Python源码剖析-Dict
Python中的关联式容器是PyDictObject。Python通过PyDictObject建立执行Python字节码的运行环境,其中会存放变量名和变量值的元素对,通过查找变量名获得变量值。
PyDictObject运用了(hash table)散列表,最优情况下能达到O(1)复杂度的搜索效率。
散列表:

基本思想:键值映射整数,通过一片连续内存的索引对应相对的值
散列效率高,但是不同的对象运用散列函数有可能会产生相同的散列值、即是易冲突
相关概念:装载率(如果散列表一共可以容纳10个元素,而当前已经装入6个元素,那么装载率就是6/10),研究表明当散列表的装载率大于2/3时,散列冲突的发生概率大大增加
解决办法:开放定址法(通过一个二次探测函数f,计算下一个地址,如果可用则插入不可用则计算下一个候选位置)
缺点:删除时不能完成删除元素,否则会造成断链,解决的办法是:伪删除
entry/slot ->关联容器(键)
一个entry的定义如下:
typedef struct {
Py_ssize_t me_hash; //记录me_key 的散列值,避免每次都要计算
PyObject *me_key; //指向键
PyObject *me_value; //指向值
} PyDictEntry;
因为key和value 都是PyObject,故什么东西都可以放进去Dict
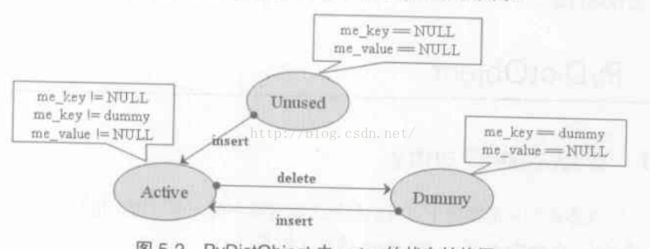
entry有三种状态:
①Unused态 →key,value = Null
②Active 态 → key!= dummy,key!=Null,value != Null
③Dummy 态 → key = Dummy, value = Null
三态的转换关系如下:
在PyDictObject定义中,
 有一个ma_smalltable(PyDict_MINSIZE) 意味着至少有X个entry被创建(在这里X=8, 可在源码修改)
有一个ma_smalltable(PyDict_MINSIZE) 意味着至少有X个entry被创建(在这里X=8, 可在源码修改)
定义是分两种情况:①元素数目小于8, ma_table 指向 ma_smalltable
②元素数目大于8, ma_table指向额外内存
第一次调用PyNew的时候会创建Dummy对象,Dummy则指向一个PyStringObject对象
元素的搜索:lookdict、lookdict_string-(算法相同) 后者是为键值为String提供便利 因为在python中一PyStringObject对象作为PyDictObject的键是十分常见的,故lookdict_string成为了PyDictObject中默认的搜索算法
dict的key匹配值有两层含义:
①引用相同,即两符号指向同一地址
②值相同,两个对象指向不同的地址,但是值相同
e.g.:Python大整数是不共享内存的,如下例子:
d = {}
d[9527] = 'Python'
print(d[9527])
//上面两个9527指向不同的地址,但值相同
接下来看看第一次搜索:
[1]根据hash获得entry的索引,这里是第一个索引
[2]if entry处于Unused态,即字典中无这个key,第一个索引失败 if entry->me_key == key,表明匹配,搜索成功
[3]if entry 处于Dummy态,设置freeslot(最后如果找不到是会返回freeslot,提示系统这里有一个dummy,快来用掉它)
[4]if entry 处于active ,检查是否值相同,若相同则搜索成功
所第一个entry不匹配,则沿着探测链,顺藤摸瓜,依次比较探测链上的entry与带查找的key
①若搜索成功,则ep一定指向一个有效的entry
②若搜索不成功,此时ep肯定处于一个Unused态的entry
不能直接返回,因为有可能在搜索链的过程中发现dummy,故须返回给Python使用
lookdict_string(有条件限制)(优化)
key是PyDictObject
if(!PyString_checkEcact(key)){
mp->ma_lookup = lookdict;
return lookdict(mp_key, hash);
}lookdict_string 效率比lookdict高
元素插入:
ep = mp->ma_lookup(mp, key, hash);
成功:
if (ep->me_value != Null){
old_value = ep->me_value;
ep->me_value = new_value;
Py_DECREF(old_value);
Py_DECREF(key);
}
在插入元素的动作结束后,会检查是否需要改变PyDictObject内部ma_table的内存大小
条件:当增加元素个数且装载率大于2/3时
改变内存大小由dictresize执行
[1]确定新的table大小,这个大小要大于传入的数值,从8开始乘以2的指数倍(2的n此方),直到超过传入的数值
[2]==8,不需要重新分配内存,直接指向ma_smalltable
[3]>=8,重新分配内存
[5]对非Unused做处理,若为active则插入,若为dummy则丢弃,也就是重新做字典,类似一个新字典里面是没有dummy的
[6]如果旧的table指向内存(>8)则释放
删除:与插入很像,先计算hash值,找到相对应的entry,删除维护的元素,将active转为dummy,调整table使用情况(ma_used--1)
字典结束