神奇的G1——Java全新垃圾回收机制
G1全称是Garbage First Garbage Collector,使用G1的目的是简化性能优化的复杂性。例如,G1的主要输入参数是初始化和最大Java堆大小、最大GC中断时间。
G1 GC由Young Generation和Old Generation组成。G1将Java堆空间分割成了若干个Region,即年轻代/老年代是一系列Region的集合,这就意味着在分配空间时不需要一个连续的内存区间,即不需要在JVM启动时决定哪些Region属于老年代,哪些属于年轻代。因为随着时间推移,年轻代Region被回收后,又会变为可用状态(后面会说到的Unused Region或Available Region)了。
G1年轻代收集器是并行Stop-the-world收集器,和其他的HotSpot GC一样,当一个年轻代GC发生时,整个年轻代被回收。G1的老年代收集器有所不同,它在老年代不需要整个老年代回收,只有一部分Region被调用。
G1 GC的年轻代由Eden Region和Survivor Region组成。当一个JVM分配Eden Region失败后就触发一个年轻代回收,这意味着Eden区间满了。然后GC开始释放空间,第一个年轻代收集器会移动所有的存储对象从Eden Region到Survivor Region,这就是“Copy to Survivor”过程。
清单1所示是年轻代的回收GC输出日志,在这个日志里面,请见最后一行,年轻代新的大小是224(New Eden)+32(New Survivor)=256MB
清单1 G1回收年轻代
15.910: [GC pause (young), 0.0260410 secs]
[Parallel Time: 18.0 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 15909.7, Avg: 15909.7, Max: 15909.7, Diff: 0.0]
[Ext Root Scanning (ms): Min: 5.6, Avg: 6.1, Max: 6.8, Diff: 1.2, Sum: 24.3]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Processed Buffers: Min: 0, Avg: 12.5, Max: 24, Diff: 24, Sum: 50]
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
[Object Copy (ms): Min: 11.1, Avg: 11.8, Max: 12.2, Diff: 1.1, Sum: 47.1]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 18.0, Avg: 18.0, Max: 18.0, Diff: 0.0, Sum: 72.0]
[GC Worker End (ms): Min: 15927.7, Avg: 15927.7, Max: 15927.7, Diff: 0.0]
[Code Root Fixup: 0.1 ms]
[Code Root Migration: 0.2 ms]
[Clear CT: 0.1 ms]
[Other: 7.6 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 7.1 ms]
[Ref Enq: 0.1 ms]
[Free CSet: 0.2 ms]
[Eden: 256.0M(256.0M)->0.0B(224.0M) Survivors: 0.0B->32.0M Heap: 256.0M(1024.0M)->35.1M(1024.0M)]
[Times: user=0.06 sys=0.02, real=0.02 secs]
当一个Java堆空间瓶颈点超过后,即堆空间耗尽,这时G1初始化老年代收集器,这个Initial-Mark阶段是一个并行Stop-the-World的,它的大小和老年代以及整个Java堆大小有关。
Initial-Mark阶段和下一个Young GC一起执行,一旦Initial-Mark完成,一个多线程并行的Marking阶段开始去标记老年代所有存活的对象。当并行Marking阶段完成,一个并行的Stop-the-World的阶段开始去标记所有的对象(由于和Marking阶段并行存在,应用程序多线程程序可能会丢失数据)。Remark节点结束后,G1有老年代所有Region的完整的标记信息,如果这时老年代没有任务存活对象,那么下一个阶段Cleanup阶段就不需要额外的GC工作了。
上面的描述是关于老年代收集器的流程描述,简要说明就是Initial-Mark-> Concurrent Root Region scanning->Concurrent Marking-> Remarking->Cleanup。
在Cleanup阶段,如果G1 GC发现一个可回收的Region,不用等到下一个GC停顿可以直接回收这些Region并且加入到空闲Region的LinkedList链表。
CMS、Parallel、Serial GC都需要通过Full GC去压缩老年代并在这个过程中扫描整个老年代。
因为G1的操作以Region为基础,因此它适用于大Java堆。即便Java堆很大,大量的GC工作可以被限制在小型Region集合里面。G1允许用户指定停顿时间目标,G1通过自适应的堆大小来满足这个目标。
G1 GC深度原理
G1把整个Java堆划分为若干个区间(Regions)。每个Region大小为2的倍数,范围在1MB-32MB之间,可能为1,2,4,8,16,32MB。所有的Region有一样的大小,JVM生命周期内不会改变。例如-Xmx16g –Xms16g,设置16GB的堆大小,2000个Regions,则每个Region=16GB/2000=8MB。如果堆大小很大,而每个Region的大小很小,则Region数量可能会超过2000个。同样地,很小的堆大小会导致Region数量很少。
Region类型
G1对于Region的几个定义:
Available Region=可用的空闲Region
Eden Region = 年轻代Eden空间
Suivivor Region=年轻代Survivor空间
所有Eden和Survivor的集合=整个年轻代
Humongous Region=大对象Region
Humongous Region
大对象是指占用大小超过一个Region50%空间的对象,这个大小包含了Java对象头。对象头大小在32位和64位HotSpot VM之间有差异,可以使用Java Object Layout工具确定头大小,简称JOL。
当大对象开始进入排队时,G1会调动几个连续的有效Region存放它。第一个Region叫做“大对象开始”Region,其他Regions叫“大对象延续”Regions。如果没有连续的可用Regions,G1会做一个Java heap的full gc去压缩对象。大对象区间属于老年代的一部分,它只包含一个对象,这个属性允许G1收集一个大对象区间当并行Marking阶段发现没有对象存活时。当这个条件触发,所有包含大对象的区间都可以立即被回收申明。
对于G1来说,一个潜在的挑战是短生命周期的大对象可能不会被申明直到它们变成没有被引用。JDK8U45申明了一个方法在年轻代回收大对象Region。
前面说过,G1 Region包括Young Region、Old Region、Humougous Region、Free Region。每个收集器单元跨越一个年轻和老年Regions。一个大对象跨越两个收集器单元,所以大对象Region是一个连续的Region,如图1所示。
图1 Region跨越分布图1
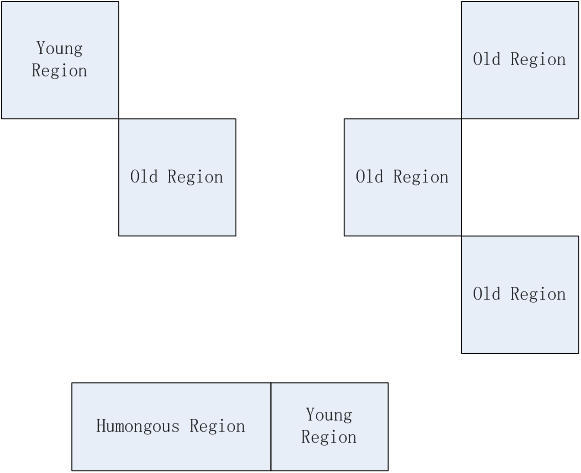
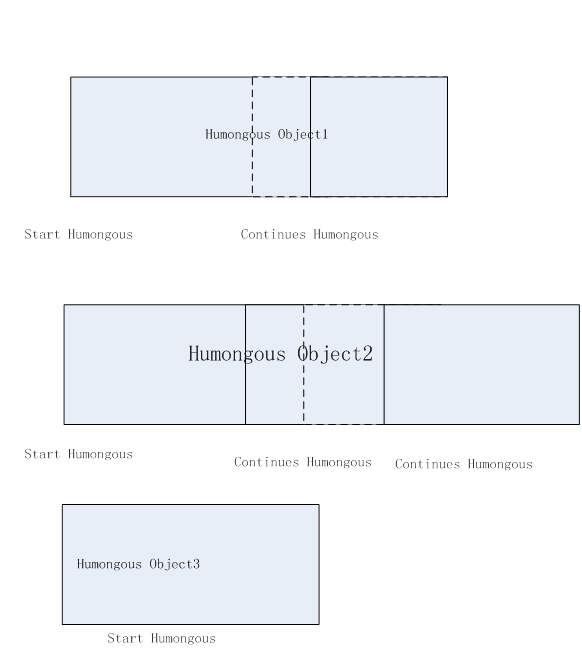
接下来连续的Region叫做Continues Humongous。大对象2跨越三个连续的堆Regions,大对象3跨越了一个Region。
图2 Region跨越分布图2
RSet
基于老年代的收集器采用Heap里不同区域区分/隔离对象,这些不同的区域里面的对象对应了不同年代。这样年代收集器可以集中精力在最近分配的对象上,因为它们会发现一些对象不久会死亡。这些年代在堆里可以被分别收集,这样不用扫描整个Heap,可以节省时间和减小响应时间,并且存活时间长的对象不用来回复制,减少了拷贝和引用更新开销。
为了方便收集器的独立性,许多GC维持了每个年代的RSet。每一个RSet是一个数据结构,它维护并跟踪收集器单元的内部引用,如G1 GC的Region一样,减少了扫描整个Heap堆获取信息的耗时。当G1 GC执行了一个Stop-the-world收集(年轻代或混合代),它可以通过CSet扫描Region的RSets。一旦存活对象被移除,它们的引用立即被更新。
图3 RSet布局图示例
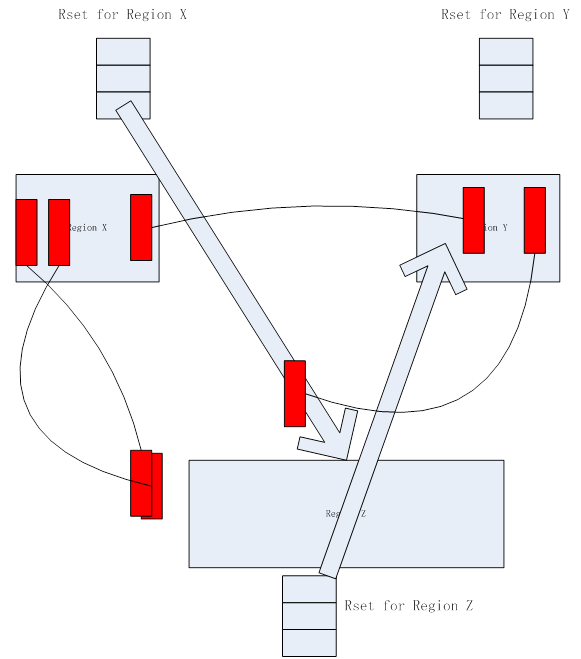
从上面的图3,我们可以看见一个年轻代Region(Region X)和两个老年代Region(Region Y和Region Z)。Region X有一个从Region Z来的引用。这个引用被标记在了Region X的RSet里面。我们也观察到Region Z有两个引用,一个来自于Region X,另一个来自于Region Y。Region Z的RSet需要标记从Region Y过来的引用,但是不需要去记住从Region X来的引用,因为年轻代是全局被收集的。对于Region Y,最终我们可以看到从Region X来的引用,并没有在Region Y的RSet里记录引用。
Mixed GC事件
随着很多对象被提升到老年代,以及大对象进入大对象区间,整个Java堆区占有率上升。为了避免Java堆空间溢出,JVM进程需要去初始化一个GC(不仅包含年轻代Regions,也包含增加老年代Region到混合收集器)。在混合GC事件里,所有的年轻代Regions会被收集,同时一部分老年代Region也会被收集。
清单2 G1老年代回收
120.298: [GC pause (mixed), 0.0221810 secs]
[Parallel Time: 17.1 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 120298.2, Avg: 120298.2, Max: 120298.2, Diff: 0.1]
[Ext Root Scanning (ms): Min: 5.6, Avg: 5.8, Max: 5.8, Diff: 0.2, Sum: 23.1]
[Update RS (ms): Min: 0.7, Avg: 0.9, Max: 1.0, Diff: 0.3, Sum: 3.5]
[Processed Buffers: Min: 4, Avg: 10.5, Max: 23, Diff: 19, Sum: 42]
[Scan RS (ms): Min: 1.1, Avg: 1.1, Max: 1.2, Diff: 0.1, Sum: 4.5]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 9.0, Avg: 9.2, Max: 9.5, Diff: 0.4, Sum: 36.8]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 16.9, Avg: 17.0, Max: 17.0, Diff: 0.1, Sum: 68.0]
[GC Worker End (ms): Min: 120315.2, Avg: 120315.2, Max: 120315.2, Diff: 0.0]
[Code Root Fixup: 0.1 ms]
[Code Root Migration: 0.1 ms]
[Clear CT: 0.1 ms]
[Other: 4.7 ms]
[Choose CSet: 0.1 ms]
[Ref Proc: 4.1 ms]
[Ref Enq: 0.0 ms]
[Free CSet: 0.3 ms]
[Eden: 224.0M(224.0M)->0.0B(224.0M) Survivors: 32.0M->32.0M Heap: 547.5M(1024.0M)->297.3M(1024.0M)]
[Times: user=0.08 sys=0.00, real=0.02 secs]
Full Garbage Collections
G1内部,前面提到的混合GC是非常重要的释放内存机制,它避免了G1出现Region没有可用的情况,否则就会触发Full GC事件。
CMS、Parallel、Serial GC都需要通过Full GC去压缩老年代并在这个过程中扫描整个老年代。G1的Full GC算法和Serial GC收集器完全一致。当一个Full GC发生时,整个Java堆执行一个完整的压缩,这样确保了最大的空余内存可用。G1的Full GC是一个单线程,它可能引起一个长时间的停顿时间,G1的设计目标是减少Full GC,满足应用性能目标。
G1 GC常用参数
我在这里所罗列的参数的默认值都是基于JDK8u45,所以可能后续的JDK版本会有些值不一样,这个读者可以直接通过JDK的官方帮助文档获取最新默认值信息。
-XX:+UseG1GC:启用G1 GC。JDK7和JDK8要求必须显示申请启动G1 GC,JDK可能会设置G1 GC为默认GC选项,也有可能会退到早期的Parallel GC,这个也请关注吧,JDK9预计2017年正式发布;
-XX:G1NewSizePercent:初始年轻代占整个Java Heap的大小,默认值为5%;
-XX:G1MaxNewSizePercent:最大年轻代占整个Java Heap的大小,默认值为60%;
-XX:G1HeapRegionSize:设置每个Region的大小,单位MB,需要为1,2,4,8,16,32其一,默认是堆内存的1/2000。前面我们讲过大对象概念,如果这个值设置比较大,那么大对象就可以进入Region了,同样地,这样做的坏处是直接干预了各年龄代的分配大小;
-XX:ConcGCThreads:与Java应用一起执行的GC线程数量。默认是Java线程的1/4。减少这个参数的数值可能会提升并行回收的效率,即提高系统内部吞吐量(系统是一个整体,CPU资源大家都需要占用),不过如果这个数值过低,也会导致并行回收机制耗时加长;
-XX:+InitiatingHeapOccupancyPercent(简称IHOP):G1内部并行循环启动的设置值,默认为Java Heap的45%。这个可以理解为老年代空间占用的空间,GC收集后需要低于45%的占用率。这个值主要是为了决定在什么时间启动老年代的并行回收循环,这个循环从初始化并行回收开始,可以避免Full GC的发生;
-XX:G1HeapWastePercent:G1不会回收的内存大小,默认是堆大小的5%。GC会收集所有的Region,如果值达到5%,就会停下来不再收集了; -XX:G1MixedGCCountTarget:设置并行循环之后需要有多少个混合GC启动,默认值是8个。老年代Regions的回收时间通常比年轻代的收集时间要长一些,所以如果混合收集器比较多,可以允许G1延长老年代的收集时间;
-XX:+G1PrintRegionLivenessInfo:这个参数需要和-XX:+UnlockDiagnosticVMOptions配合启动,这可以理解,它们本身就是属于VM的调试信息。如果开启了,VM会打印堆内存里每个Region的存活对象信息。这个信息在标记循环结束后可以打印出来;
-XX:G1ReservePercent:这个值是为了保留一些空间用于年代之间的提升,默认值是堆空间的10%。注意这个空间保留后就不会用在年轻代了,大家可以看到GC日志里输出显示,我们大量执行的是年轻代回收,所以如果你的应用里面有比较大的堆内存空间、比较多的大对象存活,那还是减少一点保留空间吧,这样会给年轻代更多的预留空间、GC之间更长的处理时间;
-XX:+G1SummarizeRSetStats:这个也是一个VM的调试信息。如果启用,会在VM推出的时候打印出RSets的详细总结信息。如果启用-XX:G1SummaryRSetStatsPeriod参数,就会阶段性地打印RSets信息;
-XX:+G1TraceConcRefinement:这个也是一个VM的调试信息。如果启用,并行回收阶段的日志就会被详细打印出来;
-XX:+GCTimeRatio:大家知道,GC的有些阶段是需要Stop-the-World,即停止应用线程的,这个参数就是计算花在Java应用线程上和花在GC线程上的时间比率,默认是9。这个参数主要的目的是让用户可以控制花在应用上的时间,G1的计算公式是100/(1+GCTimeRatio),这样如果采用9,则最多10%的时间会花在GC工作上面。Parallel GC的默认值是99,表示1%的时间被用在GC上面,这是因为Parallel GC贯穿整个GC,而G1则根据Region来进行划分,不需要全局性扫描Java Heap;
-XX:+UseStringDeduplication:手动开启Java String对象的分割工作,这个是JDK8u20之后新增的参数,主要用于相同String避免重复申请内存,节约Region的使用;
-XX:MaxGCPauseMills:G1停止执行的一个目标值,单位是毫秒,默认是200毫秒,这个值不一定真的会达到。这个参数会通过控制年轻代的大小来实现目标。
结束语
我们知道垃圾回收机制一直是Java着力加强点,G1 GC通过引入许多不同的方式解决了Parallel、Serial、CMS GC的许多缺点。G1通过将Heap划分为多个Region,可以让G1操作可以在一个Region里面执行而不是整个Java堆或者整个年代(Generation)。本文作者一直的观点是Practice by self,几乎所有的应用程序都有自身的独特性,所以不能给出千篇一律的GC配置单,需要的是读者自己的反复试验、比对结果、确定方案。
相关图书 
《大话Java性能优化》
周明耀 著
ISBN 978-7-121-28481-6
2016年4月出版
定价:89.00元
564页
1、系统介绍系统调优的解决思路和技术实现
2、结合大家最为熟知的12306、电商等案例
3、架构、设计、开发、算法等多层次多角度思路和策略
4、涉及内存、IO等各种问题,提供丰富的经验参考
5、语言通俗易懂,引人入胜
