGScheduler: Got job 0 (saveAsTextFile at TestSpark.scala:20) with 2 output partitions
17/02/03 08:40:27 INFO DAGScheduler: Final stage: ResultStage 1 (saveAsTextFile at TestSpark.scala:20)
17/02/03 08:40:27 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
17/02/03 08:40:27 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
17/02/03 08:40:27 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at TestSpark.scala:20), which has no missing parents
17/02/03 08:40:27 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 517.3 MB)
17/02/03 08:40:27 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 517.3 MB)
17/02/03 08:40:27 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.16.130:42663 (size: 2.3 KB, free: 517.4 MB)
17/02/03 08:40:27 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006
17/02/03 08:40:27 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at TestSpark.scala:20)
17/02/03 08:40:27 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
17/02/03 08:40:42 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
17/02/03 08:40:57 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
17/02/03 08:41:08 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/1 is now EXITED (Command exited with code 1)
17/02/03 08:41:08 INFO SparkDeploySchedulerBackend: Executor app-20170203084017-0002/1 removed: Command exited with code 1
17/02/03 08:41:08 INFO BlockManagerMaster: Removal of executor 1 requested
17/02/03 08:41:08 INFO SparkDeploySchedulerBackend: Asked to remove non-existent executor 1
17/02/03 08:41:08 INFO AppClient$ClientEndpoint: Executor added: app-20170203084017-0002/2 on worker-20170203055645-192.168.16.136-42516 (192.168.16.136:42516) with 1 cores
17/02/03 08:41:08 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170203084017-0002/2 on hostPort 192.168.16.136:42516 with 1 cores, 1024.0 MB RAM
17/02/03 08:41:08 INFO BlockManagerMasterEndpoint: Trying to remove executor 1 from BlockManagerMaster.
17/02/03 08:41:12 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
17/02/03 08:41:14 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/2 is now RUNNING
17/02/03 08:41:27 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
17/02/03 08:41:37 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/0 is now EXITED (Command exited with code 1)
17/02/03 08:41:37 INFO SparkDeploySchedulerBackend: Executor app-20170203084017-0002/0 removed: Command exited with code 1
17/02/03 08:41:37 INFO BlockManagerMaster: Removal of executor 0 requested
17/02/03 08:41:37 INFO SparkDeploySchedulerBackend: Asked to remove non-existent executor 0
17/02/03 08:41:37 INFO BlockManagerMasterEndpoint: Trying to remove executor 0 from BlockManagerMaster.
17/02/03 08:41:37 INFO AppClient$ClientEndpoint: Executor added: app-20170203084017-0002/3 on worker-20170203055642-192.168.16.135-59890 (192.168.16.135:59890) with 1 cores
17/02/03 08:41:37 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170203084017-0002/3 on hostPort 192.168.16.135:59890 with 1 cores, 1024.0 MB RAM
17/02/03 08:41:41 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/3 is now RUNNING
17/02/03 08:41:42 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
17/02/03 08:41:56 INFO SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (weekend112:60400) with ID 2
17/02/03 08:41:56 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, weekend112, partition 0,ANY, 2188 bytes)
17/02/03 08:42:00 INFO BlockManagerMasterEndpoint: Registering block manager weekend112:39103 with 517.4 MB RAM, BlockManagerId(2, weekend112, 39103)
17/02/03 08:42:26 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/3 is now EXITED (Command exited with code 1)
17/02/03 08:42:26 INFO SparkDeploySchedulerBackend: Executor app-20170203084017-0002/3 removed: Command exited with code 1
17/02/03 08:42:26 INFO BlockManagerMaster: Removal of executor 3 requested
17/02/03 08:42:26 INFO SparkDeploySchedulerBackend: Asked to remove non-existent executor 3
17/02/03 08:42:26 INFO BlockManagerMasterEndpoint: Trying to remove executor 3 from BlockManagerMaster.
17/02/03 08:42:26 INFO AppClient$ClientEndpoint: Executor added: app-20170203084017-0002/4 on worker-20170203055642-192.168.16.135-59890 (192.168.16.135:59890) with 1 cores
17/02/03 08:42:26 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170203084017-0002/4 on hostPort 192.168.16.135:59890 with 1 cores, 1024.0 MB RAM
17/02/03 08:42:28 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/4 is now RUNNING
17/02/03 08:42:43 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on weekend112:39103 (size: 2.3 KB, free: 517.4 MB)
17/02/03 08:42:45 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on weekend112:39103 (size: 12.4 KB, free: 517.4 MB)
17/02/03 08:43:03 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/4 is now EXITED (Command exited with code 1)
17/02/03 08:43:03 INFO SparkDeploySchedulerBackend: Executor app-20170203084017-0002/4 removed: Command exited with code 1
17/02/03 08:43:03 INFO BlockManagerMaster: Removal of executor 4 requested
17/02/03 08:43:03 INFO SparkDeploySchedulerBackend: Asked to remove non-existent executor 4
17/02/03 08:43:03 INFO BlockManagerMasterEndpoint: Trying to remove executor 4 from BlockManagerMaster.
17/02/03 08:43:03 INFO AppClient$ClientEndpoint: Executor added: app-20170203084017-0002/5 on worker-20170203055642-192.168.16.135-59890 (192.168.16.135:59890) with 1 cores
17/02/03 08:43:03 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170203084017-0002/5 on hostPort 192.168.16.135:59890 with 1 cores, 1024.0 MB RAM
17/02/03 08:43:04 INFO AppClient$ClientEndpoint: Executor updated: app-20170203084017-0002/5 is now RUNNING
17/02/03 08:43:08 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, weekend112, partition 1,ANY, 2188 bytes)
17/02/03 08:43:08 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 72590 ms on weekend112 (1/2)
17/02/03 08:43:08 INFO DAGScheduler: ShuffleMapStage 0 (map at TestSpark.scala:20) finished in 161.108 s
17/02/03 08:43:08 INFO DAGScheduler: looking for newly runnable stages
17/02/03 08:43:08 INFO DAGScheduler: running: Set()
17/02/03 08:43:08 INFO DAGScheduler: waiting: Set(ResultStage 1)
17/02/03 08:43:08 INFO DAGScheduler: failed: Set()
17/02/03 08:43:08 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at TestSpark.scala:20), which has no missing parents
17/02/03 08:43:08 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 173 ms on weekend112 (2/2)
17/02/03 08:43:08 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/02/03 08:43:09 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 57.2 KB, free 517.2 MB)
17/02/03 08:43:09 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 19.8 KB, free 517.2 MB)
17/02/03 08:43:09 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.16.130:42663 (size: 19.8 KB, free: 517.4 MB)
17/02/03 08:43:09 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006
17/02/03 08:43:09 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at TestSpark.scala:20)
17/02/03 08:43:09 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
17/02/03 08:43:09 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, weekend112, partition 0,NODE_LOCAL, 1950 bytes)
17/02/03 08:43:09 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on weekend112:39103 (size: 19.8 KB, free: 517.4 MB)
17/02/03 08:43:09 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to weekend112:60400
17/02/03 08:43:09 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 151 bytes
17/02/03 08:43:11 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, weekend112, partition 1,NODE_LOCAL, 1950 bytes)
17/02/03 08:43:11 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 2464 ms on weekend112 (1/2)
17/02/03 08:43:11 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at TestSpark.scala:20) finished in 2.685 s
17/02/03 08:43:11 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 237 ms on weekend112 (2/2)
17/02/03 08:43:11 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
17/02/03 08:43:11 INFO DAGScheduler: Job 0 finished: saveAsTextFile at TestSpark.scala:20, took 164.809417 s
17/02/03 08:43:12 INFO SparkUI: Stopped Spark web UI at http://192.168.16.130:4040
17/02/03 08:43:12 INFO SparkDeploySchedulerBackend: Shutting down all executors
17/02/03 08:43:12 INFO SparkDeploySchedulerBackend: Asking each executor to shut down
17/02/03 08:43:12 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/02/03 08:43:12 INFO MemoryStore: MemoryStore cleared
17/02/03 08:43:12 INFO BlockManager: BlockManager stopped
17/02/03 08:43:12 INFO BlockManagerMaster: BlockManagerMaster stopped
17/02/03 08:43:12 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/02/03 08:43:12 INFO SparkContext: Successfully stopped SparkContext
17/02/03 08:43:12 INFO ShutdownHookManager: Shutdown hook called
17/02/03 08:43:12 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
17/02/03 08:43:12 INFO ShutdownHookManager: Deleting directory /tmp/spark-2ec0fcd4-587e-4620-bd54-6cacfddc54ee
17/02/03 08:43:12 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
17/02/03 08:43:12 INFO ShutdownHookManager: Deleting directory /tmp/spark-2ec0fcd4-587e-4620-bd54-6cacfddc54ee/httpd-2043fbfd-e881-4f58-865c-c4eba096324a

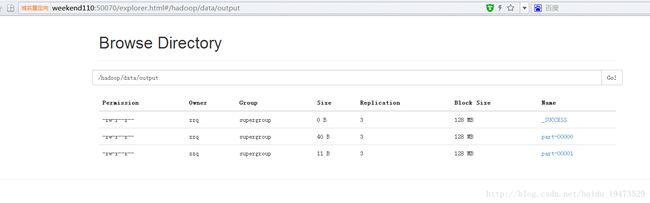
运行成功