协同过滤的ALS算法
原文地址:http://blog.csdn.net/antkillerfarm/article/details/53734658
ALS算法原理
http://www.cnblogs.com/luchen927/archive/2012/02/01/2325360.html
上面的网页概括了ALS算法出现之前的协同过滤算法的概况。
ALS算法是2008年以来,用的比较多的协同过滤算法。它已经集成到Spark的Mllib库中,使用起来比较方便。
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
用户和商品的关系,可以抽象为如下的三元组:
假设我们有一批用户数据,其中包含m个User和n个Item,则我们定义Rating矩阵 Rm×n ,其中的元素 rui 表示第u个User对第i个Item的评分。
在实际使用中,由于n和m的数量都十分巨大,因此R矩阵的规模很容易就会突破1亿项。这时候,传统的矩阵分解方法对于这么大的数据量已经是很难处理了。
另一方面,一个用户也不可能给所有商品评分,因此,R矩阵注定是个稀疏矩阵。矩阵中所缺失的评分,又叫做missing item。
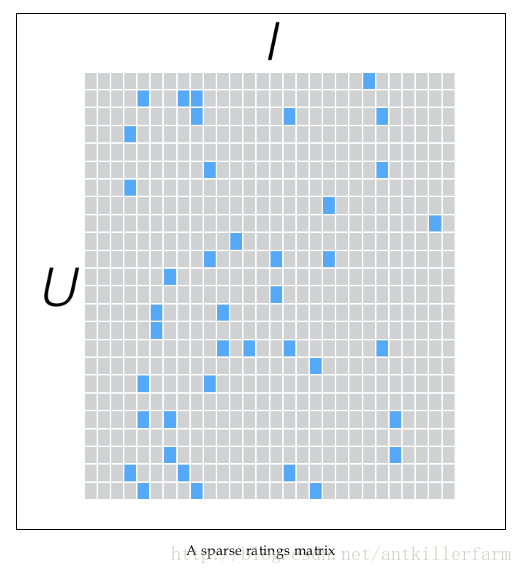
针对这样的特点,我们可以假设用户和商品之间存在若干关联维度(比如用户年龄、性别、受教育程度和商品的外观、价格等),我们只需要将R矩阵投射到这些维度上即可。这个投射的数学表示是:
这里的 ≈ 表明这个投射只是一个近似的空间变换。
不懂这个空间变换的同学,可参见《机器学习(十二)》中的“奇异值分解”的内容,或是本节中的“主成分分析”的内容。
一般情况下,k的值远小于n和m的值,从而达到了数据降维的目的。
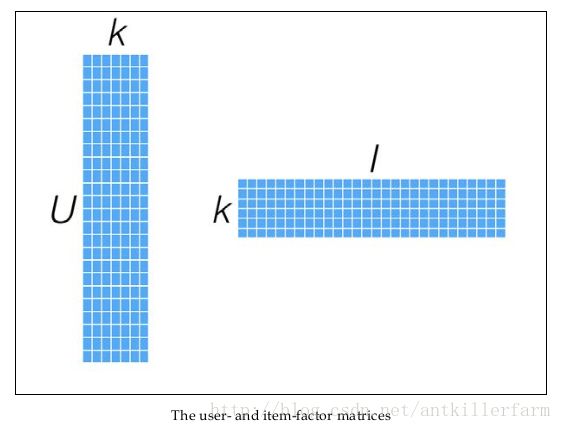
幸运的是,我们并不需要显式的定义这些关联维度,而只需要假定它们存在即可,因此这里的关联维度又被称为Latent factor。k的典型取值一般是20~200。
这种方法被称为概率矩阵分解算法(probabilistic matrix factorization,PMF)。ALS算法是PMF在数值计算方面的应用。
为了使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数:
考虑到矩阵的稳定性问题,使用Tikhonov regularization,则上式变为:
优化上式,得到训练结果矩阵 Xm×k,Yn×k 。预测时,将User和Item代入 rui=xTuyi ,即可得到相应的评分预测值。

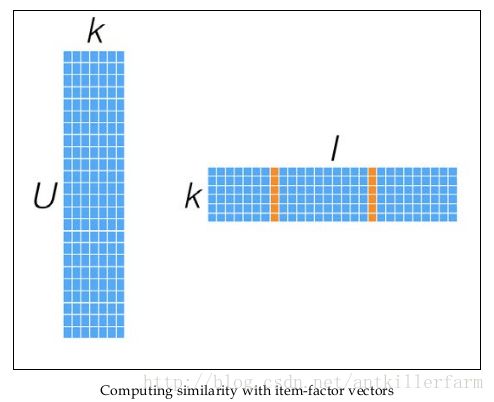
同时,矩阵X和Y,还可以用于比较不同的User(或Item)之间的相似度,如下图所示:
ALS算法的缺点在于:
1.它是一个离线算法。
2.无法准确评估新加入的用户或商品。这个问题也被称为Cold Start问题。
ALS算法优化过程的推导
公式2的直接优化是很困难的,因为X和Y的二元导数并不容易计算,这时可以使用类似坐标下降法的算法,固定其他维度,而只优化其中一个维度。
对 xu 求导,可得:
令导数为0,可得:
同理,对 yi 求导,由于X和Y是对称的,因此可得类似的结论:
因此整个优化迭代的过程为:
1.随机生成X、Y。(相当于对迭代算法给出一个初始解。)
Repeat until convergence {
2.固定Y,使用公式3更新 xu 。
3.固定X,使用公式4更新 yi 。
}
一般使用RMSE(root-mean-square error)评估误差是否收敛,具体到这里就是:
其中,N为三元组
算法复杂度:
1.求 xu : O(k2N+k3m)
2.求 yi : O(k2N+k3n)
可以看出当k一定的时候,这个算法的复杂度是线性的。
因为这个迭代过程,交替优化X和Y,因此又被称作交替最小二乘算法(Alternating Least Squares,ALS)。
隐式反馈
用户给商品评分是个非常简单粗暴的用户行为。在实际的电商网站中,还有大量的用户行为,同样能够间接反映用户的喜好,比如用户的购买记录、搜索关键字,甚至是鼠标的移动。我们将这些间接用户行为称之为隐式反馈(implicit feedback),以区别于评分这样的显式反馈(explicit feedback)。
隐式反馈有以下几个特点:
1.没有负面反馈(negative feedback)。用户一般会直接忽略不喜欢的商品,而不是给予负面评价。
2.隐式反馈包含大量噪声。比如,电视机在某一时间播放某一节目,然而用户已经睡着了,或者忘了换台。
3.显式反馈表现的是用户的喜好(preference),而隐式反馈表现的是用户的信任(confidence)。比如用户最喜欢的一般是电影,但观看时间最长的却是连续剧。大米购买的比较频繁,量也大,但未必是用户最想吃的食物。
4.隐式反馈非常难以量化。
ALS-WR
针对隐式反馈,有ALS-WR算法(ALS with Weighted- λ -Regularization)。
首先将用户反馈分类:
但是喜好是有程度差异的,因此需要定义程度系数:
这里的 rui 表示原始量化值,比如观看电影的时间;
这个公式里的1表示最低信任度, α 表示根据用户行为所增加的信任度。
最终,损失函数变为:
除此之外,我们还可以使用指数函数来定义 cui :
ALS-WR没有考虑到时序行为的影响,时序行为相关的内容,可参见:
http://www.jos.org.cn/1000-9825/4478.htm
参考
参考论文:
《Large-scale Parallel Collaborative Filtering forthe Netflix Prize》
《Collaborative Filtering for Implicit Feedback Datasets》
《Matrix Factorization Techniques for Recommender Systems》
其他参考:
http://www.jos.org.cn/html/2014/9/4648.htm
http://www.fuqingchuan.com/2015/03/812.html
http://www.docin.com/p-714582034.html
http://www.tuicool.com/articles/fANvieZ
http://www.68idc.cn/help/buildlang/ask/20150727462819.html