java复习-高频技术及应用场景
文章目录
- 0 前言
- 1 语言特性
- 1.1 封装
- 1.1.1 对象创建
- 1.1.2 对象内存分配和引用
- 1.2 继承
- 1.3.1 重载和重写
- 1.3 多态
- 1.4 抽象
- 2 集合
- 2.1 Array
- 2.2 List
- 2.3 Map
- 2.4 Set
- 3 错误规避和处理
- 3.1 异常
- 3.2 错误规避
- 4 jvm
- 4.1 结构
- 4.2 运行流程
- 5 文件IO
- 5.1 字节流
- 5.2 字符流
- 5.3 高频应用场景
- 6 网络
- 6.1 网络IO流
- 6.1.1 字节流
- 6.1.2 字符流
- 6.1.3 对象流
- 6.2.3.1 对象序列化
- 6.2 应用协议
- 6.2.1 http
- 6.3 接口
- 6.3.1 接口权限
- 6.3.2 访问限制
- 6.3.3 接口加密
- 7 消息
- 7.1 事件
- 7.2 线程
0 前言
鄙人对java语言,实话说,不是很感冒。比如解决一个问题,笔者的行为流程一般是这样的:
有了这个,你再跟我说什么封装,继承,多态,这显然一下子限制妨碍了笔者的想象力。另一方面,这几年做开发,有些方面囫囵吞枣,有些方面理解不透彻。温故而知新,因此,本人按照正常做事的思维,去复习回顾下之前用的高频java技术。
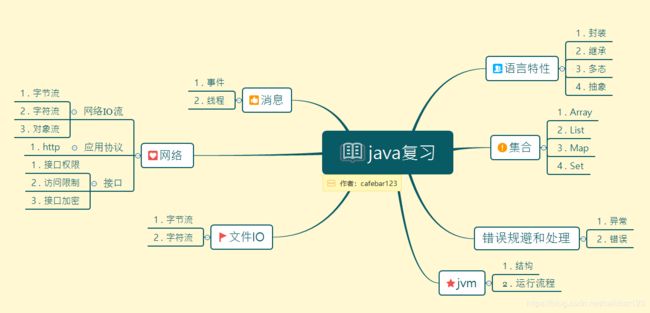
总体的复习结构如图:
1 语言特性
1.1 封装
封装可以用隐藏,模块化,组件化来理解。虽然A同事写了一大堆代码,但是我不想知道代码的细节,我只想知道怎么调用这段代码。
1.1.1 对象创建
一个对象的创建,必须经历声明->创建->初始化 3个步骤。
1.1.2 对象内存分配和引用
对象的创建,同时在内存中给予其分配一块内存,使用索引可访问该内存的地址。在java的语言设计中,为了内存的高效使用,在内存分配上,会使用“引用“的概念。这个概念类似C语言的指针。
比如,在对象clone上,深clone,会clone该对象引用指向的所有对象。
1.2 继承
继承有点类似于”沿用“一词,你做了什么,我沿用你的套路;如果我的情况不一样,我可以做些部分更改。在归纳”对象集合“的时候,比如归纳狗的时候,需要梳理狗的种类,皮毛颜色,三围,原产地,先总结一些公共特征,然后子类沿用公共特征,这样可以简化描述对象的难度。
1.3.1 重载和重写
1.3 多态
”多态“这个词字面上不好理解。它实际描述的是”行为“,即”Action“,或者”DO-WHAT“。
表述就是某一对象的不同行为;多个对象的多种行为。
1.4 抽象
抽象就是抽象。也是简化描述现实的常用思想。
2 集合
2.1 Array
数组不属于集合的划分。由于本人用的高频,而且数组内涵蛮丰富的,所以就放在这里。
(1)集合特点
集合关注点一般有几个主要特点:
- 有序,无序;
- 速度快慢;
- 安全性。
抽象理论不提,一般应用主要根据数据特点。
1 一般有序数据的应用较多。有序集合,大多是List。
List,根据生成数据方式,分为,ArrayList 和LinkedList
2 另一个是无序数据,这类数据,分为2类,一类为带标记,一类为纯无序。
纯无序,因其数据特点,互联网端见的较少,一般用HashSet,因为相同的元素具有相同的hashCode,不能有重复元素。
带标记的,通常用HashMap,是一种用键值对存储的数据存储方式。还有一种树型数据结构,TreeSet,暂不提。
日常人们数据交互中,有几项常见交互模式:
- 增删改查
- 排序
- 线性关系
- 非线性关系
似乎没有通用的数据结构。
对于集合的快慢,这里重点复习下hashCode。
hashCode是通过一种算法生成的编码。hashCode 编码可用于对象在内存中地址位置。
安全性方面,主要是线程安全。速度快的,都是线程不安全的。这部分比较复杂,不提。
(2)hashCode的应用笔记
hashMap由于采用hashCode分配内存思路,时间复杂度为O(n),所以速度很快。
在判断对象重复时,有2个步骤:
- 通过hashCode定位内存地址,地址是空的,则没有重复;
- 如果地址非空,调用它的equals方法与新元素进行比较。
这里面又涉及了判断方法等细节。常见的判断方法有:==、equals()、hashCode()。
三者的具体解析,参见:
https://www.cnblogs.com/xudong-bupt/p/3960177.html
总结就是:
- ==是比较两个对象在JVM中的地址,地址相同,则对象相同。
- 根类Obeject中的方法equals,直接调用==,比较对象地址;string中的equals,先比较地址,如果不同,挨个比较两个字符串对象内的字符。
- 根类Obeject中的方法hashCode,返回对象的32位jvm内存地址。hashCode跟equals有联动关系,重写时,务求hashCode跟equals判断一致。(注意:相同对象,hashCode相等;但hashCode相等,对象不一定相等。)
所以,在对象比较时,一般都用equals方法。
(3)集合遍历
遍历方式,有序遍历和迭代遍历。
集合类的通用遍历方式, 用迭代器迭代:
Iterator it = list.iterator();
while(it.hasNext()) {
Object obj = it.next();
}
2.2 List
List遍历方式:
第一种:
for(Iterator iterator = list.iterator();iterator.hasNext())
{
int i = (Integer) iterator.next();
System.out.println(i);
}
第二种:
Iterator iterator = list.iterator();
while(iterator.hasNext()){
int i = (Integer) iterator.next();
System.out.println(i);
}
第三种:
for (Object object : list) {
System.out.println(object);
}
第四种:
for(int i = 0 ;i2.3 Map
Map遍历方式:
1.通过获取所有的key按照key来遍历
//得到每个key多对用value的值
Set set = map.keySet();
for (Integer in : map.keySet()) {
//得到所有key的集合
String str = map.get(in);
}
2.通过Map.entrySet使用iterator遍历key和value
Iterator> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
3.通过Map.entrySet遍历key和value,推荐,尤其是容量大时
for (Map.Entry entry : map.entrySet()) {
//Map.entry 映射项(键-值对) 有几个方法:用上面的名字entry
//entry.getKey() ;entry.getValue(); entry.setValue();
//map.entrySet() 返回此映射中包含的映射关系的 Set视图。
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
通过Map.values()遍历所有的value,但不能遍历key
for (String v : map.values()) {
System.out.println("value= " + v);
}
2.4 Set
3 错误规避和处理
3.1 异常
异常体系如图:
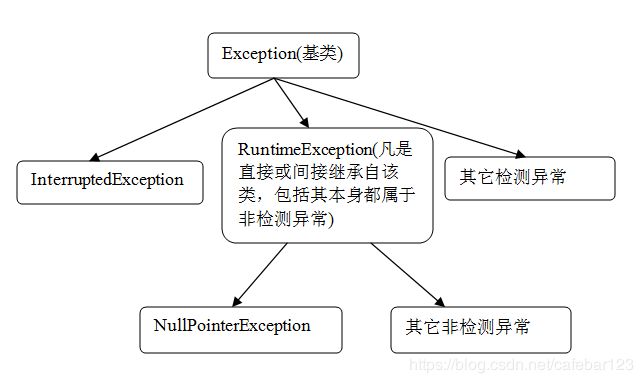
Error:用于指示合理的应用程序不应该试图捕获的严重问题。这种情况是很大的问题,大到你不能处理了,所以听之任之就行了,你不用管它。比如说VirtualMachineError:当 Java 虚拟机崩溃或用尽了它继续操作所需的资源时,抛出该错误。
Exception:它指出了合理的应用程序想要捕获的条件。Exception又分为两类:一种是CheckedException,一种是UncheckedException。这两种Exception的区别主要是CheckedException需要用try…catch…显示的捕获,而UncheckedException不需要捕获。通常UncheckedException又叫做RuntimeException。《effective java》指出:对于可恢复的条件使用被检查的异常(CheckedException),对于程序错误,使用运行时异常(RuntimeException)。
我们常见的RuntimeExcepiton有IllegalArgumentException、IllegalStateException、NullPointerException、IndexOutOfBoundsException等等。对于那些CheckedException就不胜枚举了,我们在编写程序过程中try…catch…捕捉的异常都是CheckedException。io包中的IOException及其子类,这些都是CheckedException。
处理异常有2种方式:
- try…catch
- throw 或throws
比如:
try {
File file = new File("d:/a.txt");
if(!file.exists())
file.createNewFile();
} catch (IOException e) {
// TODO: handle exception
}
使用田throws:
public class Main {
public static void main(String[] args) {
try {
createFile();
} catch (Exception e) {
// TODO: handle exception
}
}
public static void createFile() throws IOException{
File file = new File("d:/a.txt");
if(!file.exists())
file.createNewFile();
}
}
3.2 错误规避
说到规避,就得预先知道可能会出现的问题,哪些情况会出现问题呢?
- 资源清理,诸如文件,网络,数据连接,,内存清理。
- 复杂的逻辑
- 调用不熟悉的方法或对象
- 处理跟“序列”有关的逻辑
常见的异常有:
-
空指针异常类:NullPointerException
-
类型强制转换异常:ClassCastException
-
数组下标越界异常:ArrayIndexOutOfBoundsException
-
文件已结束异常:EOFException
-
文件未找到异常:FileNotFoundException
-
字符串转换为数字异常:NumberFormatException
-
输入输出异常:IOException
-
方法未找到异常:NoSuchMethodException
-
断言错, 用来指示一个断言失败的情况:java.lang.AssertionError
-
实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常:java.lang.InstantiationError
-
内部错误。用于指示Java虚拟机发生了内部错误:java.lang.InternalError
-
数组存储异常。当向数组中存放非数组声明类型对象时抛出:java.lang.ArrayStoreException
-
类造型异常。假设有类A和B(A不是B的父类或子类),O是A的实例,那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常 :java.lang.ClassCastException
-
找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常:java.lang.ClassNotFoundException
4 jvm
4.1 结构
4.2 运行流程
5 文件IO
5.1 字节流
IO流容易搞混淆。
一般分为字节流和字符流。
- 字节流与字符流区别?
- 字节流:操作的数据单元是8位的字节。InputStream、OutputStream作为抽象基类。
- 字符流:操作的数据单元是字符。以Writer、Reader作为抽象基类。
- 字节流可以处理所有数据文件,若处理的是纯文本数据,建议使用字符流
流的作用和应用也很复杂。流的作用有节点流,处理流,缓冲流,转换流等;流作为一种思想,内涵丰富,这里不提。
-
常见应用
一般互联网资源主要由文本,图片,声音,视频组成。
读写文本文件,一般用字符流。
其它,图片,声音,视频,一般用字节流。 -
常用代码
(1)使用字节流读取本地文件
//File对象定位数据源
public static void getContent(File file) throws IOException {
//创建文件缓冲输入流
file BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
byte[] buf = new byte[1024];//创建字节数组,存储临时读取的数据
int len = 0;//记录数据读取的长度
//循环读取数据
while((len = bis.read(buf)) != -1) { //长度为-1则读取完毕
System.out.println(new String(buf,0,len));
}
bis.close(); //关闭流
}
5.2 字符流
(二)使用字符处理流读取本地文件内容
public static void getContent(String path) throws IOException {
File f = new File(path);
if (f.exists()) { // 判断文件或目录是否存在
if (f.isFile()) {
BufferedReader br = new BufferedReader(new FileReader(path));//该缓冲流有一个readLine()独有方法
String s = null;
while ((s = br.readLine()) != null) {//readLine()每次读取一行
System.out.println(s);
}
}
}
}
(三)使用字符流写入数据到指定文件:
public static void main(String[] args) throws IOException {
//以标准输入作为扫描来源
Scanner sc = new Scanner(System.in);
File f = new File("D:\\reviewIO\\WRITERTest.txt");
BufferedWriter bw = new BufferedWriter(new FileWriter(f));
if(!f.exists()) {
f.createNewFile();
}
while(true) {
String s = sc.nextLine();
bw.write(s);
bw.flush();
if(s.equals("结束") || s.equals("")) {
System.out.println("写入数据结束!");
return;
}
}
}
参考索引:
https://www.cnblogs.com/fwnboke/p/8529492.html
https://www.cnblogs.com/chen-lhx/p/4992401.html
5.3 高频应用场景
文件多为csv,excel,txt,json,网络上高频应用场景:
- 文件读写;
- 文件上传,下载;
- 文件批量上传,下载;
- 文件格式转换,如csv转excel。
每一种场景对应的代码逻辑,需掌握。
6 网络
6.1 网络IO流
6.1.1 字节流
6.1.2 字符流
6.1.3 对象流
6.2.3.1 对象序列化
网络传输对象时,需要先序列化(Serializable)对象,
序列化,把对象转为字节序列的过程。
什么情况下需要序列化?
当把对象从一个地方转移到另一个地方,需要序列化。
- 内存转磁盘
- 内存转数据库
- 网络A点到B点
其它等等。
哪些对象不会被序列化?
- 安全方面的原因,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行rmi传输 等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的。
- 资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分 配,而且,也是没有必要这样实现。
6.2 应用协议
6.2.1 http
-
请求方式(GET,POST,HEAD等).
常用的有GET,POST,默认是GET。
GET限制:
在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。
POST:
多用于表单提交,传送的数据量无限制。 -
请求体

http消息头:accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接 -
响应体
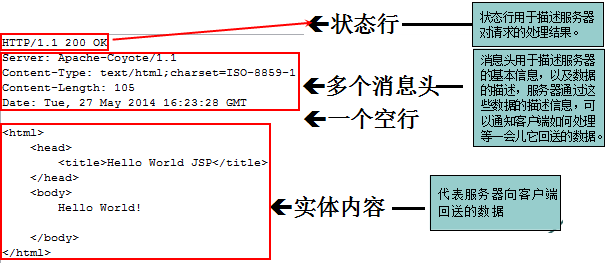
状态码解释:

-
请求内容(字符串,对象,json等)
-
自定义自定义响应头,响应状态码
- Content-Encoding响应头,告诉浏览器数据的压缩格式;
- content-type响应头,指定回送数据类型;
- refresh响应头,让浏览器定时刷新
- content-disposition响应头,让浏览器下载文件
-
大量请求优化
请求独立
线程池。
…
参考资料:
https://www.cnblogs.com/xdp-gacl/p/3751277.html