浅析GPU计算——cuda编程
在《浅析GPU计算——CPU和GPU的选择》一文中,我们分析了在遇到什么瓶颈时需要考虑使用GPU去进行计算。本文将结合cuda编程来讲解实际应用例子。(转载请指明出于breaksoftware的csdn博客)
之前我们讲解过,CPU是整个计算机的核心,它的主要工作是负责调度各种资源,包括其自身的计算资源以及GPU的计算计算资源。比如一个浮点数相乘逻辑,理论上我们可以让其在CPU上执行,也可以在GPU上执行。那这段逻辑到底是在哪个器件上执行的呢?cuda将决定权交给了程序员,我们可以在函数前增加修饰词来指定。
| 关键字 | 执行位置 |
| __host__ | CPU |
| __global__ | GPU |
| __device__ | GPU |
一般来说,我们只需要2个修饰词就够了,但是cuda却提供了3个——2个执行位置为GPU。这儿要引入一个“调用位置”的概念。父函数调用子函数时,父函数可能运行于CPU或者GPU,相应的子函数也可能运行于CPU或者GPU,但是这绝不是一个2*2的组合关系。因为GPU作为CPU的计算组件,不可以调度CPU去做事,所以不存在父函数运行于GPU,而子函数运行于CPU的情况。
| 关键字 | 调用位置 |
| __host__ | CPU |
| __global__ | CPU |
| __device__ | GPU |
__global__描述的函数就是“被CPU调用,在GPU上运行的代码”,同时它也打通了__host__和__device__修饰的函数。
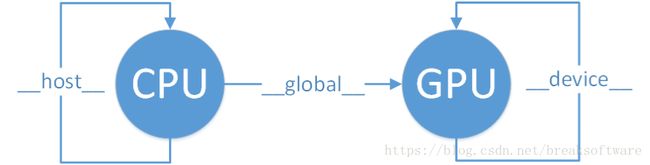
如果一段代码既需要运行于CPU,也要运行于GPU,怎么办?难道要写两次?当然不用,我们可以同时使用__host__和__device__修饰。这样编译器就会帮我们生成两份代码逻辑。
#include "cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
__host__ __device__ int run_on_cpu_or_gpu() {
return 1;
}
__global__ void run_on_gpu() {
printf("run_on_cpu_or_gpu GPU: %d\n", run_on_cpu_or_gpu());
}
int main() {
printf("run_on_cpu_or_gpu CPU: %d\n", run_on_cpu_or_gpu());
run_on_gpu<<<1, 1>>>();
return 0;
} 上例中,第11行调用的是run_on_cpu_or_gpu的GPU实现,而第15行的调用的是的CPU实现。

可以看到,为了实现上面的例子,我引入了一个__global__函数——run_on_gpu用于衔接CPU和GPU,那么有人可能会问:如果__global__和__host__、__device__一起修饰函数不就行了?实际上cuda禁止了这种方案,而且__global__不能和它们中任何一个修饰符一起使用。
__global__这个修饰符的使命使得它足够的特殊。比如它修饰的函数是异步执行的。我们稍微修改一下上面main函数
int main() {
printf("run_on_cpu_or_gpu CPU: %d\n", run_on_cpu_or_gpu());
run_on_gpu<<<1, 1>>>();
printf("will end\n");
return 0;
}如果上述代码都是同步执行的,那么will end将是最后一条输出,然而输出却是
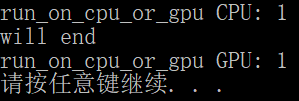
可见__global__修饰的函数是被异步执行的。
__global__修饰的函数只能是void类型。我们假设其可以有返回值,则其调用者是可以捕获这个值的。但是__global__函数是异步调用的,当函数返回时,接受返回值的变量可能已经被销毁了。所以设计其有返回值也没太多意义。
int main() {
printf("run_on_cpu_or_gpu CPU: %d\n", run_on_cpu_or_gpu());
{
int ret = run_on_gpu<<<1, 1>>>(); // error!!!even if run_on_gpu return int!!
}
printf("will end\n");
return 0;
}还有人会问,上面main函数怎么没有用修饰符修饰?cuda编程规定如果没有使用修饰符修饰的默认就是__host__类型。这种设计让大家熟悉的规则成为默认的规则,可以让更多第三方代码不用修改就直接被cuda编译器编译使用。
cuda是一个GPU编程环境,所以它对__device__修饰的函数进行了比较多的优化。比如它会根据它的规则,让某个__device__修饰函数成为内联函数(inline)。这些规则是程序员不可控,但是如果我们的确对是否内联有需求,cuda也提供了方式:使用__noinline__修饰函数不进行内联优化;使用 __forceinline__修饰函数强制进行内联优化。当然这两种修饰符不能同时使用。
也许你已经发现,__global__函数调用方式非常特别——使用“<<<>>>”标志。这儿就需要引入cuda的并行执行的线程模型来解释了。在同一时刻,一个cuda核只能运行一个线程,而线程作为逻辑的运行载体有其自己的ID。这个ID和我们在linux或windows系统上CPU相关的线程ID有着不同的表达方式。比如在Linux系统上可以使用gettid方法获取一个pid_t值,比如3075。但是cuda的表达方式是一个三维空间,表达这个空间的是一个叫block的概念。比如单个block定义其有(Dx, Dy, 0)个线程,则每个线程ID为x+yDx;再比如有(Dx, Dy, Dz)个线程,则每个线程ID为x+yDx+zDxDy。
__global__ void run_on_gpu() {
printf("GPU thread info X:%d Y:%d Z:%d\t block info X:%d Y:%d Z:%d\n",
threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z);
}
int main() {
dim3 threadsPerBlock(2, 3, 4);
int blocksPerGrid = 1;
run_on_gpu<<>>();
return 0;
} 其运行结果如下
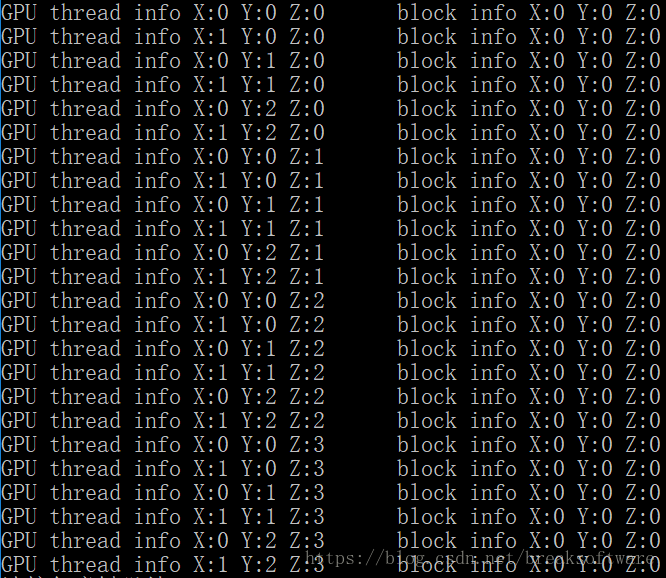
承载block的是一个叫做grid的概念。block在grid中的位置也是通过一个三维结构来表达,比如下面代码标识的是一个一个Grid包含(3,3,3)结构的Block,一个Block包含(3,3,3)结构的Thread
dim3 blocksPerGrid(3, 3, 3);
dim3 threadsPerBlock(3, 3, 3);
run_on_gpu<<>>(); 
对于上例中的各个线程的ID算法就更加复杂了,详细的计算规则可以见《CUDA(10)之深入理解threadIdx》。
为什么cuda的线程要设计的这么复杂?我想其可能和GPU设计的初始目的有关——图像运算。而我们肉眼的感官就是三维的,所以GPU有大量三维计算的需求。
个人觉得大家不要拘泥于threadID的计算,而要学会如何利用blockIdx、threadIdx的三维坐标来进行并行计算。比如我们把问题的维度降低,看看一个Grid只有一个Block,一个Block中N*N个线程,计算两个N*N矩阵相加的例子
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<>>(A, B, C);
...
} 矩阵相加是一个非常好说明GPU并行计算的例子。结合上面的代码,我们假设GPU中有大于N*N个空闲的cuda核,且假设调度器同时让这N*N个线程运行,则整个计算的周期可以认为是一个元的计算周期。而CPU却要串行处理每个元的计算(不考虑CPU中向量计算单元)。
那矩阵相加的什么特性让其成为一个经典的案例呢?那就是“可并行性”!因为每个元的计算都不依赖于其他元的计算结果,所以这种计算是适合并行进行的。如果一个逻辑的“可并行计算单元”越多越连续,其就越适合使用GPU并行计算来优化性能。
可能有人提出一个疑问:假如N非常大,比如是128,那么就需要100*100=10000个线程来执行。而目前最高配的GPU只有5120个cuda核,那这些线程是如何在cuda核上调度的呢?这儿要引入一个叫做warp的概念,它是一个线程集合。假如GPU的warp包含32个线程,则我们的任务被打包成10000/32 =313个warp(除不尽。其中312个warp包含32个我们的计算线程,而剩下的16将和16个空线程被打包成一个warp)。这313个warp分批次在GPU上调度执行,这样设计有几个好处:可以成批有序的执行线程逻辑,且发生等待操作时,可以切换其他warp去工作,从而提供cuda核心的利用率。
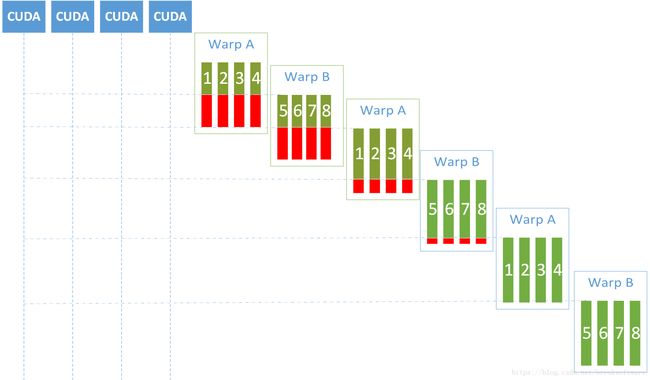
我们再看下计算的数据源。一般情况下,数据源是由CPU发射到GPU上去的,于是连接GPU和主板的PCIe接口带宽至关重要。目前设计中的PCIe5的理论最大带宽可以达到64GB/s(https://zh.wikipedia.org/wiki/PCI_Express),而CPU和内存之间的访问带宽也不到100GB/s。通过这两者比较,我们发现内存和PCIe之间,明显PCIe带宽是瓶颈。那这个瓶颈重要么?我们再看下目前NV的显存带宽是多少——超过700GB/s。可以说PCIe和显存带宽差一个数量级。下图可以让我们更直观的看到问题
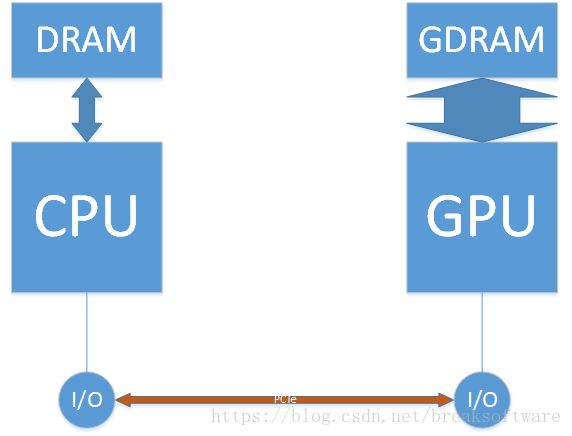
如果我们把数据从DRAM一次性保存到GDRAM,然后GPU直接访问GDRAM上的数据,这和频繁通过PCIe读写数据相比,无疑大幅提高了效率。等到数据都处理完毕,我们再将GDRAM的数据发送回CPU。cuda为我们提供了cudaMemcpy系列方法,让我们可以在DRAM和GDRAM之间传递数据。我们把上面矩阵相加的例子加以改造
// Device code
__global__ void VecAdd(float* A, float* B, float* C, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
// Host code
int main() {
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float* d_A; cudaMalloc(&d_A, size);
float* d_B; cudaMalloc(&d_B, size);
float* d_C; cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<>>(d_A, d_B, d_C, N);
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
} 通过这两章的浅析,我们可以大致了解GPU并行计算的相关概念,以及使用cuda实现并行计算的基本操作。如果大家还想有更加深入的了解,可以参见《cuda c programming guide》。还可以参考周斌老师《NVIDIA CUDA初级教程视频》。