第四章 利用Kinect抠图和自动拍照程序
第四章 利用Kinect抠图和自动拍照程序
在本篇博客中,我将详细介绍Kinect的一种特殊数据源,BodyIndex(人物索引二值图),Kinect就是利用这个数据源来区分目标是人体还是其他物体,有没有觉得功能很强大。说到这里,很多朋友就应该会想到如何利用Kinect去抠图了,主要是依靠这个数据源,把 Kinect获取的图像中的人体和其他物体(主要是背景)区分开来。另外一点是关于自动拍照程序的,大概想要实现的是,自己从网上找一些比较好的图片,结合抠图技术,把自己“PS”到指定的图片。这个程序感觉很有可玩性,而且这只是一种最简单和基本的玩法,大家可以根据自己的创意做出更好玩有趣有意义的东西。
Kinect中带了一种数据源,叫做BodyIndex,简单来说就是它利用深度摄像头识别出最多6个人体,并且用数据将属于人体的部分标记,将人体和背景区别开来。利用这一特性,就可以在环境中显示出人体的轮廓而略去背景的细节。我采用了下面两种方式来实现。
一、利用Kinect抠图
还是一样的风格,先上菜,再分析
抠图程序:
#include
#include
#include
using namespace std;
using namespace cv;
int main(void)
{
IKinectSensor * mySensor = nullptr; //Sensor
GetDefaultKinectSensor(&mySensor);
mySensor->Open();
IBodyIndexFrameSource * mySource = nullptr; //Source
mySensor->get_BodyIndexFrameSource(&mySource);
int height = 0, width = 0;
IFrameDescription * myDescription = nullptr;
mySource->get_FrameDescription(&myDescription);
myDescription->get_Height(&height);
myDescription->get_Width(&width);
IBodyIndexFrameReader * myReader = nullptr; //Reader
mySource->OpenReader(&myReader);
IBodyIndexFrame * myFrame = nullptr; //Frame
Mat img(height,width,CV_8UC3);
Vec3b color[7] = { Vec3b(0,0,255),Vec3b(0,255,255),Vec3b(255,255,255),Vec3b(0,255,0),Vec3b(255,0,0),Vec3b(255,0,255),Vec3b(0,0,0) };
while (1)
{
if (myReader->AcquireLatestFrame(&myFrame) == S_OK)
{
UINT size = 0;
BYTE * buffer = nullptr;
myFrame->AccessUnderlyingBuffer(&size,&buffer);
for (int i = 0; i < height; i++)
for (int j = 0; j < width; j++)
{
int index = buffer[i * width + j]; //0-5代表人体,其它值代表背景,用此将人体和背景渲染成不同颜色
if (index <= 5) //index小于5是人体部分,
img.at(i, j) = color[index];
Else //否则,不是人体部分,则给他显示黑色
img.at(i, j) = color[6];
}
imshow("TEST",img);
myFrame->Release();
}
if (waitKey(30) == VK_ESCAPE)
break;
}
myReader->Release();
myDescription->Release();
mySource->Release();
mySensor->Close();
mySensor->Release();
return 0;
} 看过前面几篇博客,就会发现,Kinect程序的复用性很大,也就是说不同程序之间有很多部分是共用的,相似度非常高,就算不同的部分你也会发现他们是有规律可循的,就像本系列第二篇第二部分介绍的常用API一样,基本步骤都差不多的。步骤和前面相似,不再赘述,关键在于对数据的处理。IBodyIndexFrame里的数据分两种,值在0-5之间的点代表的是人体(因此最多识别出6个人),大于5的值代表的是背景。所以要显示人体时,只要简单的把代表人体的点渲染成一种颜色,背景渲染成另外一种颜色就可以了。值得注意的是在写颜色表color时,要用Vec3b把数据强转一下,不然会有问题。
最终的效果就是这样:
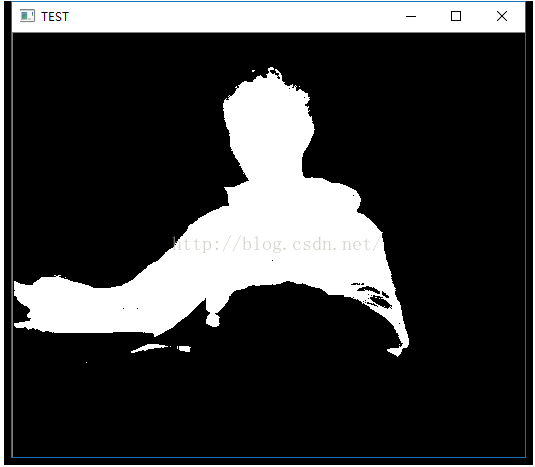
二、结合Kinect自动插图的拍照程序
前面一部分讲到了Kinect可以从环境中区分出人体来。因此可以利用这个功能,来把摄像头前的人合成进照片里,和利用Photoshop不同的是,这样合成进去的人是动态且实时的。
简单的思路
BodyIndex用的是深度数据,只能用来判断画面中的点属不属于人体而不能用来直接显示画面,Color图里的数据只能用来显示而没有其他功能。所以如果深度数据能和彩色数据配合的话,就能利用深度数据来识别出彩色数据中的哪些点属于人体。但是深度帧的分辨率是512 x 424,而彩色帧的分辨率是1920 x 1080,无法将他们对应起来。然而微软提供了一个叫ICoordinateMapper的类。
简单来说:将彩色图上的点转换到深度图的坐标系中->判断某点是否是人体->是的话从彩色图中取出此点,与背景替换。
照片合成程序:
#include
#include
#include
#include
using namespace std;
using namespace cv;
int main(void)
{
IKinectSensor * mySensor = nullptr;
GetDefaultKinectSensor(&mySensor);
mySensor->Open();
//************************准备好彩色图像的Reader并获取尺寸*******************************
int colorHeight = 0, colorWidth = 0;
IColorFrameSource * myColorSource = nullptr;
IColorFrameReader * myColorReader = nullptr;
IFrameDescription * myDescription = nullptr;
{
mySensor->get_ColorFrameSource(&myColorSource);
myColorSource->OpenReader(&myColorReader);
myColorSource->get_FrameDescription(&myDescription);
myDescription->get_Height(&colorHeight);
myDescription->get_Width(&colorWidth);
myDescription->Release();
myColorSource->Release();
}
//************************准备好深度图像的Reader并获取尺寸*******************************
int depthHeight = 0, depthWidth = 0;
IDepthFrameSource * myDepthSource = nullptr;
IDepthFrameReader * myDepthReader = nullptr;
{
mySensor->get_DepthFrameSource(&myDepthSource);
myDepthSource->OpenReader(&myDepthReader);
myDepthSource->get_FrameDescription(&myDescription);
myDescription->get_Height(&depthHeight);
myDescription->get_Width(&depthWidth);
myDescription->Release();
myDepthSource->Release();
}
//************************准备好人体索引图像的Reader并获取尺寸****************************
int bodyHeight = 0, bodyWidth = 0;
IBodyIndexFrameSource * myBodyIndexSource = nullptr;
IBodyIndexFrameReader * myBodyIndexReader = nullptr;
{
mySensor->get_BodyIndexFrameSource(&myBodyIndexSource);
myBodyIndexSource->OpenReader(&myBodyIndexReader);
myDepthSource->get_FrameDescription(&myDescription);
myDescription->get_Height(&bodyHeight);
myDescription->get_Width(&bodyWidth);
myDescription->Release();
myBodyIndexSource->Release();
}
//************************为各种图像准备buffer,并且开启Mapper*****************************
UINT colorDataSize = colorHeight * colorWidth;
UINT depthDataSize = depthHeight * depthWidth;
UINT bodyDataSize = bodyHeight * bodyWidth;
Mat temp = imread("test.jpg"),background; //获取背景图
resize(temp,background,Size(colorWidth,colorHeight)); //调整至彩色图像的大小
ICoordinateMapper * myMaper = nullptr; //开启mapper
mySensor->get_CoordinateMapper(&myMaper);
Mat colorData(colorHeight, colorWidth, CV_8UC4); //准备buffer
UINT16 * depthData = new UINT16[depthDataSize];
BYTE * bodyData = new BYTE[bodyDataSize];
DepthSpacePoint * output = new DepthSpacePoint[colorDataSize];
//************************把各种图像读进buffer里,然后进行处理*****************************
while (1)
{
IColorFrame * myColorFrame = nullptr;
while (myColorReader->AcquireLatestFrame(&myColorFrame) != S_OK); //读取color图
myColorFrame->CopyConvertedFrameDataToArray(colorDataSize * 4, colorData.data, ColorImageFormat_Bgra);
myColorFrame->Release();
IDepthFrame * myDepthframe = nullptr;
while (myDepthReader->AcquireLatestFrame(&myDepthframe) != S_OK); //读取depth图
myDepthframe->CopyFrameDataToArray(depthDataSize, depthData);
myDepthframe->Release();
IBodyIndexFrame * myBodyIndexFrame = nullptr; //读取BodyIndex图
while (myBodyIndexReader->AcquireLatestFrame(&myBodyIndexFrame) != S_OK);
myBodyIndexFrame->CopyFrameDataToArray(bodyDataSize, bodyData);
myBodyIndexFrame->Release();
Mat copy = background.clone(); //复制一份背景图来做处理
if (myMaper->MapColorFrameToDepthSpace(depthDataSize, depthData, colorDataSize, output) == S_OK)
{
for (int i = 0; i < colorHeight; ++ i)
for (int j = 0; j < colorWidth;++ j)
{
DepthSpacePoint tPoint = output[i * colorWidth + j]; //取得彩色图像上的一点,此点包含了它对应到深度图上的坐标
if (tPoint.X >= 0 && tPoint.X < depthWidth && tPoint.Y >= 0 && tPoint.Y < depthHeight) //判断是否合法
{
int index = (int)tPoint.Y * depthWidth + (int)tPoint.X; //取得彩色图上那点对应在BodyIndex里的值(注意要强转)
if (bodyData[index] <= 5) //如果判断出彩色图上某点是人体,就用它来替换背景图上对应的点
{
Vec4b color = colorData.at(i, j);
copy.at(i, j) = Vec3b(color[0], color[1], color[2]);
}
}
}
imshow("TEST",copy);
}
if (waitKey(30) == VK_ESCAPE)
break;
}
delete[] depthData; //记得各种释放
delete[] bodyData;
delete[] output;
myMaper->Release();
myColorReader->Release();
myDepthReader->Release();
myBodyIndexReader->Release();
mySensor->Close();
mySensor->Release();
return 0;
} 详细说明:
SDK中提供了一个叫ICoordinateMapper的类,功能就是坐标系之间的互相转换,用来解决数据源的分辨率不同导致点对应不起来的问题。我们需要的是将彩色图像中的点与深度图像中的点一一对应起来,因此使用其中的MapColorFrameToDepthSpace()这个函数。
首选,需要准备好三种数据源:Color、BodyIndex、Depth,其中前两个是完成功能本来就需要的,第三个是转换坐标系时需要,无法直接把Color的坐标系映射到BodyIndex中,只能映射到Depth中。
然后是读取背景图,读取之后也要转换成Color图的尺寸,这样把Color中的点贴过去时坐标就不用再转换,直接替换就行。接下来也要读取三种Frame,为了易读性,不如把准备工作在前面都做完,在这一步直接用Reader就行。
然后,利用MapColorFrameToDepthSpace(),将彩色帧映射到深度坐标系,它需要4个参数,第1个是深度帧的大小,第2个是深度数据,第3个是彩色帧的大小,第4个是一个DepthSpacePoint的数组,它用来储存彩色空间中的每个点对应到深度空间的坐标。
要注意,这个函数只是完成坐标系的转换,也就是说它对于彩色坐标系中的每个点,都给出了一个此点对应到深度坐标系中的坐标,并不涉及到具体的ColorFrame。
最后,遍历彩色图像,对于每一点,都取出它对应的深度坐标系的坐标,然后把这个坐标放入BodyIndex的数据中,判断此点是否属于人体,如果属于,就把这点从彩色图中取出,跟背景图中同一坐标的点替换。
要注意的是,DepthSpacePoint中的X和Y的值都是float的,用它们来计算在BodyIndex里的坐标时,需要强转成int,不然画面就会不干净,一些不属于人体的地方也被标记成了人体被替换掉。
实验效果图:

从图上比较容易看到人体周围有许多毛刺,并不是很光滑,其实也正常,因为这是通过Kinect的BodyIndex数据源获取的人体部分,也就是深度图像,精确度肯定没有达到那么高,所以边缘有很多毛刺很正常。应该可以利用一些图成像处理技术进行去除或者改善,关于这个方面大家可以大胆去尝试,看下能不能把这个效果做的更好一点,边缘更平滑一点。
参考文章:http://www.cnblogs.com/xz816111/p/5185766.html
http://www.cnblogs.com/xz816111/p/5185010.html
到这里为止,都还只是显示图像,并没有照相功能,也就是把图片保存下来。这部分需要用到动作识别,通过指定动作来控制Kinect拍照,这些动作就比较随意了,可以是各种动作和pose,只要能被Kinect识别出来就可以了。由于这部分程序太长了,这里不便贴出来,文末提供完整程序下载。效果图如下
这里提供一些关键的代码,主要是动作识别部分的。代码片段如下:
//保存深度图像
void CBodyBasics::SaveDepthImg()
{
//string str = (num2str)depthnumber;
stringstream stream;
string str;
stream << depthnumber; //从long型数据输入
stream >> str; //转换为 string
imwrite(str + "depthnumber.bmp", depthImg);
cout << str + "depthnumber.bmp" << endl;
}//照相
void CBodyBasics::TakePhoto()
{
//定义人体一些骨骼点,方面表示
Joint righthand = joints[JointType_HandRight];
Joint lefthand = joints[JointType_HandLeft];
Joint spinemid = joints[JointType_SpineMid];
Joint head = joints[JointType_Head];
stringstream stream;
string str;
if (spinemid.Position.Z < 0.5) //判断人体重心离Kinect 的距离,小于0.5则直接返回,这使得数据已经不准确了,避免误操作
return;
//判断原则:右手的中心离身体重心在Z轴上的距离大于给定阈值(Z_THRESHOUD)且现在没在拍照,
//避免一直触发拍照,也可以设置等待时间,这样可以实现连拍
if (spinemid.Position.Z - righthand.Position.Z >= Z_THRESHOUD&&bTakePhoto)
{
bTakePhoto = false;
photocount++;
stream << photocount; //从long型数据输入
stream >> str; //转换为 string
string filepath = "D:/pic/"; //保存到指定文件夹里面
imwrite(filepath+str + ".jpg", copy);
cout << "成功照第" << photocount << "张相" << endl;
}
if (spinemid.Position.Z - righthand.Position.Z < Z_THRESHOUD) //没有检测到指定动作,则表示没有在拍照
{
bTakePhoto = TRUE;
return;
}
}//切换背景
bool CBodyBasics::ChangeBackground()
{
//定义人体一些骨骼点,方面表示
Joint righthand = joints[JointType_HandRight];
Joint head = joints[JointType_Head];
Joint spinebase = joints[JointType_SpineBase];
if (spinebase.Position.Z<0.5) //判断人体重心离Kinect 的距离,小于0.5则直接返回,这使得数据已经不准确了,避免误操作
return false;
//判断原则:右手的中心离身体重心在X轴上的距离大于给定阈值(X_THRESHOUD)且现在没在切换背景时,
//避免一直触发切换,也可以另一种方式,设置一个等待时间,这样可以实现快速切换多张背景。
if (righthand.Position.X - head.Position.X >= X_THRESHOUD&&bChange)
{
bChange = FALSE;
if (fscanf(fp, "%s ", imagepath) > 0) //读取背景图片的本地路径
backjpg = imread(imagepath); //读取背景图片
else
{
rewind(fp); //文件指针复位,即重新指向最开始位置
fscanf(fp, "%s ", imagepath); //读取背景图片的本地路径
backjpg = imread(imagepath); //读取背景图片
}
return true;
}
if (righthand.Position.X - head.Position.X < X_THRESHOUD) //没有检测到指定作,则表明没有在切换背景,
{
bChange = TRUE;
return false;
}
}
由于本段代码已经做了非常详细的注释,这里不再对代码内容详细分析,有什么问题欢迎留言讨论交流。
本篇文章详细讲解了利用kinect对人体进行抠图,人体和背景照片的合成,以及结合动作识别进行拍照的技术。完整代码下载地址:
https://download.csdn.net/download/baolinq/10406054
补充一些其他学习资料,在本系列第二章有讲到。
Kinect v2 for OpenNI 2:
https://github.com/mvm9289/openni2_kinect2_driver
https://github.com/occipital/OpenNI2/tree/kinect2
libfreenect 2
https://github.com/OpenKinect/libfreenect2
理论上,这个版本的驱动程式除了支持Windows以外,还可以支持Mac 和Ubtuntu等系统。如果想在非 Windows 环境下使用 Kinect v2 体感器,可以考虑此方案。
好了,本篇本章到此就结束了,欢迎底下留言和讨论。下一篇见~~~
超跑开起来欣赏养眼
